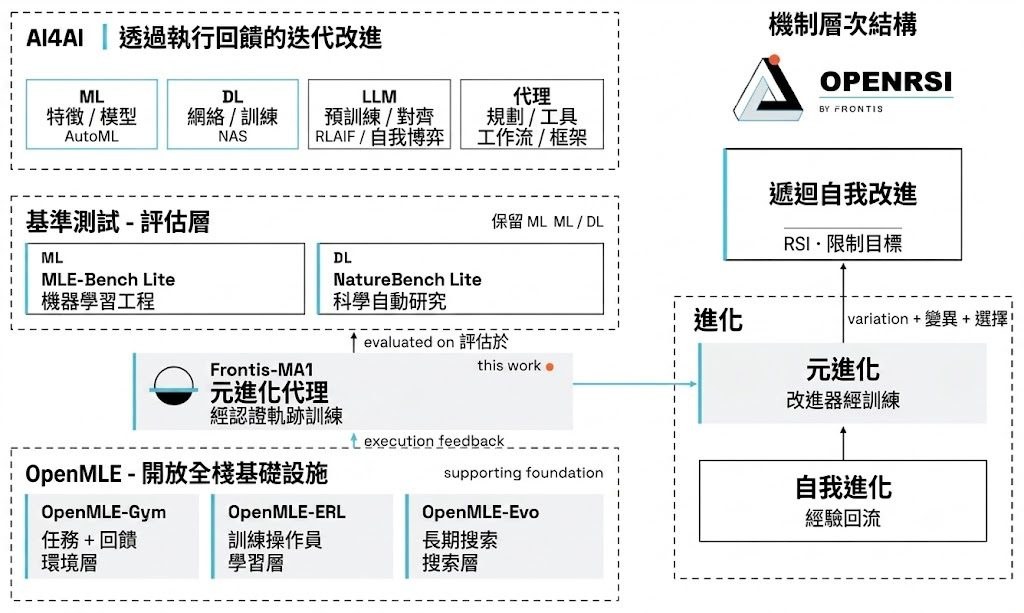
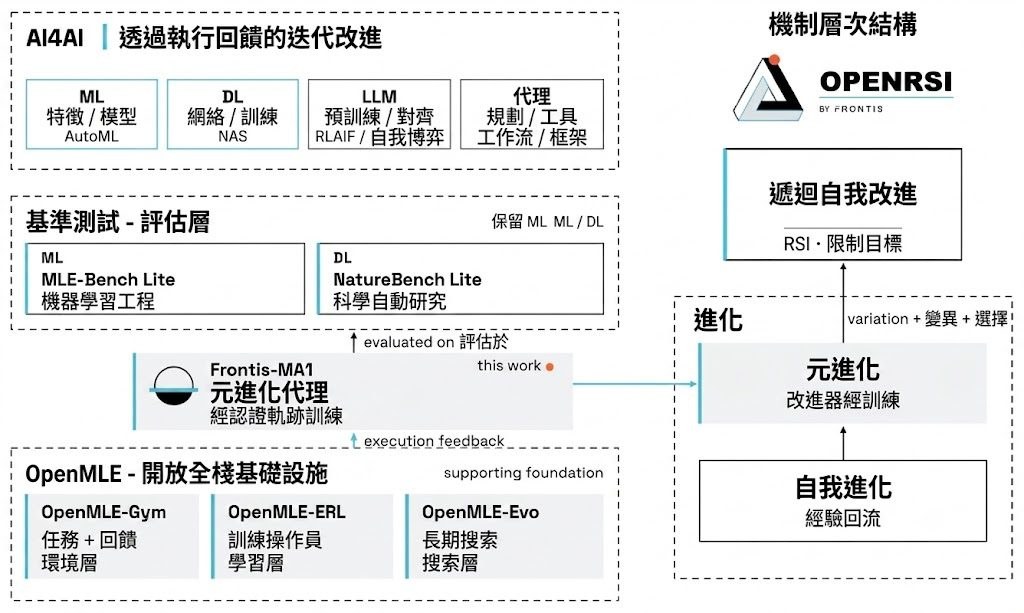
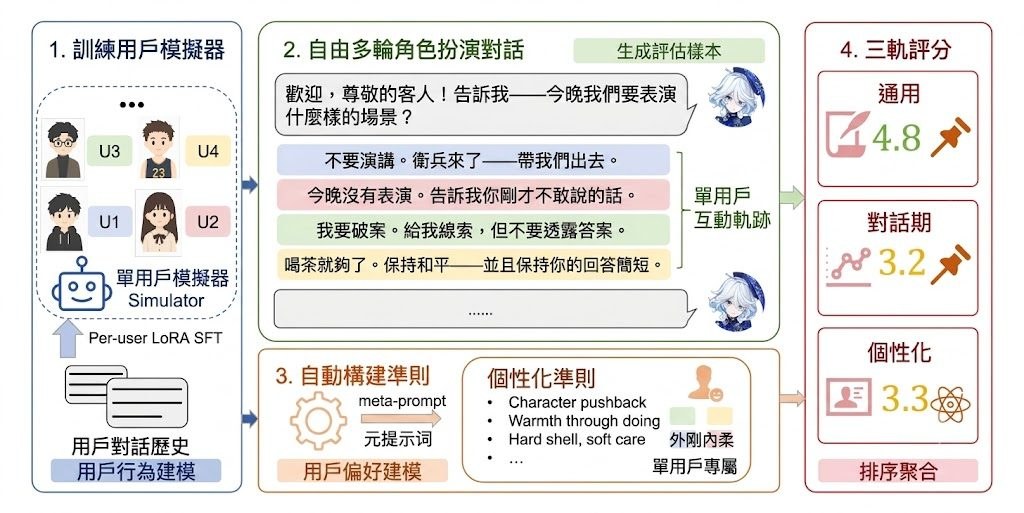
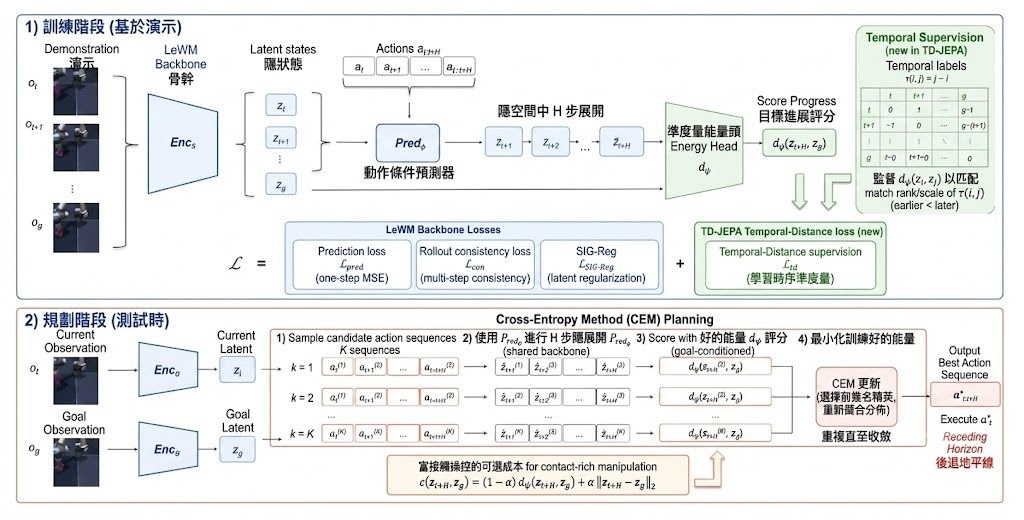
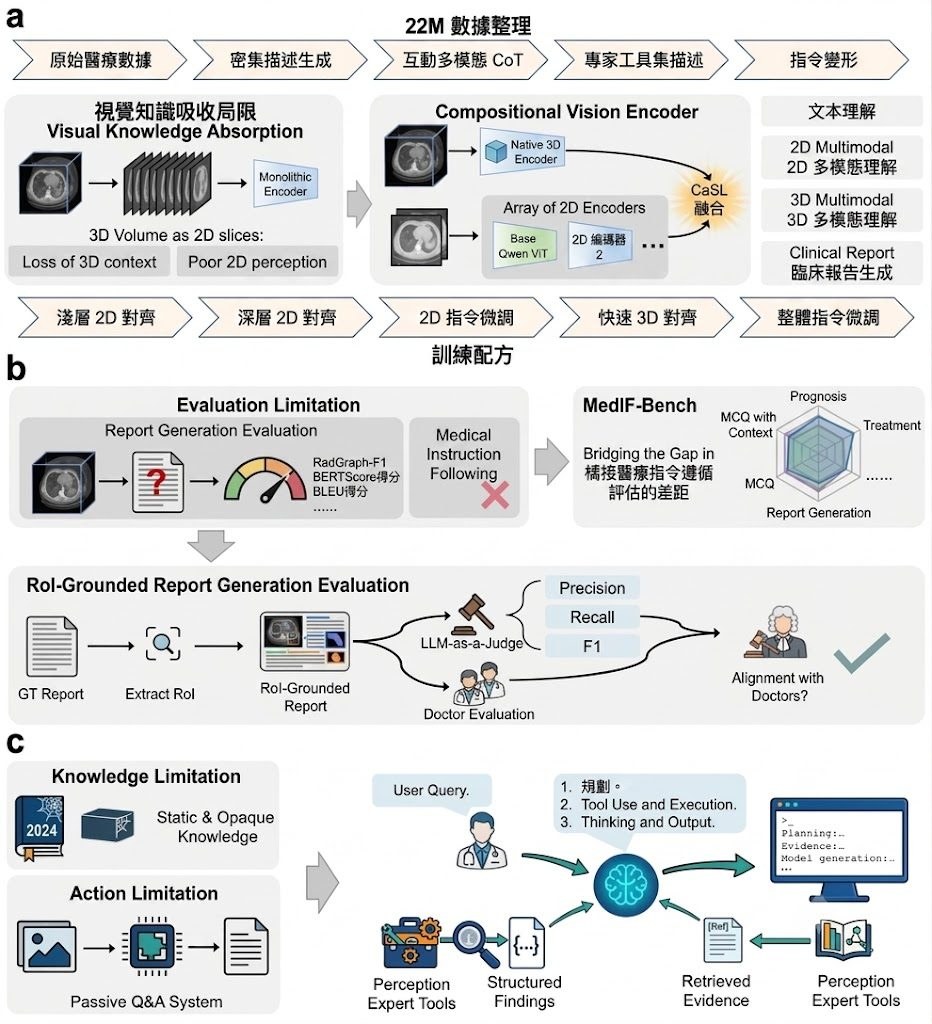
見到模型會畫線、裁圖、標記物件,很多人自然會當它「有睇過先答」。See2Think屬於基準測試加診斷框架,焦點不是只看最後答啱幾多,而是拆開檢查中間視覺狀態有冇被真正用到、渲染是否忠實,以及後續推理有冇因此改變,這點對多模態模型(Multimodal Models)尤其關鍵。
