
現有 spatial VLM 往往用單一路線回答空間問題,不是純文字 chain-of-thought,就是直接靠感知結果輸出答案;作者認為這種固定範式難以同時處理語意推理與精確幾何判斷。SR-REAL 提出的做法,是把空間推理分成 Language-Only Reasoning(LOR)與 Detect-Then-Reason(DTR)兩條互補路徑,前者逐步文字推理,後者先找 3D 幾何線索,再做明確幾何推斷。
這個項目屬於框架加訓練流程實作,核心是強化 spatial vision-language models 在複雜空間問答中的判斷能力。它不是單純新增資料集,而是從 cold-start supervised fine-tuning 到 reinforcement learning(RL)都重新安排,並加入 region-to-3D 介面,令模型可把 region tokens 連到 3D 座標、中心點或 bounding boxes。
SR-REAL 重點集中在資料準備與訓練前處理。流程上會先用 SPAR、EmbodiedScan 等來源整理物件對應與 3D 座標,再由 expert.py 生成推理鏈,配合 qwen3.py 抽取物件名稱,最後組成 DTR 指令微調資料;若不想自行重建,也可直接下載作者已整理好的 Hugging Face 數據。這表示它較適合有 Python、資料處理及多模態訓練基礎的研究團隊,而不是即裝即用的終端工具。
和同類做法相比,SR-REAL 不假設所有空間問題都應該用同一種 reasoning path。作者的取向很清楚:語意關係適合 LOR,涉及明確位置、距離、中心點、框選區域的題目則交給 DTR;代價是整個資料構建與訓練流程更複雜,對 grounding 資料品質亦更敏感。
- 重點不在單一模型結構,而在 LOR + DTR 雙路徑推理設計
- DTR 會先處理 region tokens 與 3D 幾何線索,再做空間判斷
- 訓練分為 cold-start supervised fine-tuning 與 reinforcement learning(RL)兩段
- 已提及 accuracy、format、detection rewards,顯示評測不只看答對與否,也看輸出格式及幾何對齊
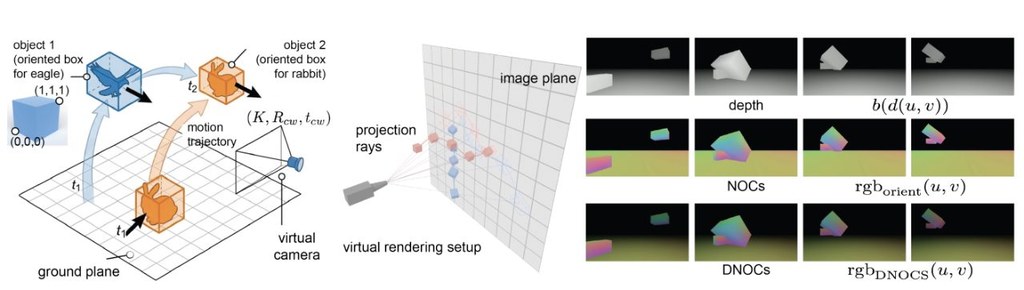
- 相關模型與資料來源包括 spatial VLM、SR-3D、Qwen3、SPAR、EmbodiedScan、SpatialRGPT、Omni3D、CA1M、OmniNOCS
SR-REAL 在多個 spatial benchmarks 有明顯提升,並強調單一 RL-trained model 可同時支援兩條路徑,且不用 per-task tuning 也能跨資料集泛化。不過儲存庫片段未完整列出詳細分數與對照表,因此較穩妥的判斷是:這是一個研究味很重、方法論清晰的項目,適合關注 spatial reasoning、3D grounding、multimodal instruction tuning 的團隊拿來重現與延伸。






![AdaVoMP short video [ICML 26]](https://infernews.com/blog/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2Fa5sXqAWlbEs%2F0.jpg)