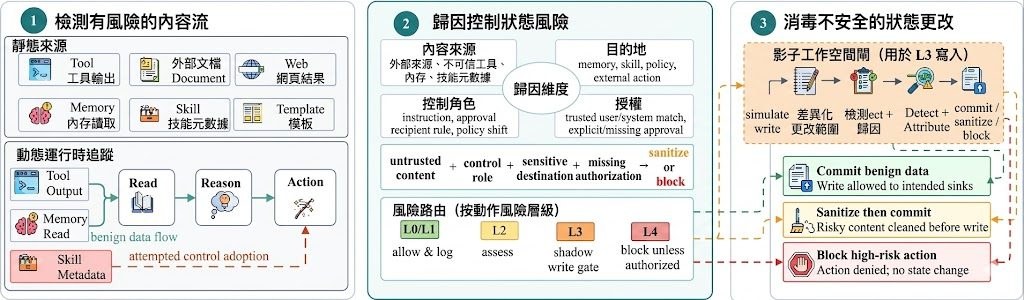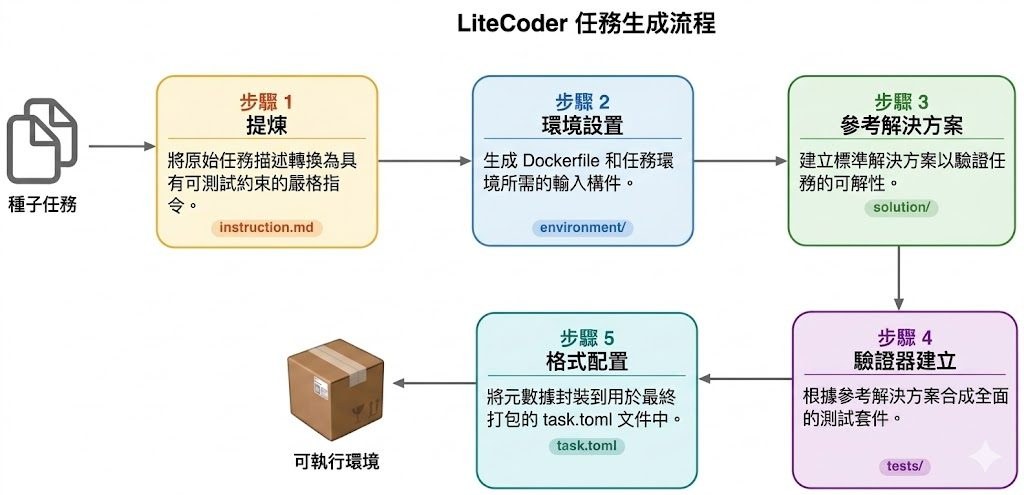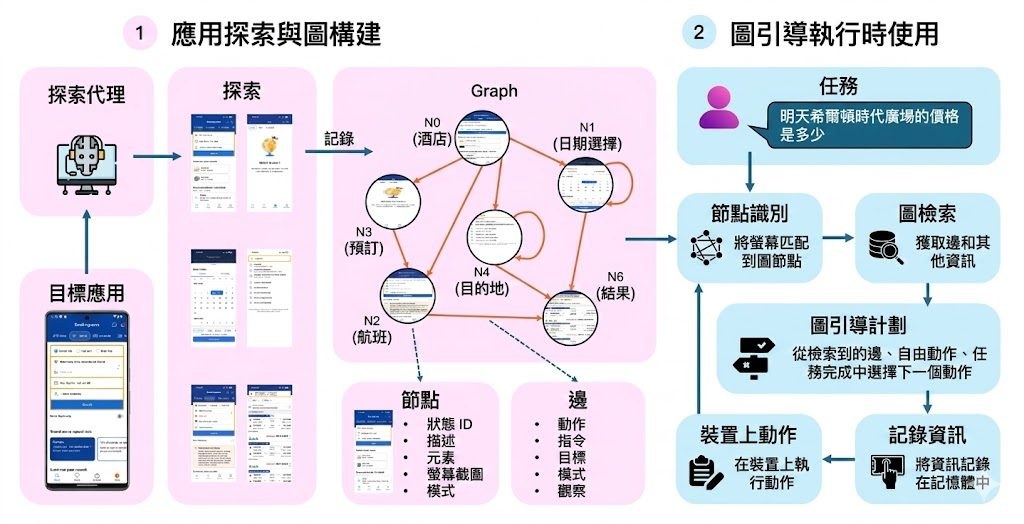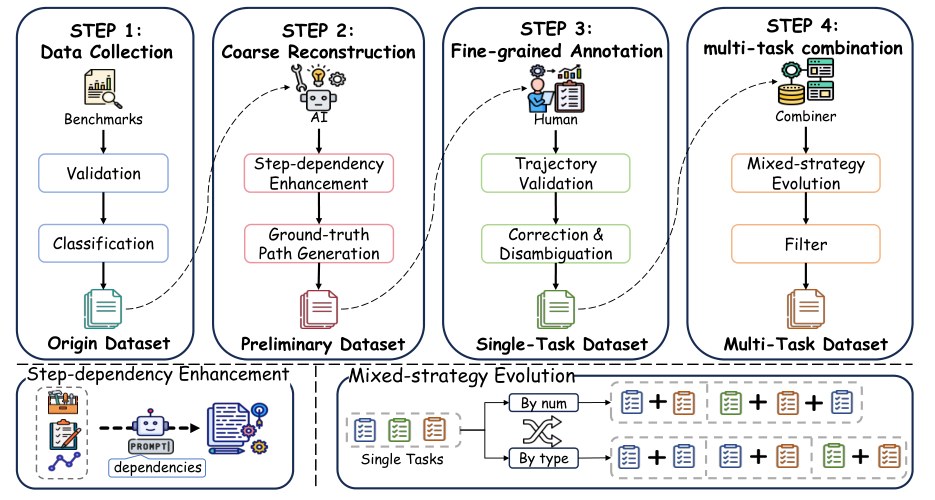
近年 GUI agents(圖形介面智能體)雖然進步神速,但只要自己點錯一個按鈕、誤判畫面狀態,往往就會卡住無法完成任務。這項由阿里雲團隊撰寫、入選 ICML 2026 Spotlight 的工作,正是針對這個「自己造成的錯誤」痛點,從評估與訓練數據兩端同時入手。
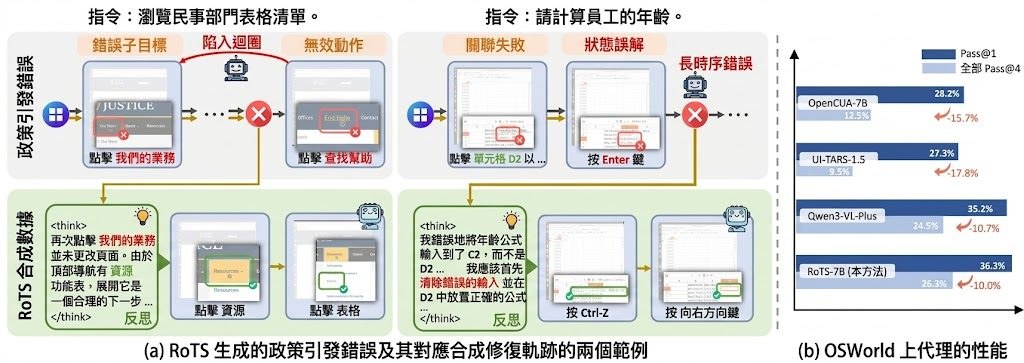
他們先推出了 GUI-RobustEval 基準,收錄 1,216 個可執行測試案例,涵蓋 11 種錯誤類型與 4 種錯誤深度,讓開發者能系統化量測智能體的「自救」能力。接著提出 RoTS 框架,以樹狀結構(tree-based)在線生成 80 萬條訓練軌跡,主動探索不同錯誤模式並合成對應的恢復步驟。
基於這批數據微調而成的 RoTS-7B 與 RoTS-32B,在 OSWorld 上於開源權重模型中取得領先表現,其中 RoTS-32B 達到 47.4% 成功率與 33.8% All-Pass@4 分數。研究團隊指出,這些分數顯示長時程錯誤恢復能力,同時提升了整體任務表現。
對從事電腦使用代理(Computer-use agents, CUAs)研究、開源 VLM 微調,或關注 GUI 自動化在真實環境穩定性的團隊而言,這是一份值得追蹤的成果。論文與數據集已公開,但程式碼與評估工具仍在整理中,有興趣的人可先閱讀論文並關注後續釋出。
重點摘要:
- 解決 GUI agents 因自身策略錯誤而無法恢復的部署瓶頸
- GUI-RobustEval 提供 1,216 個測試案例,覆蓋 11 種錯誤類型
- RoTS 以樹狀在線合成框架產出 80 萬條高品質訓練軌跡
- RoTS-7B 與 RoTS-32B 於 OSWorld 開源模型中表現領先
- 程式碼與數據集仍在整理階段,論文已於 arXiv 公開