這是一個由復旦大學(上海多模態具身 AI 重點實驗室)與騰訊 WeChat Vision 聯合發佈的研究項目(屬於數據集+模型基準組合),同時收錄於 ECCV 2026。針對 WordArt-oriented scene TExt Recognition(WATER)這項任務,原有 STR 數據集與方法普遍圍繞「規則場景文字」與「固定模板輸入」建構,難以應對 WordArt 高度自訂的字體、紋理與版面,因此表現受限。WATER 從兩端突破:數據方面構建 2M 規模合成數據集 WATER-S,模型方面提出支援任意形狀輸入的 STR 基線 WATERec。
WATER-S 數據集設計包含兩個互補子集:WATER-T(1M)由 SynthWordArt 渲染引擎透過 11,250 款藝術字體生成,提供高可控的精準合成樣本;WATER-Z(1M)則結合 Qwen3-VL 提示詞挖掘與 Z-Image 影像合成,覆蓋更真實且多元的場景。再搭配 WATER-R(3.2M,整理自 Union14M-L、WordArt、WAS-R 並去重)作為真實訓練集,整體數據規模較既有藝術文字數據提升數百倍。
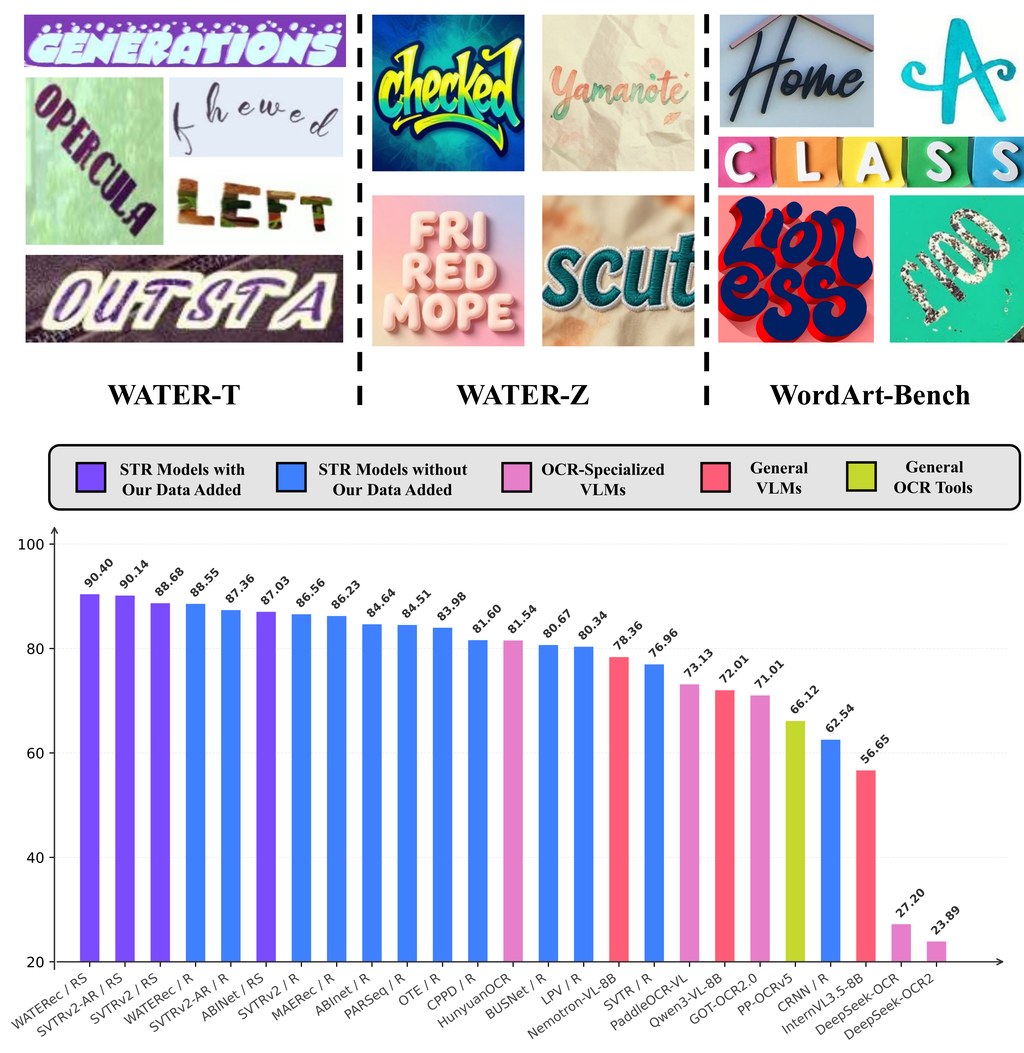
WATERec 模型架構採用類似 NaViT 的編碼器搭配 RoPE,支援任意形狀輸入,再以自回歸解碼器處理複雜版面,從結構上打破固定模板 STR 的瓶頸。在 WordArt-Bench 上以 90.40% 準確率成為首個突破 90% 的結果,大幅超越 HunyuanOCR(81.54%)及其他通用或 OCR 專用視覺語言模型。
使用方法需配合外部資源:WATERec 訓練與推理程式碼位於 OpenOCR-WATERec 倉庫;模型權重、數據集(包含 WordArt-Bench)、273K 條 WATER-Z 提示詞模板與 112K 款藝術字體皆託管於 HuggingFace。複製本倉庫後,可透過 SynthWordArt/ 目錄取得 WATER-T 渲染流程,prompts/ 目錄提供 caption_mining.py 與 fewshot_expansion.py 兩階段提示詞挖掘,Z-Image/gen_zimage.py 支援多 GPU 並行生成,eval_vlm/ 則整合 Qwen3-VL-8B、InternVL3.5-8B、GOT-OCR2.0、DeepSeek-OCR-2、PaddleOCR-VL、PP-OCRv5、HunyuanOCR、Nemotron-VL-8B 等基線評測腳本。
重點摘要:
– 復旦大學與騰訊 WeChat Vision 團隊合作,獲 ECCV 2026 收錄
– WATER-S 含 WATER-T(字體渲染)與 WATER-Z(VLM + 影像合成)兩條合成路徑
– WATERec 以任意形狀編碼器 + 自回歸解碼器突破固定模板限制
– WordArt-Bench 90.40% 為首次突破九成,超越 HunyuanOCR 等專用 VLM
– 所有模型、數據、字體與提示詞均開源於 HuggingFace
從評估對照來看,不論是通用 VLM、OCR 專用 VLM 或一般 OCR 工具,在 WordArt-Bench 上皆明顯落後於 WATERec,反映藝術文字仍是當前多模態模型的弱項。對從事海報辨識、品牌素材處理、廣告設計自動化,以及需要處理高度風格化文字的團隊而言,這套數據+模型組合是目前少數針對該場景強化的開源方案。