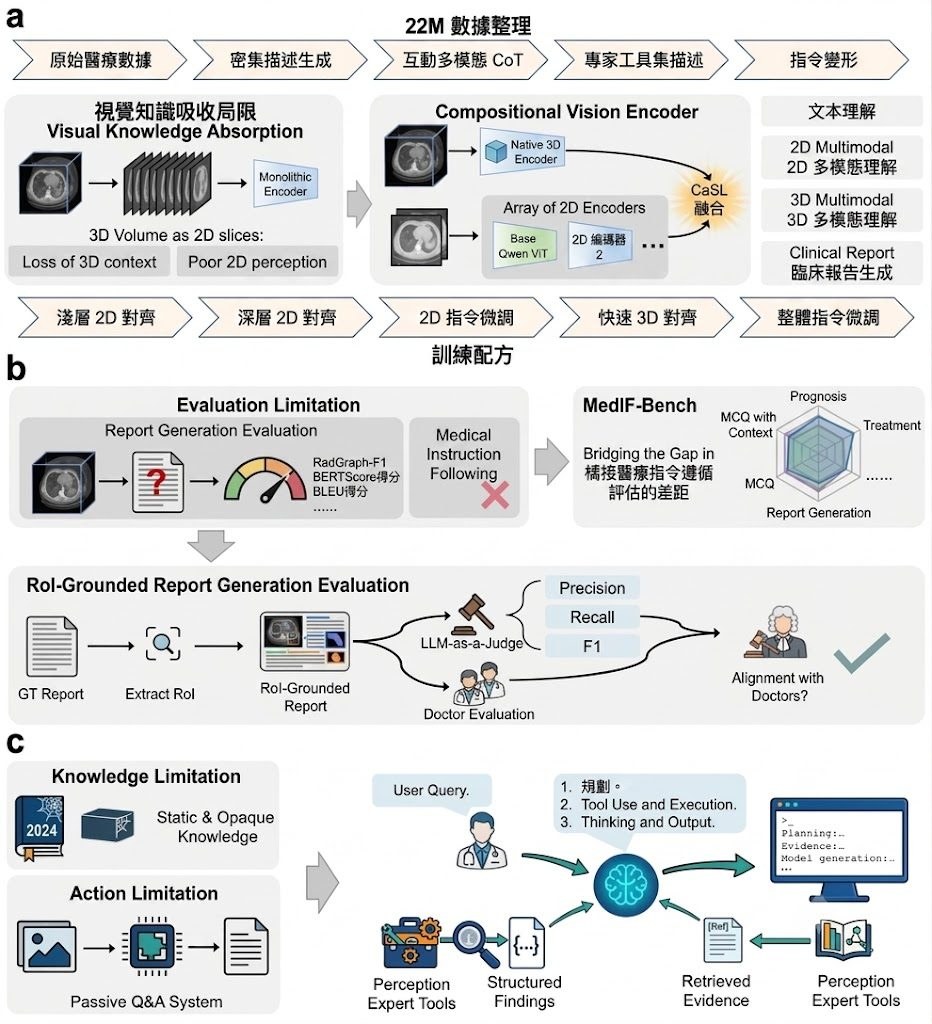
要兼顧回應速度、部署成本同 Agentic 能力,DeepSeek-V4-Flash-0731 走的是「較少啟動參數換取高效任務表現」的路線。頁面已清楚寫明它與 DeepSeek-V4-Flash-DSpark 採用相同模型結構,並且附帶 speculative decoding module,所以它不只是一般聊天模型,而是明顯朝工具使用、自動化操作與程式任務優化的版本。
它屬於 DeepSeek-V4-Flash 官方正式發布版,取代 preview 版本,並強調 agentic capabilities 有明顯提升。模型卡同時指出它的模型結構與 DeepSeek-V4-Flash-DSpark 一致,代表推理流程很可能圍繞主模型加速草稿模組來設計。
效能數字是最值得留意的部分。它在 Terminal Bench 2.1、NL2Repo、Cybergym、DeepSWE、Toolathlon-Verified、Agents’ Last Exam、AutomationBench Public 等基準上,普遍明顯高於 DeepSeek-V4-Flash(Preview),部分項目亦超過 DeepSeek-V4-Pro(Preview)。這種進步集中在 terminal 操作、程式庫理解、資安演練、軟件修復同工具鏈任務,反映它更像為 Computer-use agents、程式代理與自動化流程而調整,而不只是追求一般問答分數。
- 與 DeepSeek-V4-Flash-DSpark 同結構,並附帶 speculative decoding module
- 官方正式版取代 preview,重點提升 agentic capabilities
- 多個 Agent/編碼基準明顯優於 DeepSeek-V4-Flash(Preview)
- 啟動參數較少,但表現可與部分強勢閉源模型接近
部署資訊方面,內容只提供一則討論帖,提到可用兩台 DGX Spark 配合 ghcr.io/bjk110/vllm-spark:unholy-fusion-prod-ready 作最少設定部署;但模型頁面片段未列出上下文長度、GGUF 格式量化檔、mmproj、檔案大小、chat template 注意事項或 v2 檔名變更,因此不能推斷 llama.cpp、Ollama、LM Studio 的支援細節,也不能提供 Q4_K_M 一類量化建議。現有資料較適合把它理解成一個偏向高效率 Agent 任務的 DeepSeek 模型發布,而不是本地 GGUF 部署導向的模型。