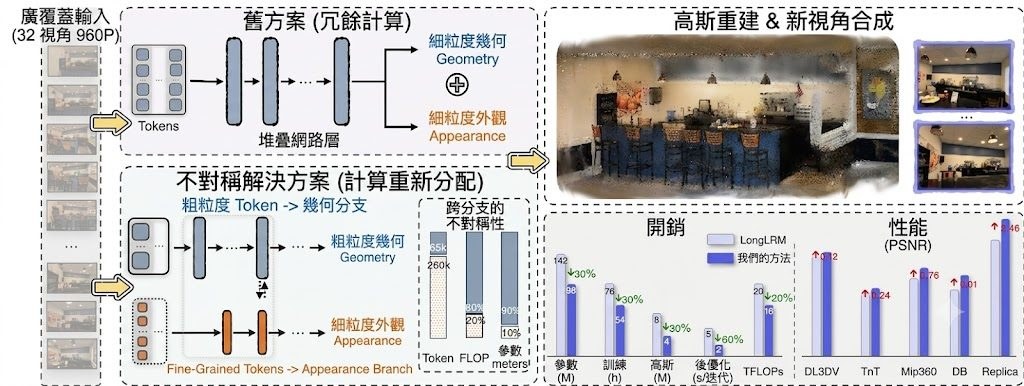
AsySplat 是一個用於 3D Gaussian Splatting 的重建框架,主力解決長序列、廣覆蓋場景做新視角合成時,訓練和推理都太重的問題。現階段這個 GitHub 儲存庫主要提供項目頁、論文連結和資源,程式碼尚未公開,所以要理解它,重點放在方法設計而不是直接安裝部署。
它的做法是把 geometry branch 和 appearance branch 分開,前者處理較粗粒度的資訊,後者用較少參數補回外觀細節,再用 bilateral connections 互相引導。這種取向和一般把所有資訊一起硬塞進去的做法不同,目標是把算力用在更值得的位置。
從現有資料看,AsySplat 比較適合做多視角場景重建、研究級新視角合成,或需要在較大輸入規模下控制訓練成本的團隊。同時使用 sparse attention module,結合 convolution blocks 和 self attention 來減少開銷,並在 32-view 960P 輸入上取得較少參數和較低訓練、推理負擔的結果。
- 類型:3D Gaussian Splatting 重建框架
- 目標:降低 wide-coverage scene modeling 的重複計算
- 特色:幾何與外觀分流處理,再以 bilateral connections 協調
- 效能:在 32-view 960P 設定下,宣稱比之前的 generalizable models 更省參數和開銷
- 相關模型:3D Gaussian Splatting、generalizable 3DGS models、novel view synthesis (NVS)