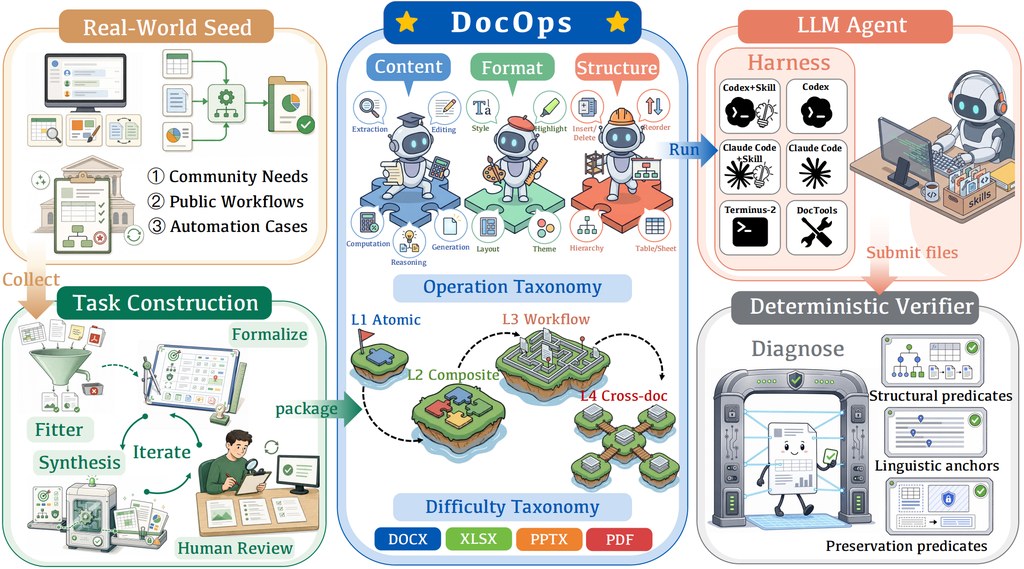
畫面睇得明,不等於身體識得郁得啱。HumanCLAW 把 Vision-Language Models(VLMs)放進一個閉環人形行動測試環境,集中量度模型每個瞬間應該做哪個動作,而不是把失敗全數歸咎於低層馬達控制。它屬於評測框架兼基準測試項目,處理的是 VLM 在具身場景中的行動決策能力,到底有沒有足夠「身體感」去完成找路、移動與互動。
呢個設計最值得留意的地方,是它把 action decision-making 與 low-level motor execution 分開。每 0.5 秒,凍結的 VLM 只需要根據第一身視角、指令、技能列表與歷史內容,提出一個 atomic whole-body skill;後面的 verifier、motion generator 同 half-physics simulator 再負責驗證、安全過濾與連續動作執行,令接觸、碰撞、重力等物理後果仍然保留下來,但平衡失誤與動作追蹤誤差會被盡量排除。
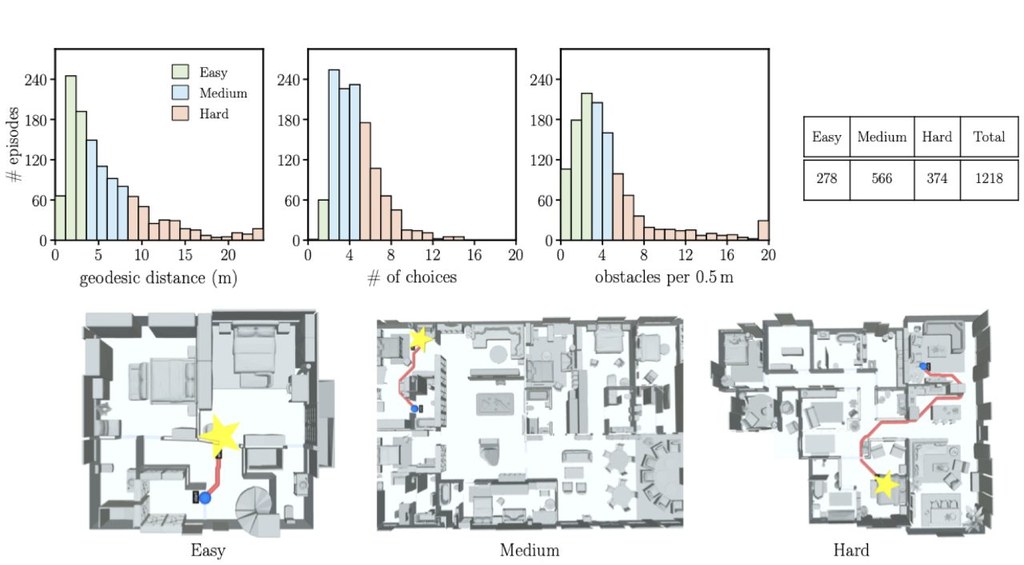
HumanCLAW-Bench 則在這個框架之上提供 1,218 個長時程 find–navigate–interact episodes,覆蓋 41 個室內場景。數字相當直接:九個最先進 VLM 全部未能解決這套基準,最佳成績只有 16.8% success rate,反映問題不在單次辨識,而在模型持續追蹤自身位置、判斷是否到達目標,以及理解自己有沒有撞上環境。
- 把高層決策同低層動作分離,較易睇清 VLM 真正弱點
- 保留真實物理後果,唔會因為純符號化環境而高估能力
- HumanCLAW-Bench 著重長時程、第一身視角、連續互動任務
- 目前公開資訊顯示程式碼與 benchmark 仍在準備釋出
對研究 embodied AI、Computer-use agents 延伸方向、VLM 評測方法的人來說,呢個項目有參考價值,尤其適合用來檢查模型是否具備 closed-loop spatial action intelligence,而不只是識描述畫面。現階段較大的限制也很清楚:GitHub 儲存庫尚未正式放出 harness、motion generator weights、half-physics simulation environment 與完整評測內容,暫時主要仍是透過 project page、paper 同 leaderboard 理解方法與結果。