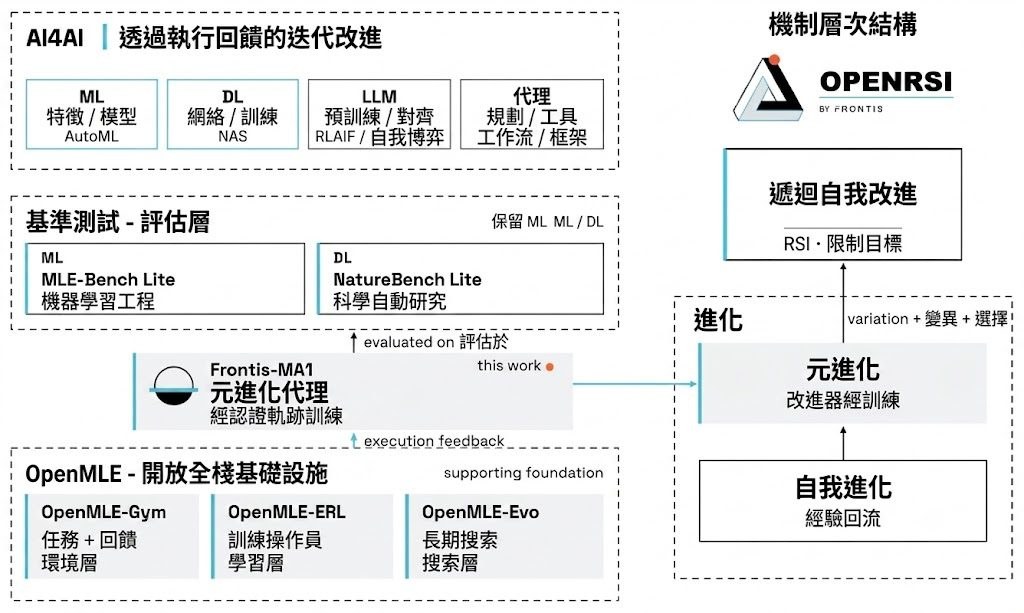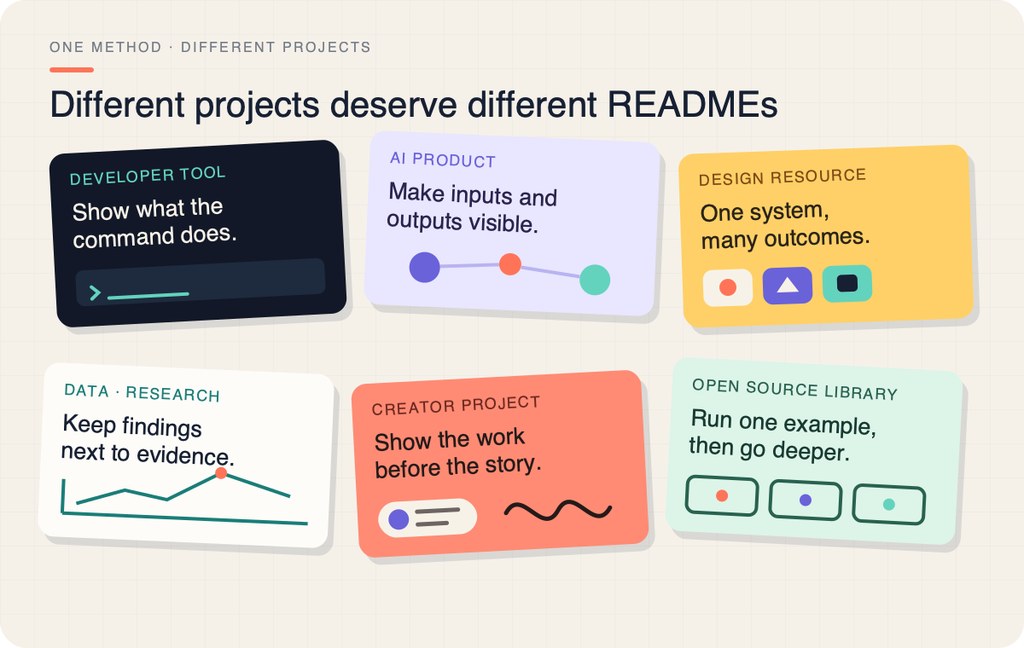
讀者未打開程式前,往往先被 README 決定去留;beautify-github-readme 正正針對呢一步,屬於一個 README 設計與寫作 Skill,重點唔係美化排版,而係令訪客一眼睇明項目做乜、成果去到邊、應該點開始理解。
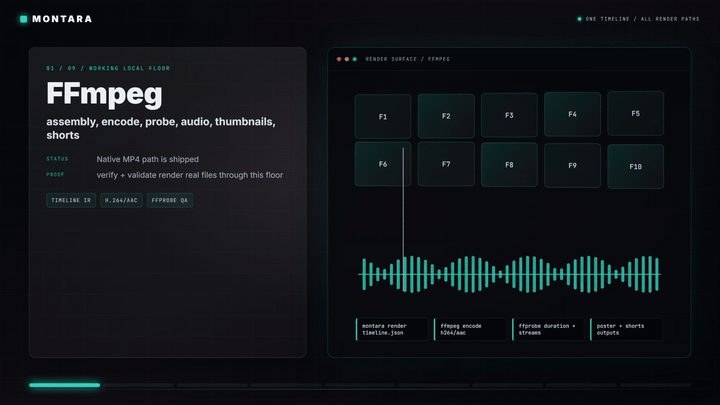
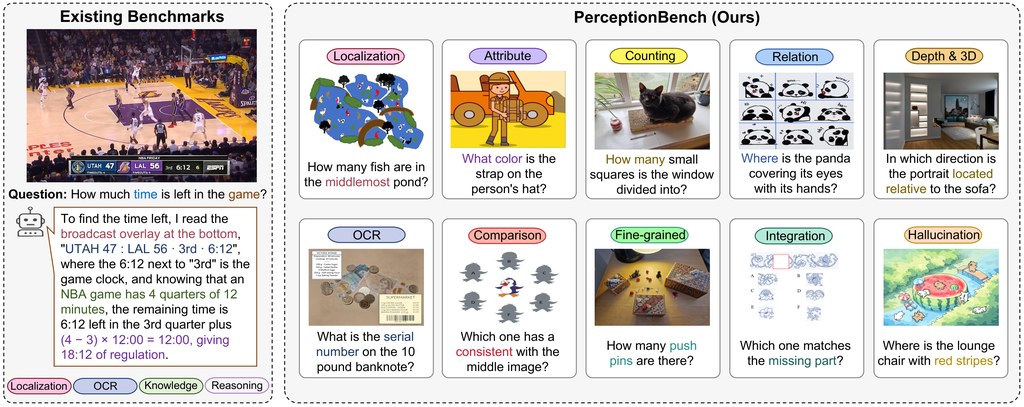
佢同常見 README 範本最大分別,在於唔追求統一風格。呢個方法會由項目自身延伸出字體、配色、構圖同證據展示,連 opening screen 都強調真實輸出,而唔係抽象口號。README 入面列出八個公開儲存庫案例,涵蓋 AI 產品、設計資源、研究與開源庫,證明佢不只是概念展示。
- 重點唔係套版:每個 README hero 都按項目內容重新設計
- 強調真實證據:用實際 UI、圖示、地圖、角色圖或 dashboard 截圖說明能力
- 適合公開展示型項目:尤其係要吸引首次訪客、招募協作者或交代成果脈絡嘅團隊
- 門檻在內容整理:要先有清楚成果、流程同視覺素材,效果先會成立
由 README 內容判斷,部署方式比較似參考方法而唔係可直接安裝嘅工具套件;你應該將佢理解成一套可複用的表達框架,再按自己項目改寫。對獨立開發者、開源維護者同想提升 GitHub 展示面的團隊尤其有幫助,因為佢補強咗「功能存在,但讀者三秒內睇唔明」呢個常見卡位。
限制亦相當明顯:佢未提供量化成效、A/B 測試結果或者自動化生成流程,價值主要來自案例說服力,而唔係可驗證指標。當你已經有一定內容資產,同時希望 README 更似產品入口而不只是說明文件,呢個項目比一般範本更值得參考。