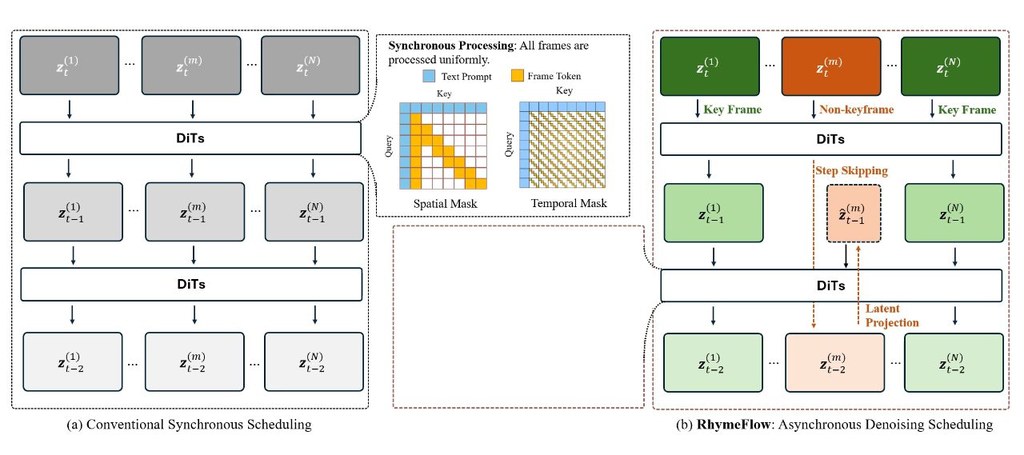
現時不少影片生成加速方法,主要仍沿用標準 diffusion pipeline:每一幀都要在所有 diffusion timesteps 完整做一次 dense denoising,再配合 sparse attention 或 KV-caching 減少單步計算。RhymeFlow 指出,這種固定範式忽略了相鄰影格內容與動作高度相關,令自然影片裡大量中間步驟其實屬於重複運算。
這是一個免訓練的影片生成加速框架,核心目標是替 DiT(Diffusion Transformers)影片模型減少推理延遲與運算成本。它將不同影格的 denoising trajectory 拆開處理:先找出主導語意變化的 keyframes,讓 keyframes 保持逐步去噪,非 keyframes 則逐步跳過部分步驟,再用 latent trajectory projection 補回時間一致性。
這個做法的創新,不在於單純把 attention 再稀疏化,而是直接挑戰「所有影格都要同步、密集去噪」的舊假設。論文描述,RhymeFlow 在現有 DiT-based video generation models 上,能同時取得更高 inference speed 與更好 visual quality;不過 GitHub 目前公開重點放在 Wan 2.1 adaptation,HunyuanVideo adaptation 仍在準備中。
如果你想試,較合理的切入點是把它當成 Wan 2.1 的加速實驗框架,比較 dense、svg、sap、rhyme、rhyme_sap 幾種方法輸出時間與畫面差異。環境要求偏高,文件列出 CUDA 12.4 / 12.8 與 PyTorch 2.5.1 / 2.6.0,亦牽涉 FlashInfer、flash-attn 和自訂 kernels,較適合已有 GPU 與 PyTorch 經驗的人。
- 項目類型:training-free 影片生成加速框架,處理 DiT 影片模型推理太慢的問題
- 方法重點:keyframes 做 dense denoising,非 keyframes 跳步處理,再用 latent trajectory projection 維持時序一致
- 可比較方法:dense、svg、sap、rhyme、rhyme_sap
- 相關模型:Wan 2.1 已有 adaptation,HunyuanVideo adaptation 尚未完整釋出
- 適合場景:研究影片生成推理優化、比較不同加速策略、測試速度與畫質取捨
整體來看,RhymeFlow 的價值很明確:它不是改模型權重,也不是重新訓練,而是重排 denoising flow scheduling,從流程層面節省計算。對研究者與進階開發者而言,這類思路比單純堆硬件更有參考價值;對一般創作者來說,現階段門檻仍在部署與 GPU 環境。