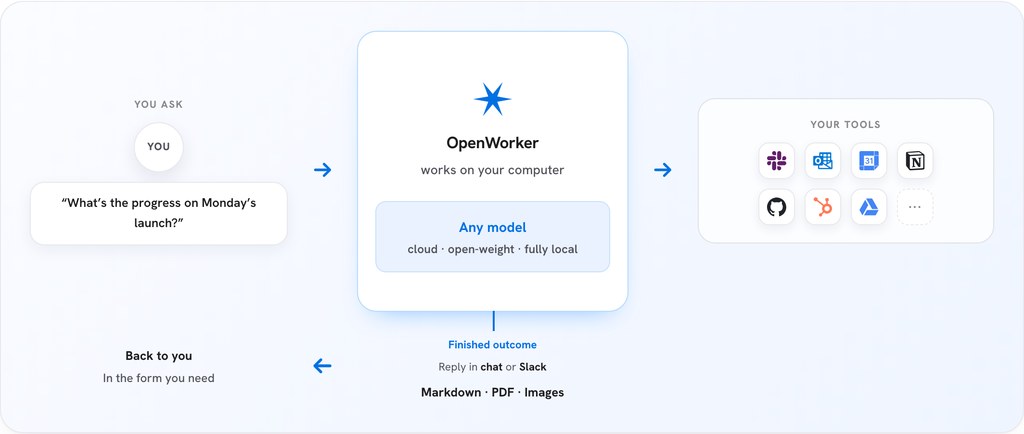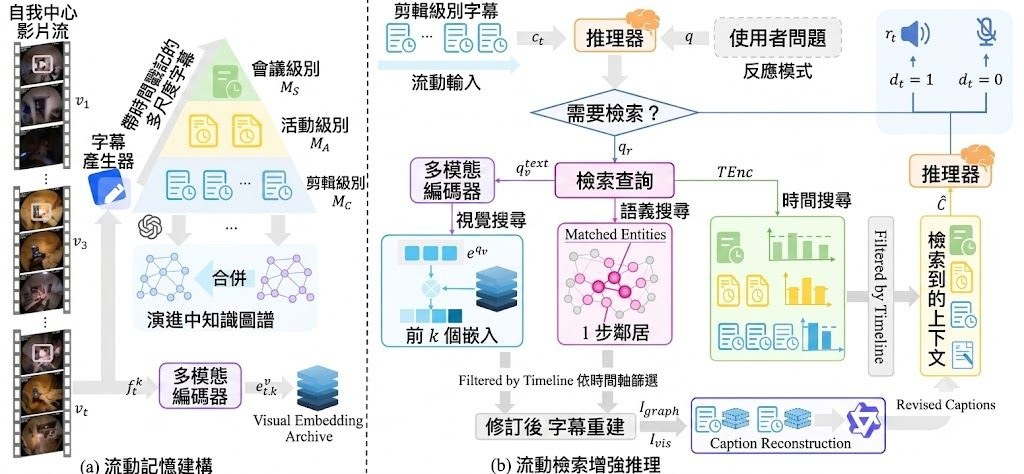
Octafuse 團隊把重點放在 Agent 工作流,而唔係只做一個轉發請求的薄層。Octafuse Gateway 屬於可自託管開源 AI gateway,處理的是多供應商模型、圖像、語音轉寫同 Agent Tools 分散管理的問題,特別適合已經有多組 API Key、不同模型來源,甚至自建服務要一齊協調的團隊。
它最有價值的地方,在於把「接得通」進一步做成「管得住」。同類項目常見重點是模型代理與相容 API,Octafuse Gateway 另外加強了路由、故障轉移、預算、審計、三賬本計費,同埋公開能力目錄,令 Agent 可以透過統一入口發現同調用資源,而管理者亦可以追蹤成本與用量。
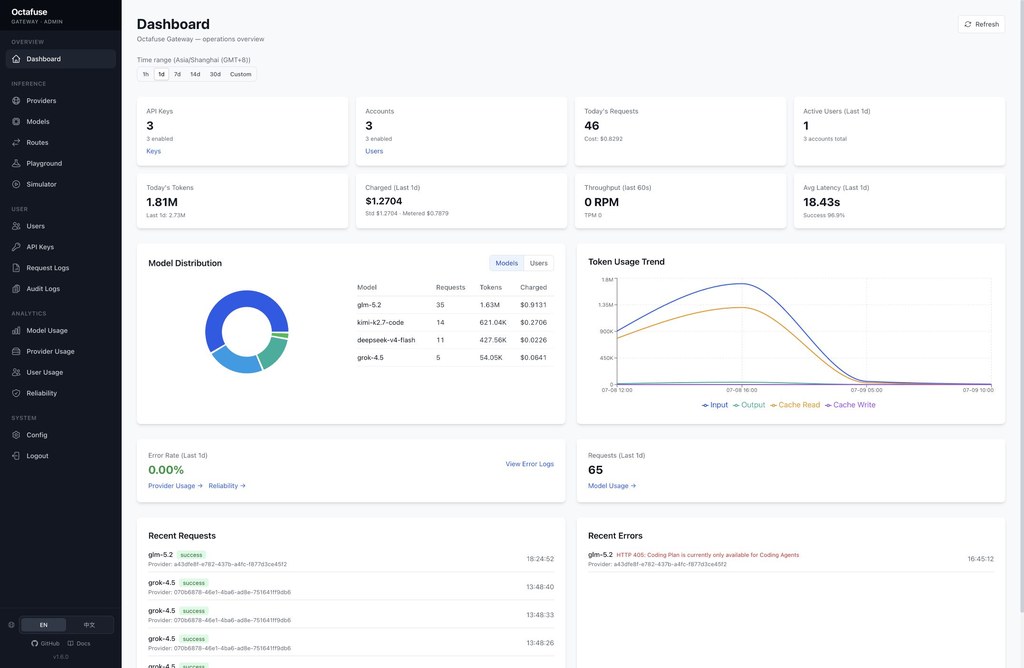
部署方向,支援 Cloudflare Workers + D1,以及 Docker 配合 Postgres / MySQL 自託管;Node.js 20+ 亦是明確要求。原始資料未展示完整安裝步驟,但有 operator 文件、Admin 管理界面、Playground 同 Simulator,反映它不是只給開發者讀 API 文件,亦有一套管理與聯調介面可用。
- 兼容 OpenAI Chat Completions、Anthropic Messages、Gemini、OpenAI Images 與 OpenAI Audio Transcriptions API
- 可集中管理 Provider API Key、RPM / TPM、並發、熔斷狀態與剩餘容量調度
- 內置 Provider 與模型導入模板,減少逐個端點手動維護
- 提供
/v1/tools/*接入 Agent Tools,現有 web-search、web-fetch、web-deep-search - 有 Playground、Simulator、審計與成本觀察能力,方便排查路由與計費設定
它強調的是可靠調度與營運控制,而非單一模型跑分。對需要向內部團隊、客戶或不同項目發放獨立 API Key 的環境,這種以資源治理為核心的取向,比單純聚合模型端點更完整,但相對也代表配置面會更廣,較適合已有多模型、多使用者或多成本中心需求的團隊。