LoopCoder-v2 是一個基於 Parallel Loop Transformers(PLT)的程式碼模型系列,目標是解決「推理步數愈多,成本與表現未必同步上升」的問題。傳統 Looped Transformers 會透過重複共享區塊去增加 latent computation,但每多一輪都會拉高延遲和 KV-cache 記憶體;PLT 則用 Cross-Loop Position Offsets(CLP)和 Shared-KV Gated Sliding-Window Attention(G-SWA)把成本壓低,讓迴圈數變成可以調整的設計參數。
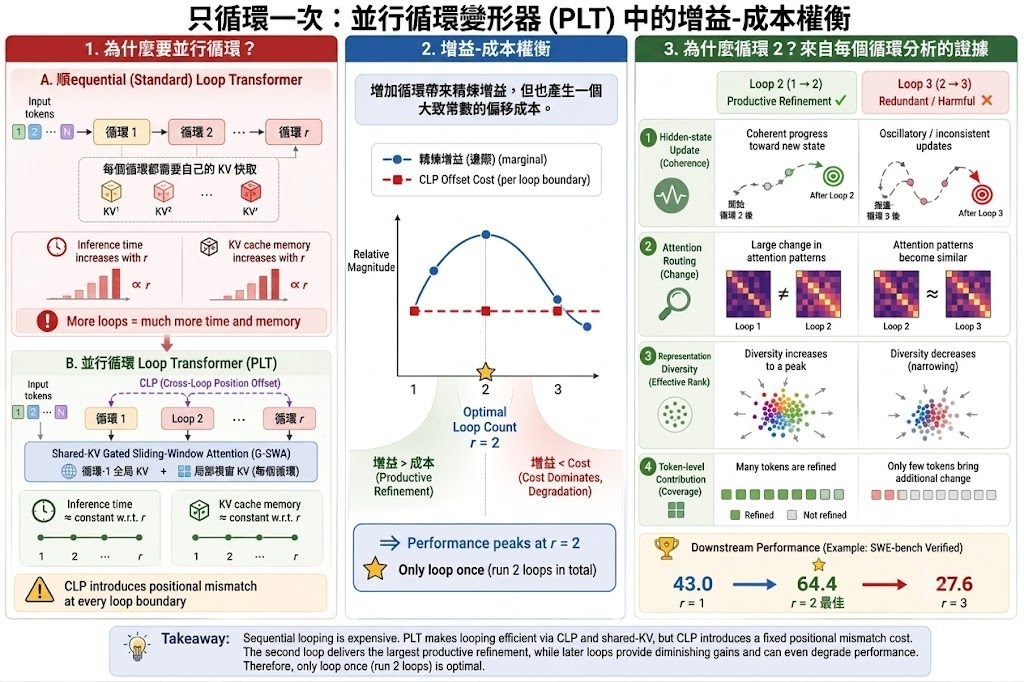
這個項目直接拆解「多跑幾輪到底值不值得」。作者用 gain–cost 角度分析 loop count:額外一輪可以帶來表示更新,但 CLP 也會引入位置不匹配的成本;兩邊一對比,就能解釋為何 LoopCoder-v2 在很多情況下是兩輪最好,而不是愈多愈好。這種分析方式比單看分數更有參考價值,因為它把效果升降和內部機制連在一起。
從結果看,LoopCoder-v2 的 7B 版本在多個程式相關測試都有明顯改善,尤其是 SWE-bench Verified 由 43.0 升到 64.4,Multi-SWE 由 14.0 升到 31.0,Terminal-Bench 亦有提升。相反,三輪或四輪時分數明顯回落,表示這個項目不是單純靠「加更多計算」換表現,而是存在一個較清晰的最佳點。作者亦用 hidden-state dynamics、attention evolution 和 output distribution shift 去佐證第二輪帶來主要增益,之後的輪次多數只會增加冗餘。
如果你想找的是可直接跑的模型,這個項目提供了 Hugging Face 上的 7B 權重,能透過 Transformers 載入後做文本生成或程式碼任務測試。適合關注 code generation、code reasoning、agentic software engineering、tool-use 的人,也適合想研究 test-time compute scaling、模型推理效率,或想比較 loop count 對表現影響的讀者。
- 主要類型是模型研究項目,同時包含評測與推理分析
- 核心結論是:兩輪通常是最佳平衡點,三輪以上可能反而拖低表現
- CLP 令平行迴圈可行,G-SWA 則把 KV-cache 成本維持在近乎固定水平
- 7B 版本在 SWE-bench Verified、Multi-SWE、Terminal-Bench、BFCL 等測試都有較完整結果
- 適合用來分析程式碼模型、代理式任務,以及測試階段算力分配