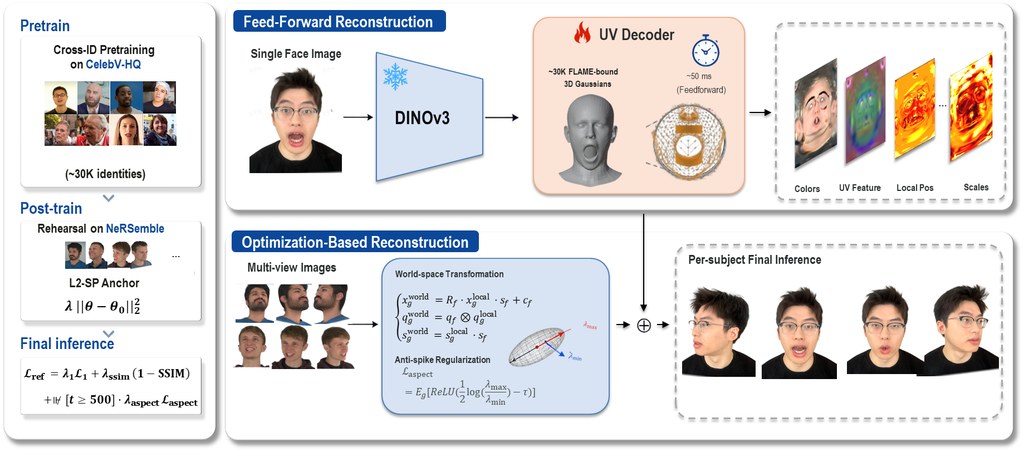
想修改鼻形、加鬍鬚或雀斑,同時又保留同一個人的辨識度,對 text-to-image (T2I) 個人化生成來說一直很難。Latent-Identity Tuning in Text-to-Image Personalization Models 聚焦在這個卡位:不只是改一張圖,而是調整某個人的身份表示,之後可在不同場景中生成同一個經過微調的人。
做法上,輸入人像會先經由預訓練 personalization encoder 轉成一組 identity tokens。研究發現,不同 token 會偏向捕捉眼、鼻、口、頭髮等不同區域或語義特徵,因此可以在這個 identity space 入面尋找有意思的方向,例如鬍鬚、捲髮或其他面部屬性,再沿着方向調整。
- 直接微調 identity tokens,而不是只在單張圖片上修圖
- 可做局部、細緻,而且語義較一致的人臉改動
- 修改後的身份可配合不同 prompts 生成新圖
- 透過 attention maps 觀察 token 與臉部區域的關係
- 使用定性與定量實驗檢查局部編輯及跨圖身份一致性
和常見 image editing 相比,這個方法的差異在於它處理的是「身份的潛在表示」。換言之,改動不是鎖死在原圖姿勢、背景或光線,而是把編輯後的身份交給 T2I 模型,在新場景、新描述下仍盡量維持同一個人。
這類方法會較適合需要穩定角色形象的創作者、視覺設計工作流,以及研究人像個人化生成的人。限制上,資料未交代可直接使用的產品化介面或完整模型名單;引用模型方面,內容只提到預訓練 personalization encoder 與 text-to-image model,未列明具體基礎模型名稱。