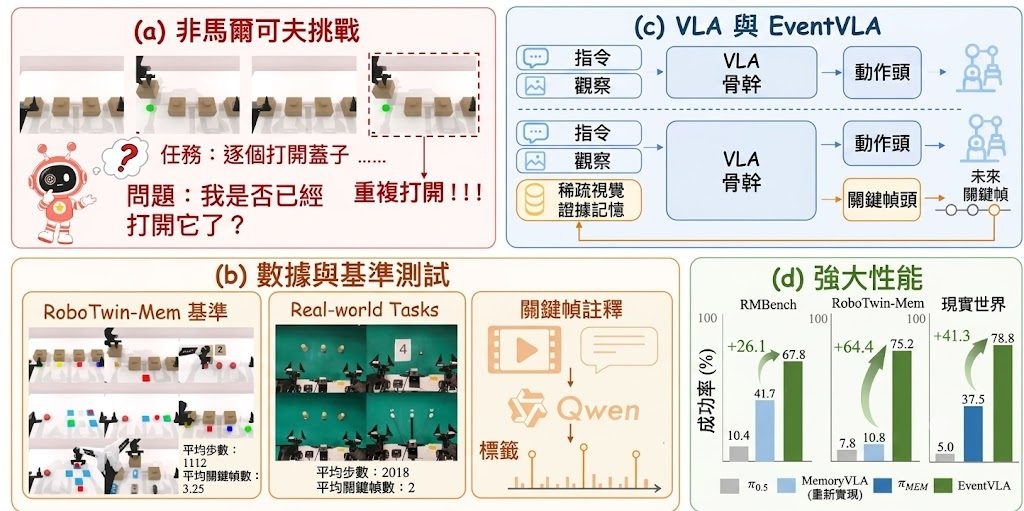
LISA 的核心做法是從側網絡的指定層提取特徵,透過一個輕量級解碼器(decoder)將其投影到分數潛在空間(score latent space),然後計算解碼器輸出與近似似然分數目標之間的距離,作為額外的正則化損失(regularization loss)。這個設計讓側網絡的特徵在條件建模中更加解耦(disentangled),且推理階段無需任何額外計算。
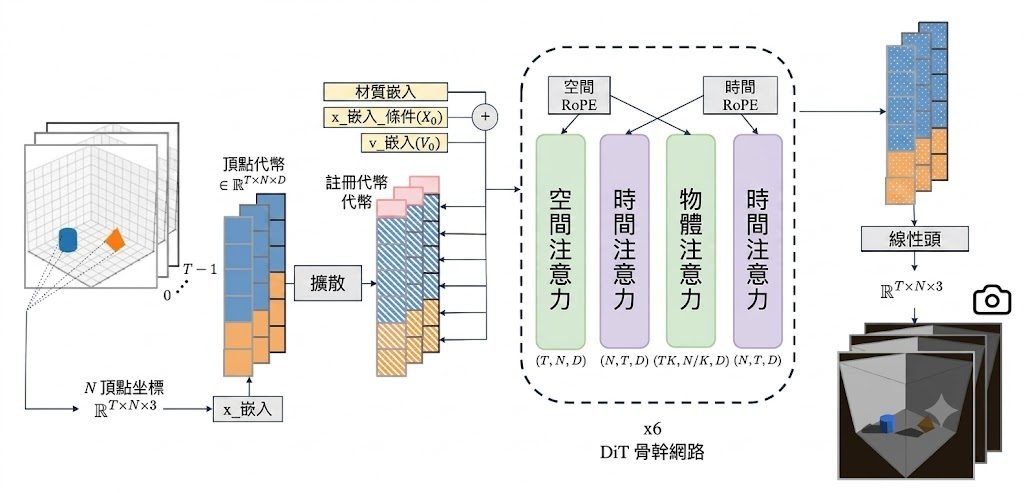
PhysiFormer 是一個 diffusion transformer 模型,用世界座標中的 3D mesh 直接模擬物體運動。它要處理的是在已知初始頂點位置、速度與材質條件下,生成之後一段時間內合理可信的 4D 動態軌跡。
它和常見 video world models 的分別,在於不是在視角相關的像素空間推測畫面變化,而是直接預測 world coordinates 裡的 vertex trajectories。論文指出,這個做法不依賴手動指定的模擬結構、shape latent,亦不需要明確加入 rigid-transform prediction 一類限制,改用單一步驟的去噪擴散過程學習完整時域軌跡。