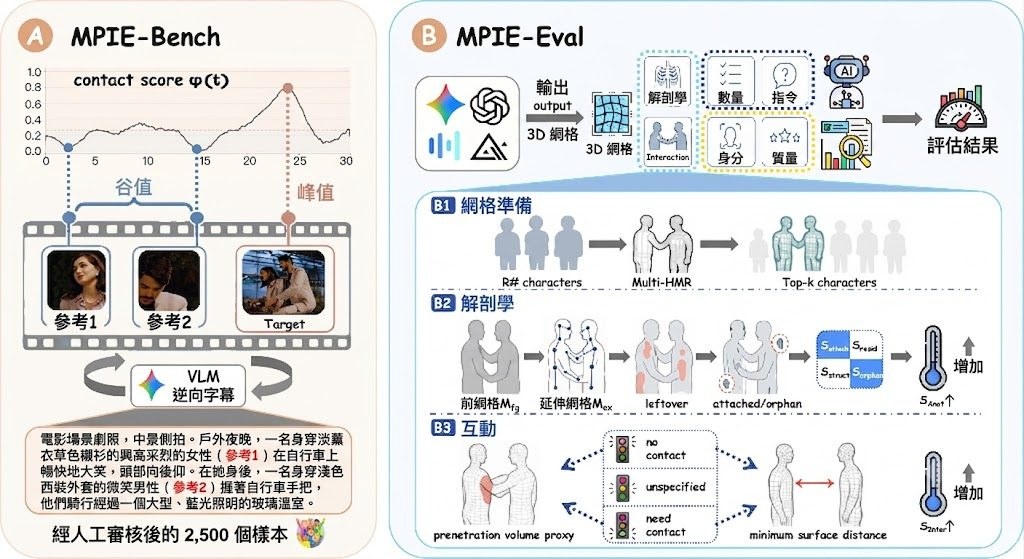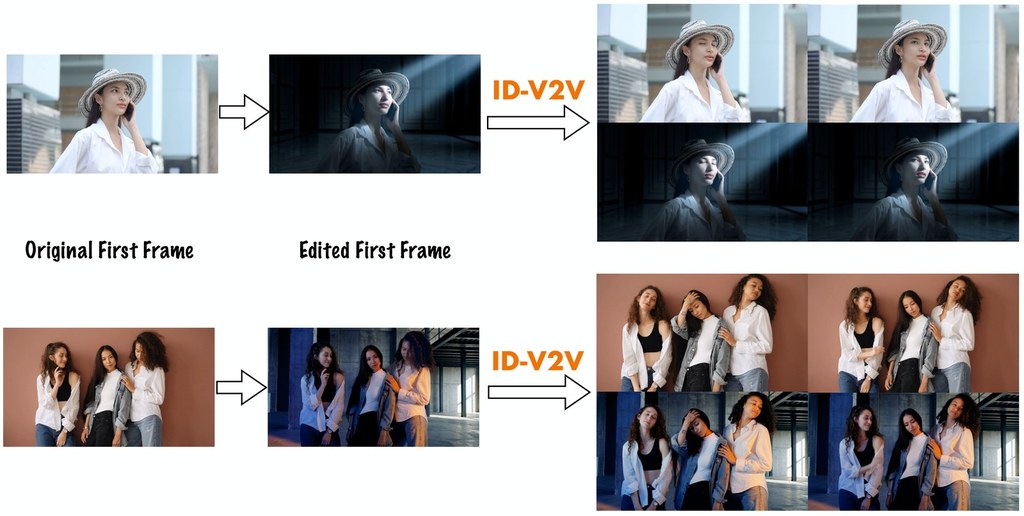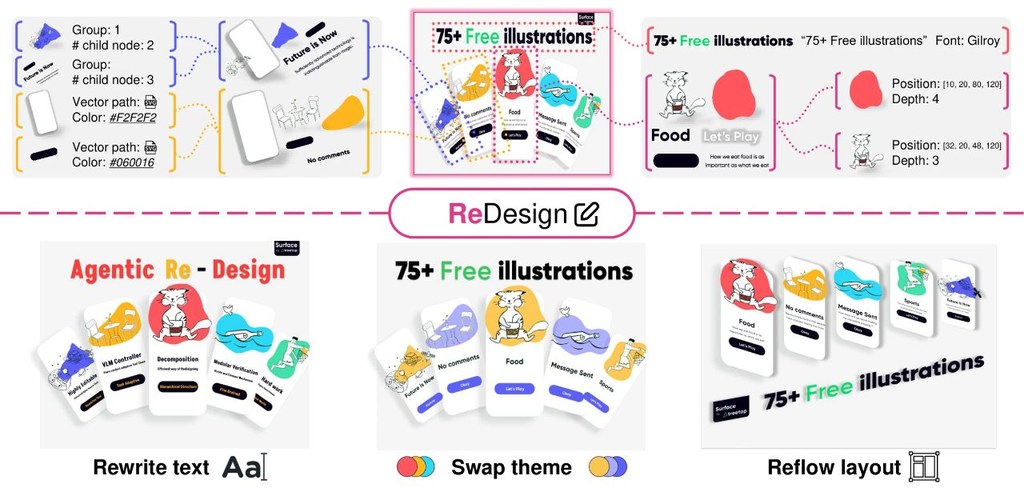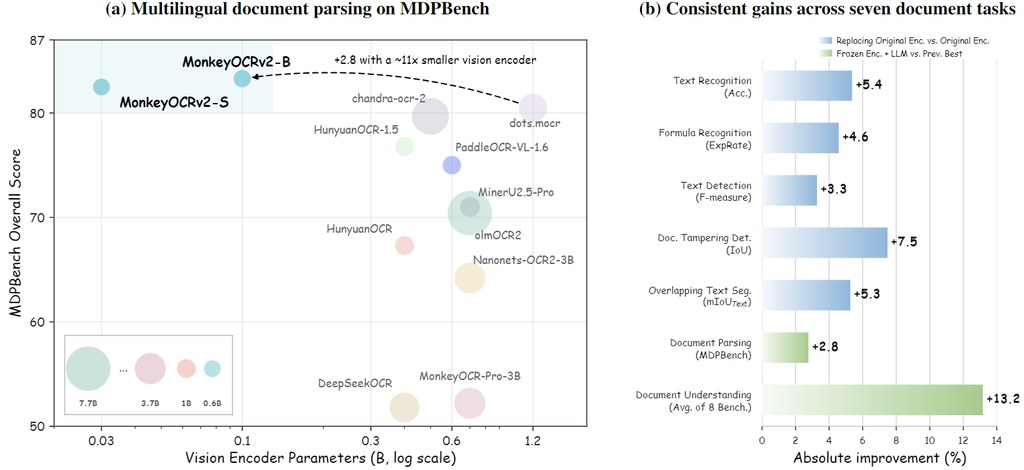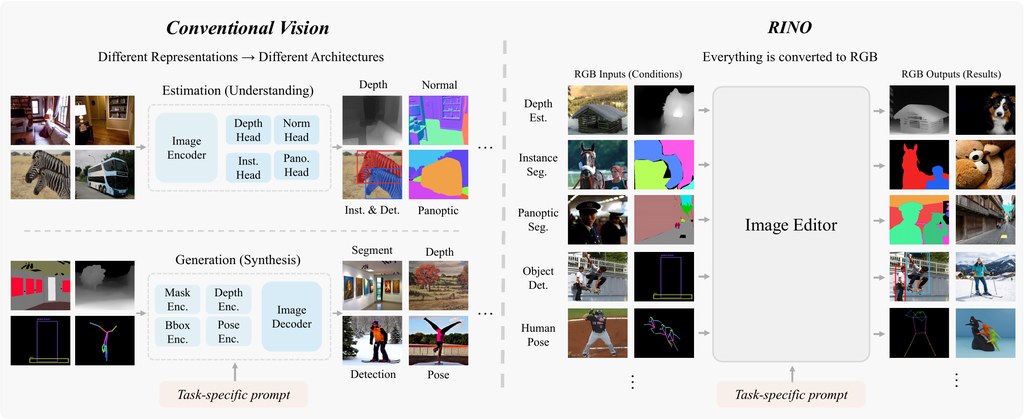
做影片流程最麻煩,往往唔係生成一段畫面,而係素材、剪接決定、旁白、輸出格式同後續修改散落喺唔同工具。
Montara 就係朝住呢個痛點而來:一個本地優先嘅開源影片製作工具/框架,用 Timeline IR 做唯一時間軸來源,將規劃、編輯、渲染同交接串返埋。
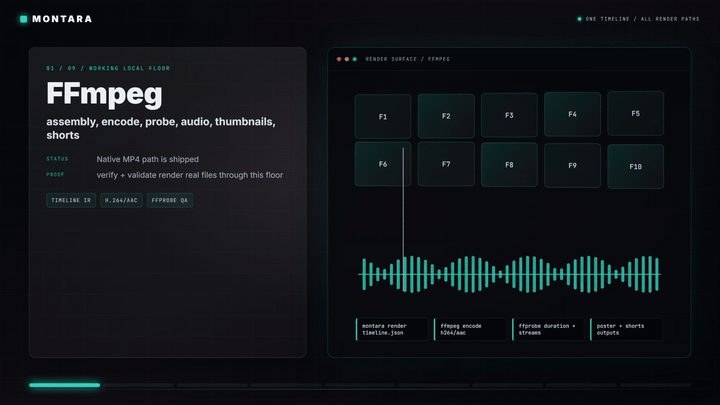
它吸引嘅地方,在於先處理「冇雲端都要交到片」呢個現實限制。就算零 API keys,仍可經 FFmpeg 走本地 fallback 輸出可觀看 MP4,連字幕卡、語音路徑同部分媒體都預留咗本地方案;有裝 Remotion 就做 native smoke,冇裝亦會退回 FFmpeg,呢種設計比起只展示理想雲端流程嘅項目踏實得多。
