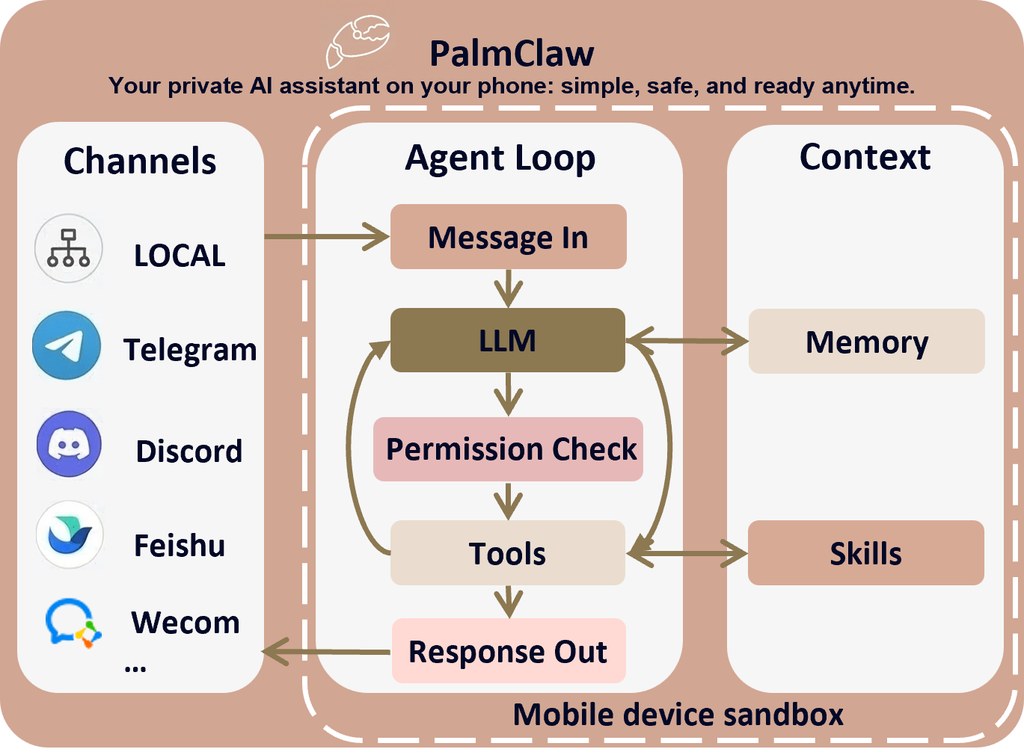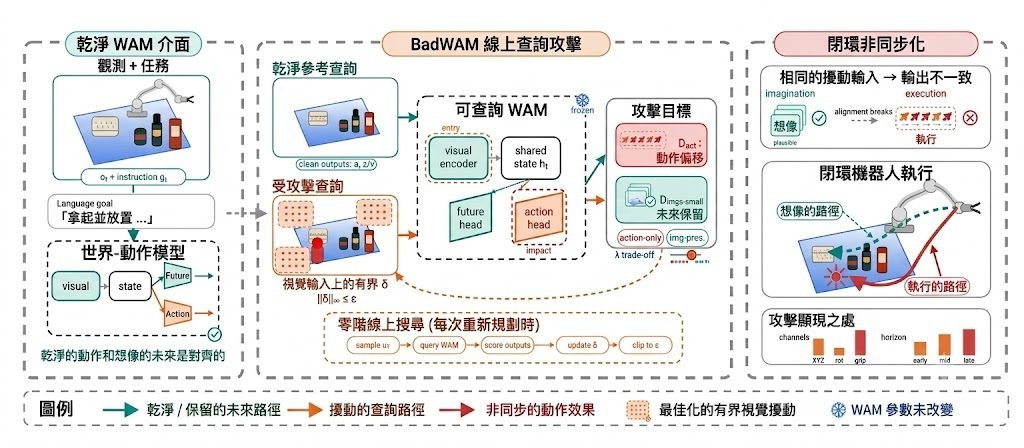
當一個 World-Action Models(WAMs)睇落仍然能夠預測合理未來,但實際控制已經被悄悄帶偏,問題就唔再只是準確率高低。BadWAM 屬於研究型安全測試框架,集中模擬 World-Action Drift Attacks,用細微視覺擾動去拆開「想像」同「行動」之間原本應該對齊的部分。
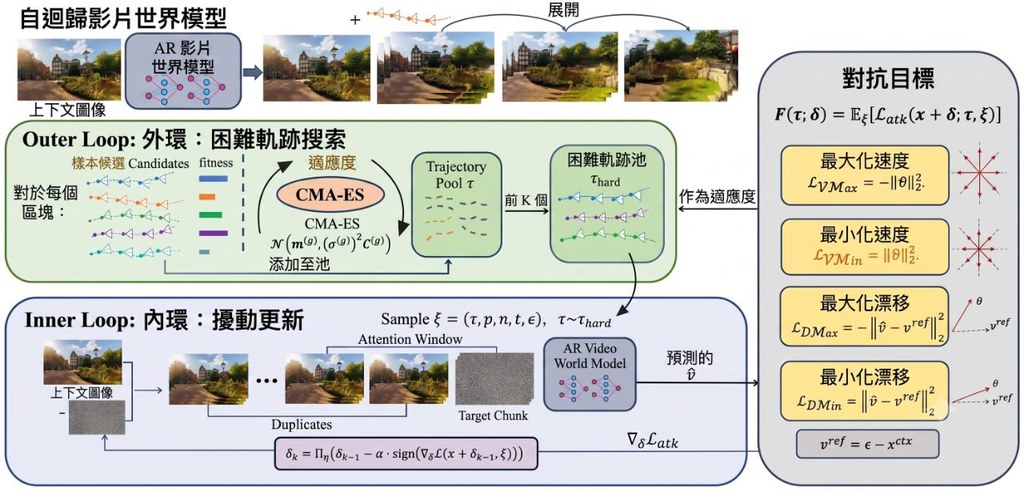
呢個項目的價值,在於它唔係單純證明模型會失手,而係指出一種更難察覺的失效方式:未來預測仍然似樣,行動卻已經朝向任務失敗。相比一般只睇輸出有冇偏移的對抗攻擊做法,BadWAM更貼近 WAM 的結構特性,分成 Action-only Adversarial Attack 同 Imagination-preserving Adversarial Attack 兩條路線,後者尤其針對「表面正常、實際出錯」的情況。
重點可先睇幾項:
– 支援 query-based 攻擊,重點在凍結的 WAM 上做線上搜尋
– 提供 LIBERO closed-loop attack evaluation,唔只停留在單步分析
– 包含 matched-strength stealth analysis 同 ablation experiments
– 內附 statistics export 與 plotting utilities,方便整理結果
從部署角度看,儲存庫提供的是研究代碼而唔係開箱即用套件,基礎環境指向 Python 3.10+,並建基於 FastWAM。README 亦講明未附 model checkpoints、LIBERO data、dataset statistics、RoboTwin assets 同實驗輸出,所以要重現結果,仍然要自行補齊相關資源與依賴。
現有公開結果已經說明這個框架唔只係概念展示。在 LIBERO closed-loop 測試中,action-only WAM 成功率由 96.5% 跌到 43.1%,joint WAM 亦由 98.1% 跌到 61.5%。受益最大的會係做機械人控制、WAM 安全、對抗魯棒性測試的研究團隊;對一般應用開發者來說,它未必直接幫你部署產品,但很適合作為檢查模型是否「睇落可靠、其實已偏航」的驗證工具。