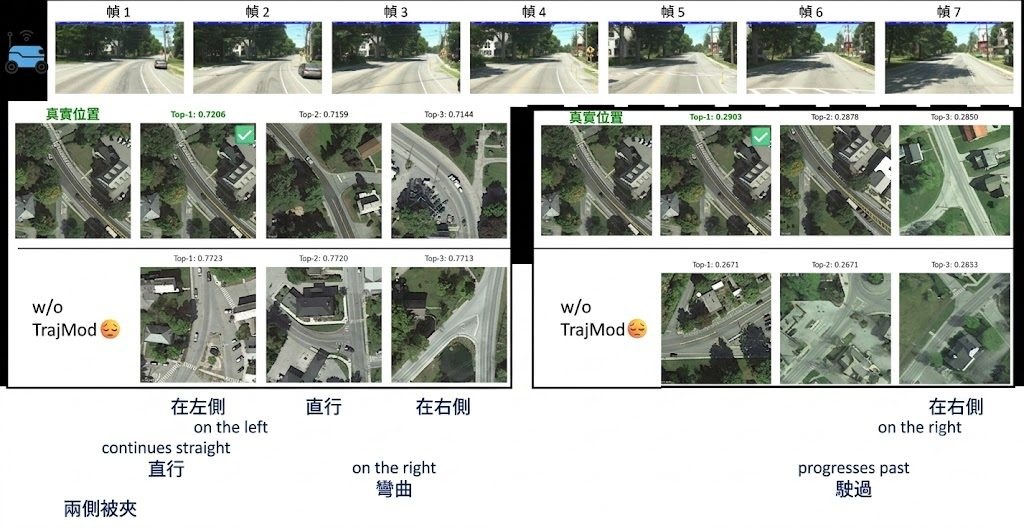
拍 AI 風格化影片時,最難控制的往往唔係畫風,而係鏡頭點樣郁、人物點樣企。Film space 把呢個問題拆得幾務實:它屬於 3D 預演工具,用 iPhone ARKit 把你真實行走時的裝置移動,轉成可錄製的虛擬鏡頭路徑,之後再交畀 Seedance 2.0 呢類工具做 AI style transfer 參考。
它的定位唔係直接生成影片,也唔係完整剪接系統,而係補上 AI video workflow 入面最易失真的一段:先用虛擬 studio 做 blocking,再用手機走一次鏡頭。相比純文字提示詞或者只靠模型自己猜運鏡,Film space 換來的是更清楚的鏡頭方向感;代價是你需要親身拿住 iPhone 進行錄製,而且目前明顯偏向單機、裝置端流程。
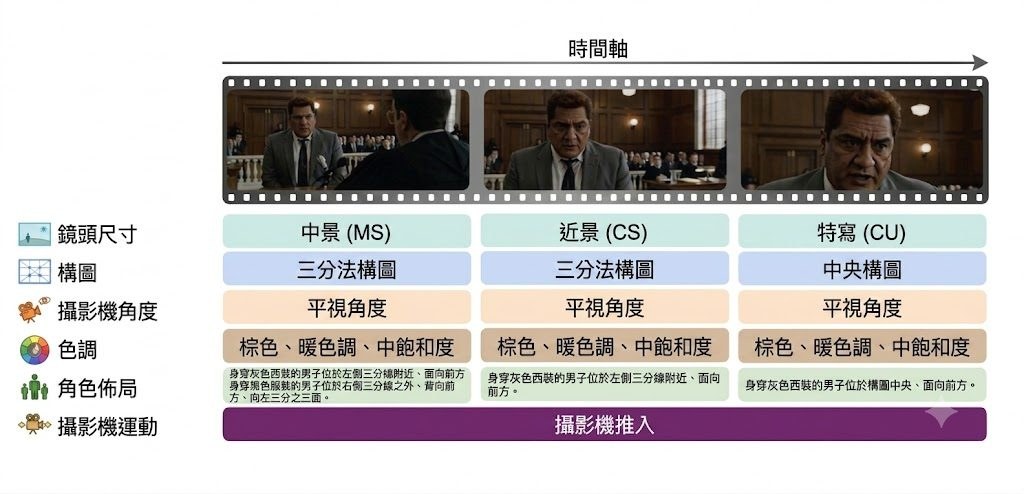
部署方式:整個流程在裝置上完成,建議橫向畫面使用,錄好的片段會存入相簿,再帶去後續生成工具。場景編排包括棋盤地板、格線、座標軸,亦可加入 human stand-ins 來模擬人物站位;去到 Camera mode,手機的移動、轉向與傾斜會直接變成鏡頭運動,配合 35mm、50mm、75mm、200mm 焦段預覽,對做分鏡、音樂錄像、短片測鏡頭的人尤其有幫助。