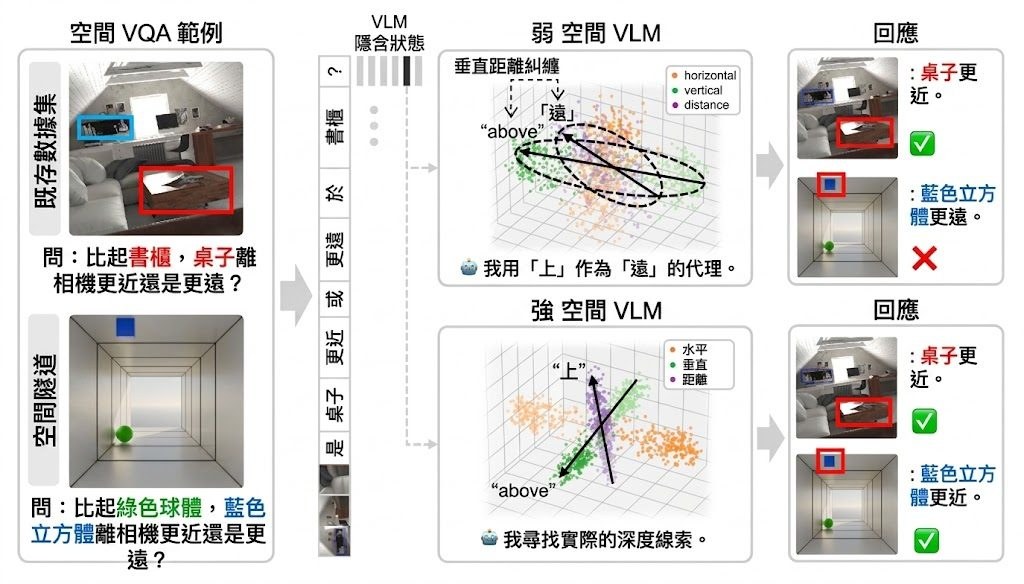
YoCausal 是一個用來評測 Video Diffusion Models(VDMs)嘅項目,核心問題好直接:模型見到一段影片時,究竟係理解事件因果,定只係記住畫面常見嘅時間模式。呢個項目用正播同倒播影片比較 denoising loss,若模型對正向影片分數更合理,代表它較能分辨自然因果關係。
它提出兩個關鍵指標:Reverse Surprise Index(RSI)同 Causality Cognition Index(CCI)。RSI 主要睇模型有幾多次偏好正向時間流;CCI 再進一步將「知道時間方向」同「真正理解因果」分開,避免只靠時間線索就被誤判為懂因果。
使用呢個項目時,重點唔係訓練新模型,而係替現有模型寫 evaluator,然後用指定資料集跑評測。項目亦提供 leaderboard 提交格式,會要求模型名稱、版本或 checkpoint、模型大小,以及 evaluation result JSON 檔案;若改動過預設設定或 preprocessing protocol,也要一併說明。

- 用真實世界影片倒播做 counterfactual,比純合成資料更貼近常見場景
- 以 denoising loss 比較正播與倒播,測法清楚而且可擴充
- RSI 測時間方向感知,CCI 嘗試拆出更接近因果理解嘅部分
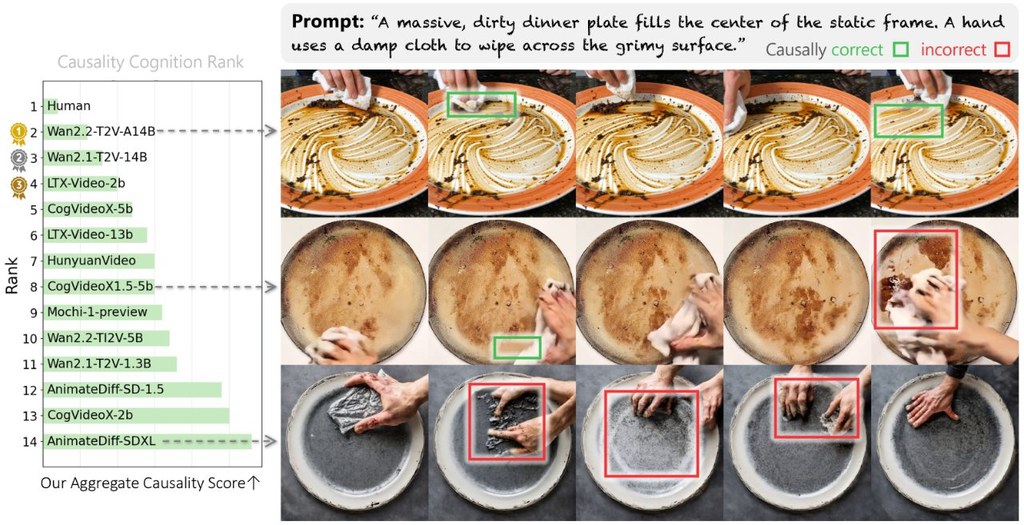
- 已評測 13 個 state-of-the-art VDMs,結果顯示時間感知不等於因果理解
- 文件提到 Wan Model Evaluation(DiffSynth-Studio),亦支援排行榜提交流程
由論文內容看,YoCausal 最大價值係指出一個常被忽略嘅落差:影片生成愈靚,唔代表愈接近 world model。評測結果顯示,即使係表現較前嘅模型,例如 Wan2.2-A14B,與 human baseline 之間似乎仍有明顯差距;中後段模型如 CogVideoX1.5-5B、AnimateDiff-SDXL 則較易出現違反因果嘅畫面變化。
呢個項目適合研究 Video Diffusion Models(VDMs)、world model、影片理解與生成評測嘅人,也適合想比較不同模型因果能力嘅團隊。對一般開發者而言,它最有用之處係提供一套較有解釋力嘅檢查方法,幫你知道模型失分係因為唔懂因果,定只係對時間方向反應不足。