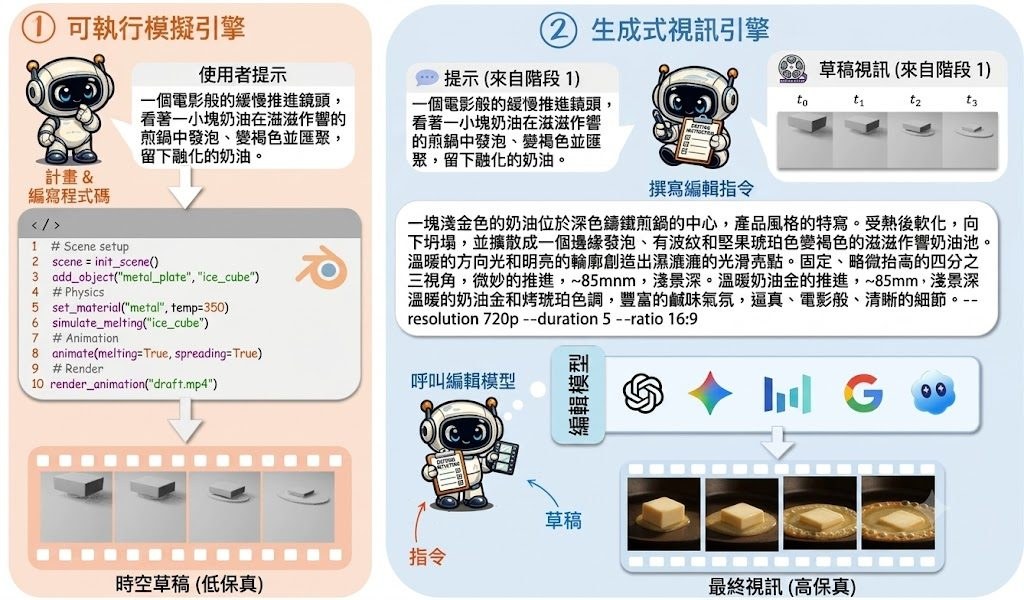
Prompt:
4 NFE PDD on Wan2.1 14B: A joyful child,
with a big smile and arms spread wide,
swings energetically on a rusty old swing set in a sunlit backyard. The swing set, with peeling paint and creaking chains,
contrasts against the vibrant green grass and blooming flowers surrounding it.
The child's laughter echoes as they swing higher and higher,
their feet barely touching the ground at the bottom of each arc.
The scene is captured from a low angle,
emphasizing the height of the swings,
with the sun casting a warm glow over everything.
Medium shot focusing on the child and the swing set.
訓練部分用了 Mixture-of-Students 設計,並以 GAN Control Regularization 處理蒸餾時的 camera drift,目標是同時保住控制能力同長期一致性。現階段公開資訊以示範與技術報告為主,Code 同 HuggingFace 尚未釋出;不過單看定位,Wonder已經清楚指向一類更接近「可互動世界」而唔係「一次性影片生成」的世界模型方向。
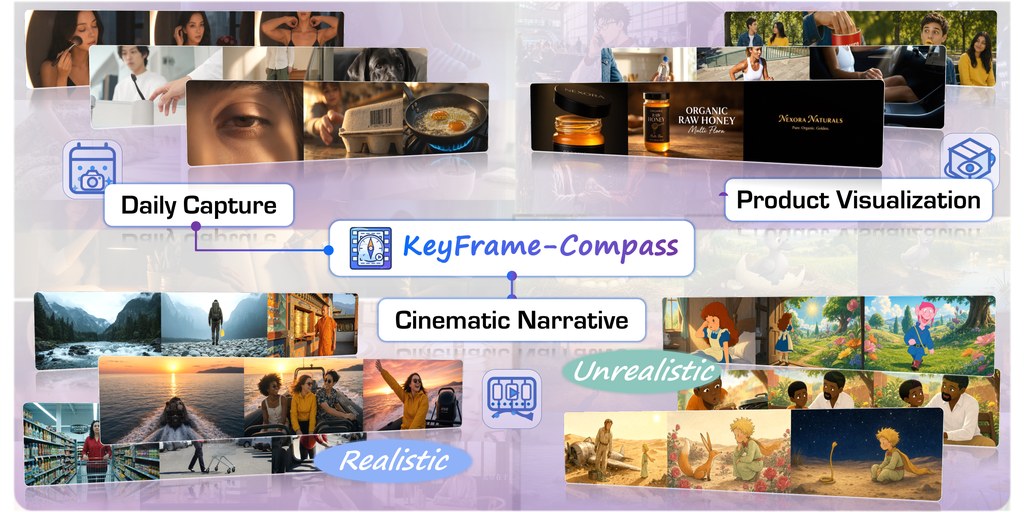
KeyFrame-Compass 是一個用來評測 keyframe-conditioned video generation 的基準項目,重點在於檢查模型能否同時跟住文字提示同一組按順序排列的 keyframes 生成影片。對做影片生成的人來說,這類測試最有價值的地方,是它不只看成片好不好看,還會追問畫面有沒有真係按要求出現、順序有沒有走樣。
這個項目把評測拆成兩層:一層看 keyframe execution,包括關鍵畫面存在、視覺還原、時間順序、定位、持續性同回應唯一性;另一層看 overall video quality,會用 evidence-grounded MLLM(Multimodal Large Language Model, MLLM)判斷,加上專門的感知模型去量度視覺質素、時間連貫性、指令遵從同音訊表現。這種分法比單純比對整體分數更清楚,因為它能分辨出模型係「畫得靚」定「跟得準」。