它的核心設計分成兩部分:See2ThinkBench 收錄 1,200 條 visually dependent 問題,涵蓋 2D structured reasoning、3D scene reasoning 同 real-world visual reasoning;另一部分是 Visual Action-of-Thought(VAoT)流程,會把文字思路、structured visual actions、rendered states 同之後的推理串連起來。這種做法比單看 final-answer accuracy 更有診斷力,因為可以分辨模型是在「做出圖像」還是在「依賴圖像」。
同類研究常停留在結果分數,See2Think較著重受控比較。它設有 CoT、NoRender、Full、WrongRender 等 matched comparisons,又會檢查 render-benefit、corrupted-feedback sensitivity,以及 process judging 裡的 relevance、faithfulness、uptake,換句話說,不只問模型答得對不對,還會問中間那一步是否相關、是否被正確執行、以及模型有沒有吸收回來的視覺資訊。
- 適合研究多模態推理、agent 行為分析、視覺工具鏈設計的團隊
- 強項在於把「中間圖像是否有用」變成可觀察、可干預的測試問題
- 覆蓋圖表、幾何、符號結構、3D 空間關係到真實圖片場景
- GitHub 已公開程式與 quick start 線索,但論文仍標示為 coming soon,細部實驗設定仍要以後續正式文件核對
對模型評估要求較細緻的情境,這個項目很有參考價值;想拿它直接當應用工具就未必是同一回事。它更像研究型基礎設施,幫團隊判斷多模態系統的推理鏈是否可信,而不是單純追求更高答題分數。