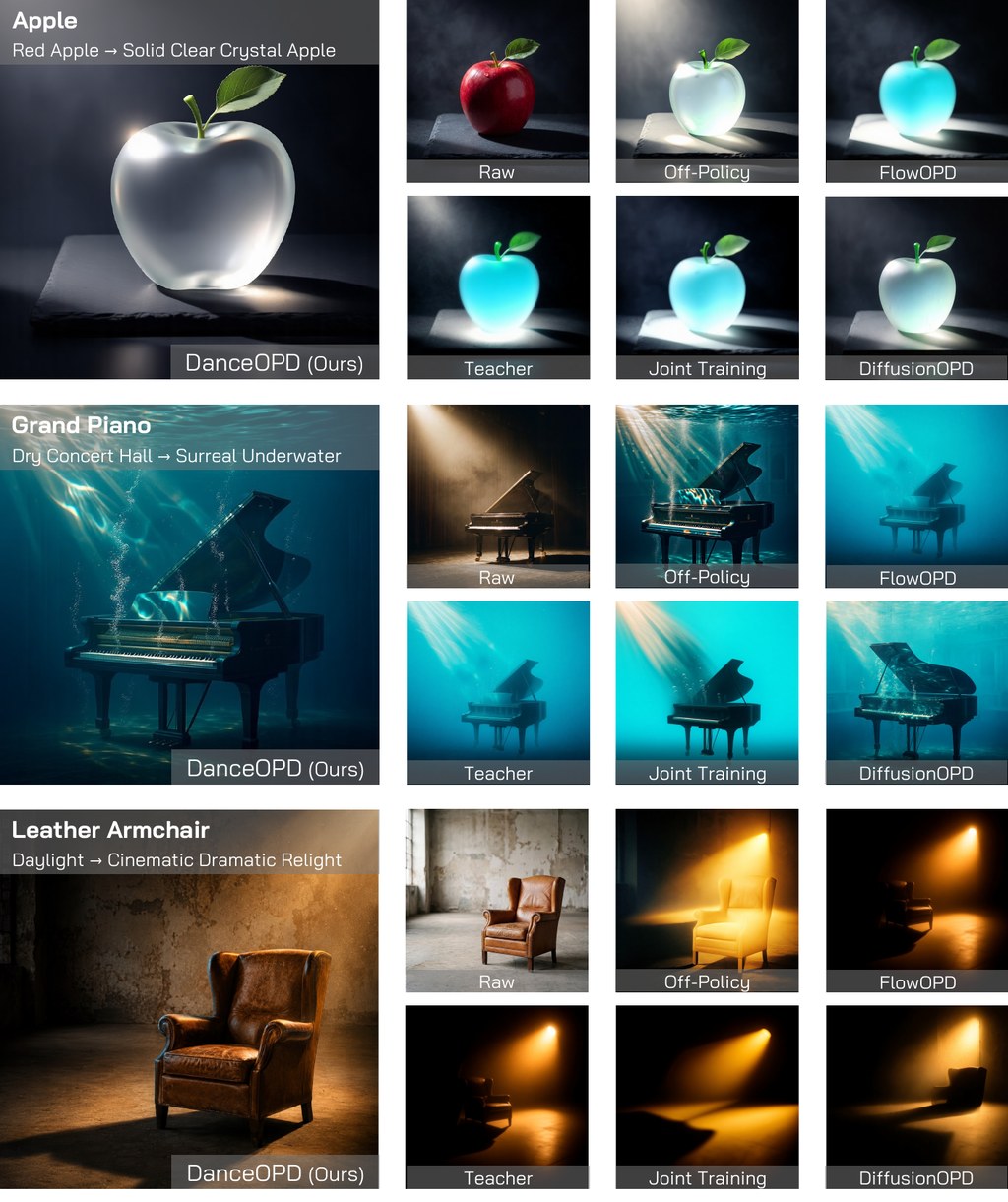
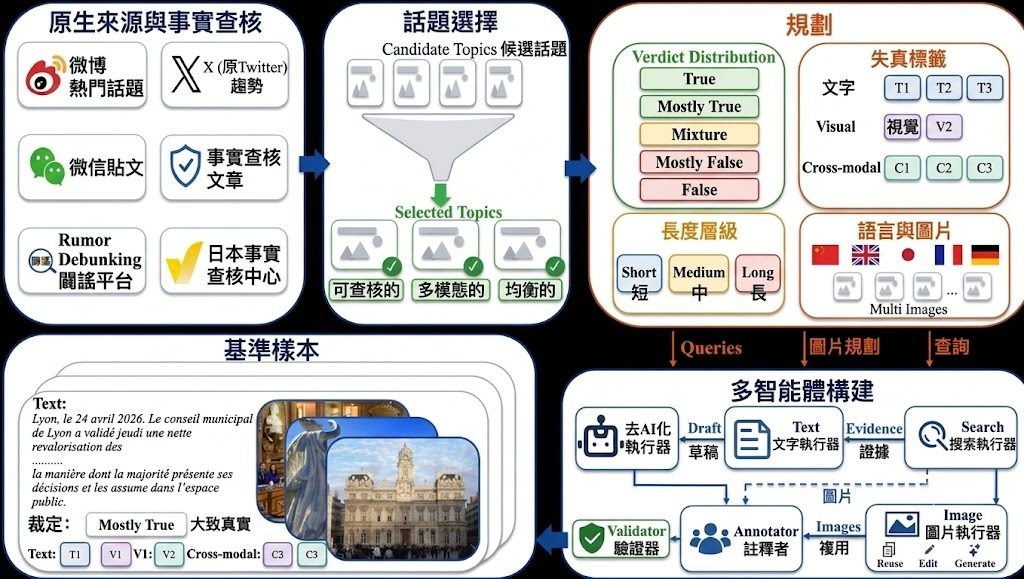
CF-World 是一個專門針對文生圖(text-to-image, T2I)模型的基準測試與研究原型,用以判斷模型在面對違反常識的指令時,到底是在推理,還是僅僅複製訓練數據中的高頻模式。現有的 T2I 模型在日常語境下表現出色,但只要物理法則被刻意改寫,例如要求它們生成「重力反轉」或「光線反向折射」的畫面,便會出現明顯崩潰。CF-World 採用三層遞進設計來暴露這種落差:L1 為事實生成,要求模型按真實世界知識作畫;L2 為顯式反事實(Explicit Counterfactual),同時提供反事實前提與指定的視覺結果,測試模型能否依指令調整;L3 為隱式反事實(Implicit Counterfactual),只給出反事實條件,要求模型自行推導應有的視覺呈現,從而考驗真正的因果推演能力。
為了量化這種落差,項目引入兩項指標:PRR(Prior Resistance Rate,先驗抵抗率)衡量模型擺脫既定視覺慣性的能力,RRR(Reasoning Retention Rate,推理保留率)則檢驗模型在多步驟指令下能否維持邏輯連貫性。儲存庫還包含因果解耦(Causal Decoupling)、屬性解耦(Attribute Decoupling)與去範式化(De-nominalization, De-norm)三條專門評測線,協助研究者區分失敗究竟源自因果變量無法分離,還是源自語言先驗的「概念鎖定」。
在評估對象方面,CF-World 涵蓋 FLUX.2-dev、Qwen-image、Nano Banana 等近期模型,結果顯示 L1 表現良好的模型在 L3 場景中普遍出現一致性急劇下降,說明高維統計先驗正在壓制真正的因果推理。代碼庫結構清晰:eval_questions 收錄預先生成的評測題目,prompt 存放基礎提示詞與反事實規則,scripts 則涵蓋題目生成及基於 VLM 的自動評分(支援 Gemini 與 Qwen3-VL)。對從事多模態模型評測、視覺推理研究或關心模型安全邊界的團隊而言,這個基準提供了一個可重現且分層細緻的測試平台,有助於定位「模型究竟卡在哪個環節」。
📂 Repository Structure
The repository is organized into prompts, pre-generated evaluation questions, and execution scripts:
├── eval_questions/ # Pre-generated evaluation questions (categorized by discipline)
│ ├── physics/ # Physics sub-disciplines (Astronomy, Mechanics, etc.)
│ └── ...
├── prompt/ # Raw base prompts and counterfactual rules
│ ├── physics/
│ └── ...
└── scripts/ # Core execution scripts
├── generate_eval/ # Scripts to generate evaluation questions
│ ├── gemini.py # Generates standard CF-World questions via Gemini
│ └── rule_decouple.py # Generates questions for the Causal Decoupling experiment
└── score/ # Automated VLM-based scoring scripts
├── gemini.py # Standard multi-dimensional scoring using Gemini
├── qwen3vl-235b.py# Standard multi-dimensional scoring using Qwen3-VL
├── rule_decouple.py # Scoring for the Causal Decoupling experiment
├── attribute_decouple.py # Scoring for the Attribute Decoupling experiment
└── denorm.py # Scoring for the De-nominalization (De-norm) experiment
GitHub: https://github.com/jylei16/CF-World
項目主頁: https://jylei16.github.io/CF-World.github.io/
Paper: https://arxiv.org/pdf/2606.24548