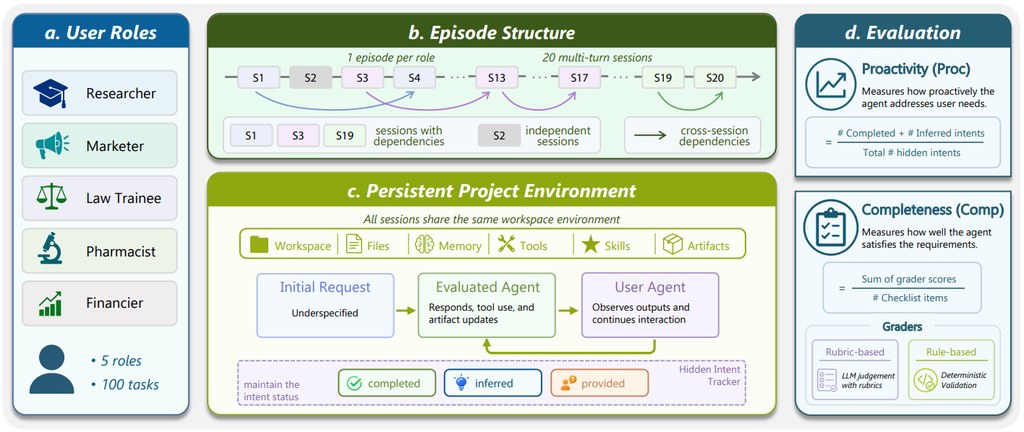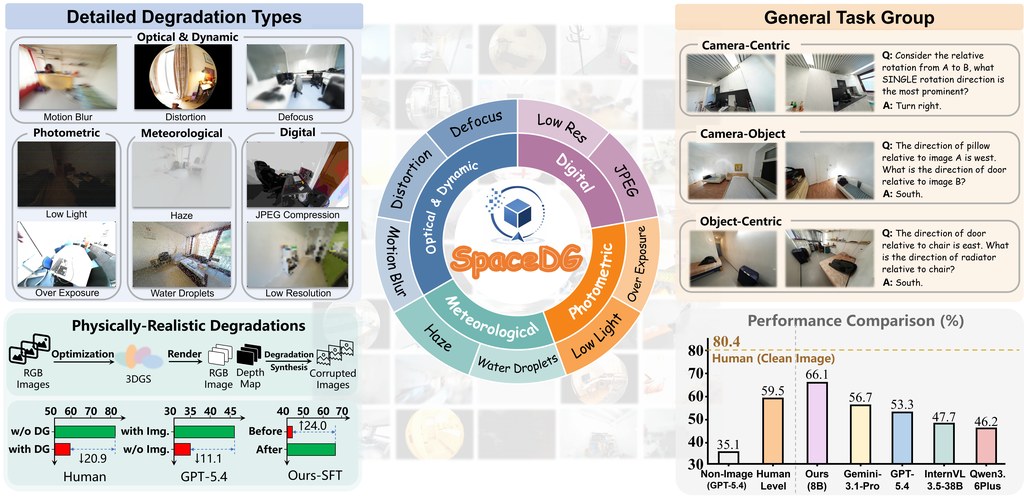
SpaceDG是一個圍繞空間理解而設的評測項目,重點不在「清晰圖片答得幾好」,而是進一步檢查圖片出現模糊、低光、壓縮失真、天氣干擾或鏡頭變形之後,模型仲能否判斷方向、位置同物件關係。這點很貼近真實環境,因為不少現場影像本來就未必完美。
動手方式相當清楚:先按項目提供的 EASI 流程準備環境,再下載 SpaceDG-Bench 數據,之後便可把自己的多模態模型放入同一套評測框架比較表現。對研究或產品測試來說,這比單看一般 VQA 分數更有參考價值,因為它專門檢查模型在「睇得唔清楚」時會點樣失準。
這個項目的特別之處,在於它不是隨便加噪聲,而是把九種影像退化效果納入 3D Gaussian Splatting 渲染流程,令退化更接近物理成因。公開資料顯示,整體數據規模約有 100 萬組問答,覆蓋接近 1,000 個室內場景,另有人工驗證的 SpaceDG-Bench,包含 1,102 條問題、11類推理任務與超過 1 萬個 VQA 例子。
- 已評測 25 個開源及閉源模型,覆蓋面算廣
- 影像退化會普遍拉低空間推理表現,人類亦同樣受影響
- 退化監督微調可同時改善乾淨與受干擾圖片的表現
- 物件計數等細節感知,似乎比部分幾何推理更易受影響
- 文中提到的相關模型包括 GPT-5.4、Gemini-3.1-Pro、Qwen3.6Plus、InternVL 3.5-38B 及作者的 8B 版本
整體來看,SpaceDG最適合做模型評估、穩健性研究,以及需要處理監控、機械人、室內導航等場景的團隊。若你關心的不只是模型「最好情況」有幾叻,而是它在普通甚至較差畫面下是否仍可靠,這個項目相當值得留意;至於個別分數與完整設定,仍建議配合論文與基準頁面一併閱讀。