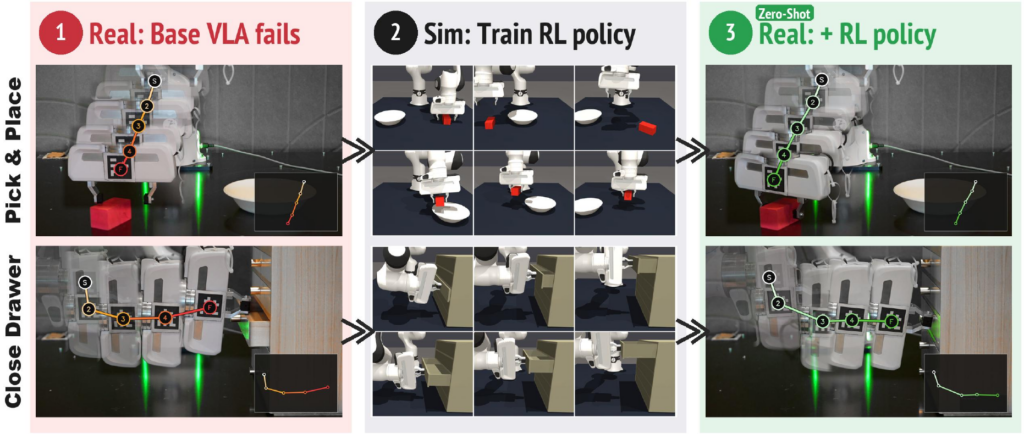
這是一個機械人操作模型,名為 Qwen-RobotManip,屬於建基於 Qwen-VL 的 Vision-Language-Action foundation model。它主要處理機械臂操作資料分散、昂貴而且難以統一訓練的問題,目標是讓模型在未見過的任務、場景與機械平台上仍能保持可用表現。
它的核心做法,是把操作學習中的表徵、動作與行為三個層面放進同一套 alignment framework。研究團隊同時建立 human-to-robot synthesis pipeline,將第一身手部示範影片轉成 15 個平台可用的 robot trajectories,再配合多來源資料整理流程,整合真實機械人、合成資料與人類示範影片,形成約 38,100 小時 pretraining corpus。
和常見只集中單一機械平台、單一資料來源,或偏重分佈內表現的做法相比,Qwen-RobotManip 更著重 genuine generalization。評估上亦沒有停留在一般 benchmark,而是加入多個 OOD 設定,包括 RoboCasa365、LIBERO-Plus、EBench、RoboTwin-Clean2Rand、RoboTwin-IF 與 RoboTwin-XE,用來檢查指令跟隨、擾動穩健性、錯誤恢復,以及 cross-embodiment knowledge transfer。
重點可整理為:
– 建基於 Qwen-VL,面向 robotic manipulation 的通用基礎模型
– 以 unified alignment framework 整合 heterogeneous manipulation data
– 使用 human-to-robot synthesis pipeline,覆蓋 15 個機械平台
– 只依靠 open-source robotic manipulation datasets 與 human demonstration videos,未提及私有資料收集
– 在多個 OOD 評測中優於過往 state-of-the-art models,包括 π0.5,並在 RoboChallenge 排名第一
這個項目較適合關注 robotic manipulation、VLA、跨機械平台遷移與機械人資料擴展流程的人閱讀。現有資料顯示,它不單是再加大訓練規模,而是先解決資料對齊問題,令擴充規模之後的訓練信號不會互相衝突,這也是它能在真實機械平台驗證泛化能力的關鍵。