做會議紀錄、訪談整理或臨床語音分析時,最大落差往往唔係辨識到幾多字,而係系統究竟寫出「講咗乜」定「本來想表達乜」。CrisperWhisper 屬於開源語音辨識模型項目,核心價值係將 verbatim 同 intended 兩種轉錄模式變成可明確控制的輸出,令逐字稿唔再受訓練資料風格左右。
呢個取向同一般 speech-to-text 系統好唔同。常見做法會不一致地刪走 filler、重複、停頓同 cut-off,CrisperWhisper 2.0 就刻意保留呢啲語音細節,或者按需要輸出整理後版本;同一段錄音可以得出兩份用途完全不同嘅文本。對做 TTS 資料整理、醫療或研究訪談分析、需要精準字幕時間碼嘅團隊,呢種分流比單純追求可讀性更有用。
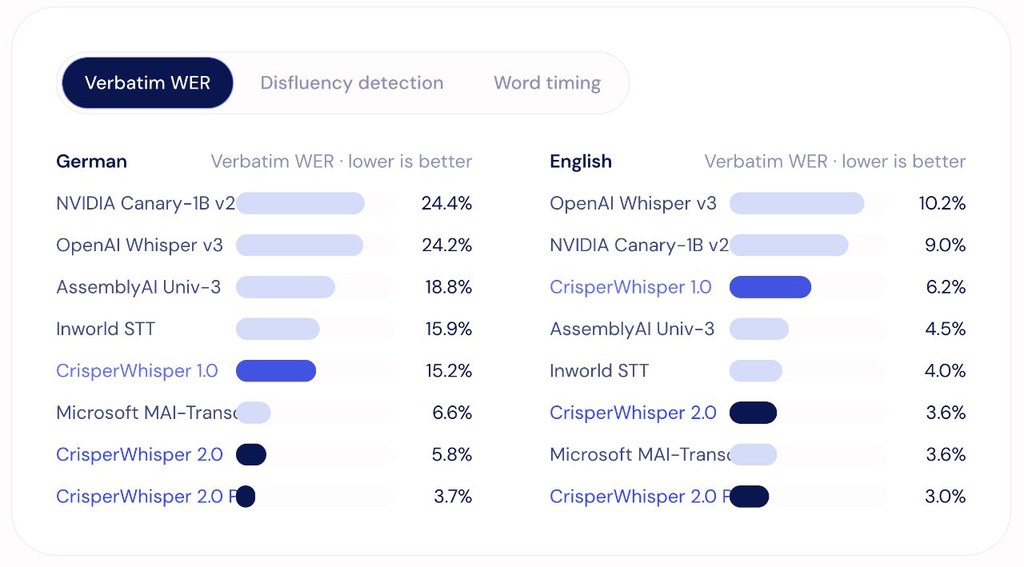
項目另一個關鍵位係時間對齊同長音訊處理。它提供 word-level timings,讀稿語音平均邊界誤差約 30 ms,對話語音約 41 ms;長音訊則用 conditional continuation 避免一般分段轉錄常見嘅重複漏字。README 亦提到推理端基於 CTranslate2,配合 speculative decoding,同時減輕 Whisper 常見 looping-hallucination 問題,方向明顯係朝住 production inference。
- verbatim 與 intended 兩種模式分開控制,適合同一錄音對應不同工作流
- 支援 multilingual,覆蓋多數 Whisper 支援語言
- 可用 Verbatimize 依據音訊加乾淨文本補回真實語氣詞與口誤
- 長音訊轉錄著重連續性,減少 chunk 邊界造成嘅錯漏
- Nyra Verbatim Speech Benchmark 以 disfluency F1 等指標衡量保真能力
安裝與部署方向相對清晰:模型可經 PyPI、Hugging Face 同文件使用,推理路線圍繞 CTranslate2 runtime,而唔係只停留喺研究展示。要留意嘅取捨亦好直接,當你要的是可讀、可發布文本,intended 模式更合適;當你要保留猶豫、重複、笑聲同語音事件,verbatim 模式先真正發揮價值。呢個項目唔係單靠更高 WER 成績去吸引人,而係重新界定逐字稿應否忠於說話表面形式,並且用 benchmark 將呢件事量化。