同類做法常見係綁死某個生成服務或者某款剪片介面,Montara 反而把 provider 放成可插拔層,會建立 request、做 redaction、支援 dry-run 同 live-audit,但付費雲端呼叫要明確開啟。代價亦好清楚:它而家最成熟嘅係時間軸驗證、編輯操作、渲染路徑、editor bridge 匯入匯出,同埋真實 MP4 渲染與 post-render QA;README 亦講明長片規模仍屬 roadmap,唔係所有電影級工作流都已全面驗證。
- Timeline IR 把場景計劃、剪接決定、匯入 editor cut 同生成素材收斂成一份 JSON
- 本地路線完整,FFmpeg 係通用底線,部分 video/image/speech/music 有 fallback
- 可匯出 EDL、OTIO、FCPXML,方便轉去 Premiere、Resolve、Final Cut 繼續做
- provider 機制重視審計與可驗證性,適合要保留流程紀錄嘅團隊 較受惠嘅會係想把 AI 生成同傳統後期接埋嘅內容團隊、要保留本地控制權嘅創作者,或者打算讓 agent 參與影片流水線嘅開發者。
Montara 已經唔止係 demo 級拼裝,因為它把「可編輯來源」、「真實渲染結果」同「可交畀剪輯軟件接手」放埋同一條線;不過想追求高度成熟嘅長篇製作,仍要留意目前覆蓋範圍主要集中喺已測試嘅 renderer 同橋接能力。