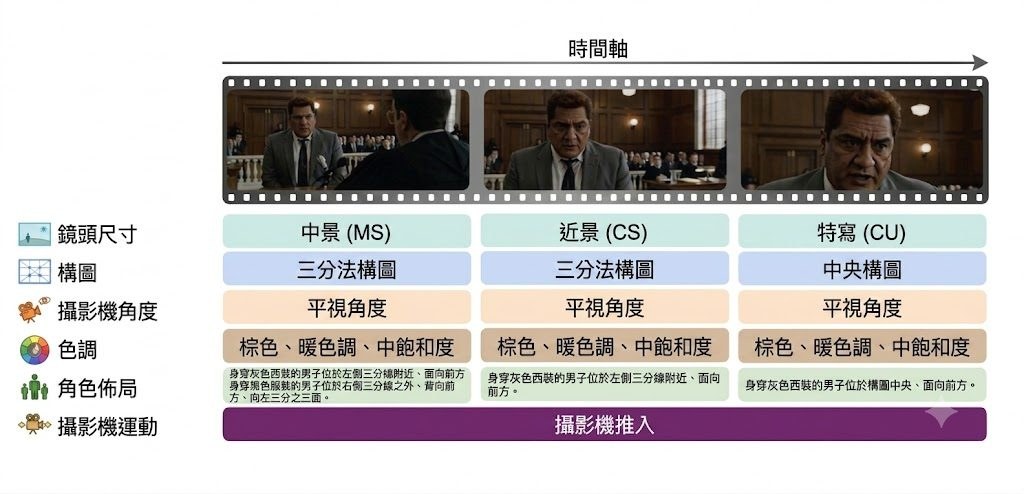
一段影片好不好,不一定只靠整體觀感判斷;鏡頭遠近、構圖、機位、色調同運鏡,往往先係影響觀感的核心。FilmOps 正正瞄準呢個缺口:它不是一般影片生成模型,而是一套開源 operator suite,用來把影片畫面映射成結構化的 cinematographic labels,處理的是電影語言難以被細緻分析與量化的問題。
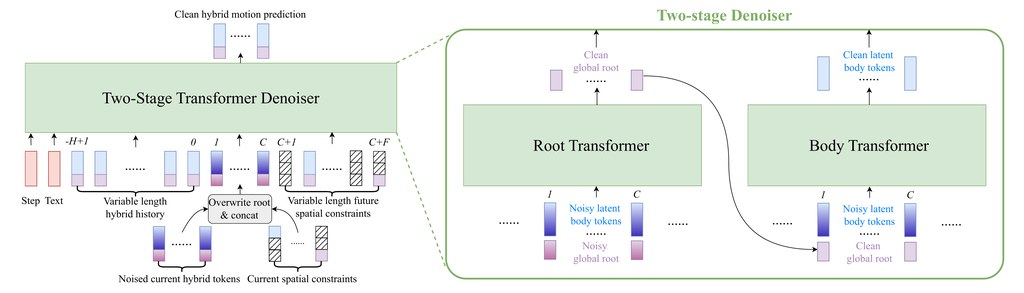
現有影片 benchmark 多數集中在 general perceptual quality、text alignment 或 temporal smoothness,對專業 cinematographic language 仍然偏粗略;general-purpose MLLMs 又難以穩定辨認 film-specific attributes,而 aesthetic predictors 這類領域模型面對 cinematic content 亦有明顯 domain gap。FilmOps 的取向很清楚:不用單一大模型包辦所有判斷,而是把六個維度拆開,按任務特性分配不同 backbone,令 shot scale、composition、camera angle、color & tone、character layout 同 camera movement 可以分別處理。
它的價值在於更像一套分析管線,而不是只給你一個總分。項目覆蓋 55 個以上子類別,分類定義對齊 Film Art、ASC Manual、Cinematography: Theory and Practice,亦經過 practitioner 驗證;加上 modular architecture,可以獨立用單一 operator,或者走 unified pipeline。對要做影片生成評測、鏡頭標註、資料整理,甚至研究 FilmBench 呢類 cinematic benchmark 的團隊,這種拆解方式會比泛用多模態評分更有解釋力。
- 屬於開源工具/模型組合,重點是把影片拆成電影語言標籤,而不是直接生成影片
- 六個 operator 採用 task-specific backbone,包含 DINO ViT-B/14、BEiT Base、ResNet-18、InternVL3-14B
- 支援 live-action、3D animation、2D animation 同 stylized content,強調 cross-genre consistency
- 已交代基本部署條件,包括 Python、PyTorch、CUDA 與 ffmpeg,也提供 unified pipeline 與 checkpoints 準備方向
現有資料只明確指出它在所有維度都勝過 general-purpose MLLMs,但細節主要放在論文。配套的 FilmBench 亦用同一套 Cinematic Language 思路建立 benchmark,並聲稱 evaluator 在模型排名上與人工評分高度一致,說明 FilmOps 並非只為展示而做,而是服務整個影片評測流程。不過它始終偏向分析與標註基建,想直接拿來做完整產品,仍要自行處理 checkpoints 下載、推理資源,並接受部分 operator 對 CUDA 與較重模型的依賴。