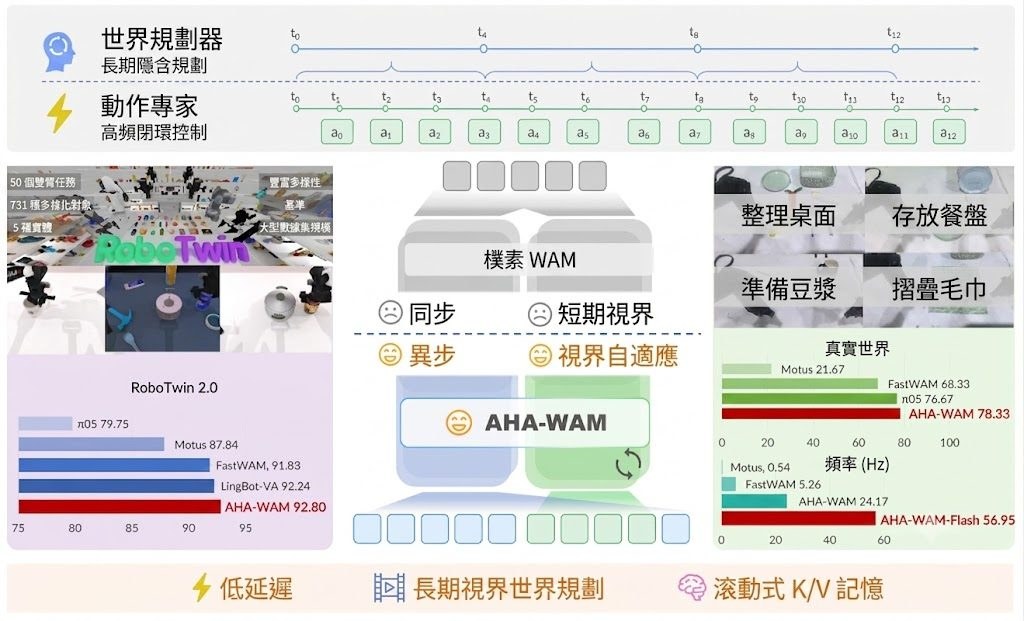
Unlimited-OCR 是一個 OCR 視覺文字辨識模型項目,也可視為一個針對長文件解析而改造的研究原型。它主要用來把圖片或 PDF 內的大量文字與版面內容一次過轉成可輸出的解析結果,重點是處理多頁文件時盡量減少記憶體負擔。
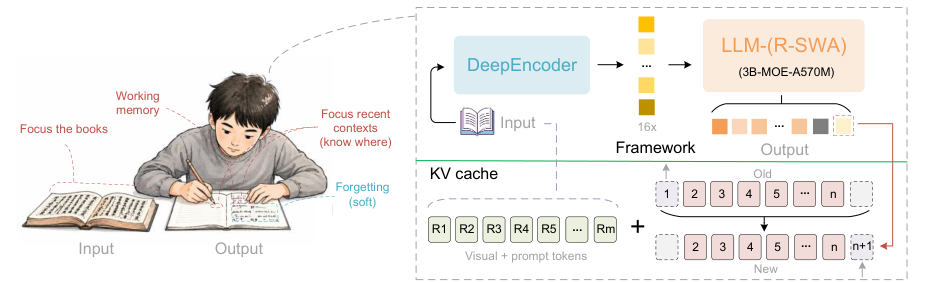
現有 end-to-end OCR 做法以 DeepSeek-OCR 為代表,會用 large language model(LLM)作 decoder,優點是能借助語言先驗提升辨識效果,但輸出一長,KV cache 會一路累積,令顯存需求上升、生成愈來愈慢。Unlimited-OCR 的做法是保留高壓縮 encoder,再把 decoder 的 attention 層改成 Reference Sliding Window Attention(R-SWA),讓每個 token 持續關注 reference tokens 與有限長度的前文,目標是把 KV cache 維持在常數規模。
這個取向最值得留意的地方,不是單純追求單頁最高精度,而是把「one-shot long-horizon parsing」放在核心位置。跟一般 full attention 比,它犧牲的是傳統全域注意力形式,換來多頁文件在 32K 長度下仍可做單次 forward pass;跟 vanilla SWA 比,它又保留 visual tokens 作為穩定參照,避免狀態傳遞後愈來愈模糊。
部署路線相當明確:項目提供 Hugging Face Transformers 推理方式,測試環境寫明需 NVIDIA GPU,並以 Python 3.12.3、CUDA 12.9 為基礎;單張圖片可在 gundam 與 base 兩種設定中選擇,多頁與 PDF 則使用 base 配置。想先了解效果,也可直接看 Hugging Face Spaces demo 或 ModelScope 版本,再決定是否自行落地。
- 類型定位:OCR 模型/研究原型,解決長文件、多頁解析時記憶體與速度惡化問題
- 核心差異:以 Reference Sliding Window Attention(R-SWA)取代 decoder 全部 attention layers
- 適合情境:長 PDF、批量文件數碼化、需要版面解析與長輸出的團隊
- 相關模型:DeepSeek-OCR、Unlimited-OCR;文中亦提到 R-SWA 可延伸到 ASR、translation
- 限制判斷:目前公開資訊主力放在推理與方法設計,具體評測數字仍要回看 arXiv 論文原文才適合作更細比較
對需要處理保單、報表、掃描檔、書籍或多頁行政文件的團隊,這個項目的吸引力會比一般單頁 OCR 更高。若你的工作重點是短文字截圖、手機快拍辨識,Unlimited-OCR 的優勢未必完全發揮,但對長輸出穩定性與部署在 GPU 環境的可行性,它展示了一條很清楚的改良路線。