
NL2SQL 如何走向企業級數據智能體

這是一篇介紹 NL2SQL(Natural Language to SQL)與 Text2SQL 技術演進的技術文章。它主要說明系統如何把自然語言查詢轉成可執行、可驗證,而且符合業務語義的 SQL,而不只是做文字層面的翻譯。
文章指出,NL2SQL 真正處理的是「業務語言」與「資料庫結構」之間的落差。使用者問的是模糊的商業問題,系統卻要完成查詢意圖理解、表與欄位定位、JOIN 路徑規劃、SQL 校驗、執行與結果驗證,所以它同時牽涉 NLP、資料庫、程式生成、資訊檢索與系統工程。
和早期把 NL2SQL 視為 Seq2Seq 翻譯任務的做法相比,文中更強調執行語義等價。一段 SQL 就算語法正確,也可能選錯表、誤解指標口徑,或者在聚合粒度、過濾條件與權限範圍上出錯,因此企業場景的重點不是「生成像 SQL 的文本」,而是產出能在真實數據環境中正確運作的查詢邏輯。
- 技術演進由規則模板、傳統語義解析、Seq2Seq,一路走到 Schema Linking、Schema-aware、Graph-based、RAG + LLM
- 核心難點不只在生成 SQL,更在表、欄位、值與業務指標的語義映射
- 新一代方向是 Agentic + Semantic Layer,加入檢索、規劃、校驗、修復與解釋能力
- 固定報表場景可用模板法提升穩定性,但覆蓋率有限,難應付開放式提問
這類內容最適合數據平台、BI、自助查數與企業 AI 問答工作流的讀者閱讀。文中提供的是技術脈絡與方法拆解,暫時未見具體安裝流程、下載連結或可直接啟用 OpenClaw、OpenCode、Codex、Hermes Agent、Copilot、Pi 的後台操作資訊,因此不能延伸成相關部署教學。
Google A2UI 想讓 AI Agent 直接講出介面
A2UI 是一個開源框架/協定格式項目,核心是讓 AI agent 用宣告式 JSON 產生可更新的互動介面。它要解決的問題很直接:agent 不只回文字,還可以安全地把表單、卡片、按鈕等 UI 交畀前端或原生客戶端渲染。
這個項目的取向,和直接讓 LLM 輸出 HTML、JavaScript,或者在前端執行 agent 生成程式碼很不同。A2UI 把介面描述同實際元件庫分開,client 只會渲染已預先信任的元件 catalog,安全性較高,但代價是自由度受 catalog 和 renderer 能力限制,並非想畫甚麼介面都可以即時做到。
現有資料顯示,A2UI 仍屬 early stage public preview,目前生產版本為 v0.9.1,v1.0 specification 則是 release candidate。部署與理解方式上,它較像一個要接入現有產品的基礎層:agent 端輸出 A2UI JSON,client 端用對應 renderer 轉成 Flutter、Angular、Lit、Web 或其他原生 UI;官方網站有 Quickstart、Client Setup、Agent Development 同 renderer 文件,但這份資料未列出完整安裝流程,亦看不到一鍵接入 OpenClaw、OpenCode、Codex、Hermes Agent、Copilot、Pi 的管理介面整合資訊。
它的優勢,在於增量更新和跨框架可攜性。README 提到 UI 會以扁平元件清單加 ID 關聯表示,這種結構對 LLM 較友善,也方便串流更新;同一份 A2UI payload 理論上可以映射到不同客戶端。相比綁死某一個前端框架的做法,這更適合多端產品、內部工具平台,或者需要跨信任邊界把 agent 能力交到用戶手上的團隊。
重點可概括為:
– 不是模型,而是讓 agent「講 UI」的協定與函式庫
– 核心賣點是安全渲染,避免直接執行 LLM 生成程式碼
– 支援增量更新,較適合串流式互動介面
– 可對接多種前端技術,但前提是要先有 renderer 和元件 catalog
– 文件已見版本演進與示範場景,公開資料未提供明確性能跑分
性能與現有內容較著重設計理念、版本演進與示範,而不是基準測試數字,所以不宜把它理解成追求速度排行榜的項目。較可能受益的是正在做 agent 產品的前端團隊、平台工程團隊,以及需要把資料收集、任務委派、跨端 UI 呈現整合起來的企業應用;相關技術脈絡則包括 AI agents、MCP、Flutter、Angular、Lit、React、SwiftUI,以及 A2A extension。
oMLX:把 Mac 變成本地 LLM 控制台

oMLX 是一個針對 Apple Silicon 的本地 LLM 推理工具,也是帶有圖形介面與 CLI 的伺服器管理項目。它主要解決的不是「能不能跑模型」,而是怎樣在 Mac 上較穩定地管理多個模型、保留 KV cache,並減少重複計算帶來的等待時間。
這個項目的取向很明確:用選單列介面處理常見操作,再配合終端機與 Apple Shortcuts 控制同一個服務。安裝路線亦相當直接,macOS 用戶可透過 .dmg 安裝,另有 Homebrew 方式;日志位置、背景服務與 CLI shim 都已交代,對需要長時間開著本地模型的人較友善。
Finally, The CORRECT Way to Run Local AI on a Mac

它和一般本地 LLM server 的差異,在於分層 KV cache 設計。oMLX 把常用內容留在 RAM 的 hot tier,不夠位時再轉去 SSD 的 cold tier,並以 safetensors 格式保存;即使伺服器重啟,遇到相同前綴內容仍可重用快取,這對長對話、編程輔助和工具調用尤其有價值。
只需點擊一下,即可直接從管理面板設定 OpenClaw、OpenCode、Codex、Hermes Agent、Copilot 和 Pi。無需手動編輯配置。
- 支援 hot tier(RAM)與 cold tier(SSD)分層快取
- 可自動以 LRU 方式卸載較少使用的模型
- 管理介面可手動 load/unload 模型
- 提供選單列操作、CLI 與 Apple Shortcuts 整合
- 適合需要長上下文與多模型切換的 Mac 工作流程
現有資訊提到 continuous batching、context limits 與基準測試頁面,但 README 片段未列出具體數字,所以性能判斷宜保持審慎。可確定的是,它較適合在本地做持續開發、配合 Claude Code 一類工具,並集中管理「常駐小模型+按需切換大模型」的團隊或個人環境;相關模型方面,內容明確提到 everyday models、heavier models,以及可選的 GLM-5.2、MiniMax M3 原生 custom kernels 支援。
拆解 AI Agent Loop 核心運作

這是一段介紹 AI Agent 底層控制流程的教學影片。它主要用來解釋主流 Agent 為何能連續思考、調用工具並完成任務,核心其實是一個簡化版 while 迴圈。
內容重點不是堆砌框架名詞,而是把 Agent Loop 拆成幾個基本步驟:先問模型、按模型要求執行工具、把結果回填,再繼續詢問模型,直到模型不再要求工具。這種講法有助非技術讀者理解,很多看似複雜的 AI Agent,底層控制流未必複雜。
它要處理的問題,是怎樣讓語言模型由一次性回答,變成可逐步執行任務的系統。相比只靠單輪提示詞的做法,Agent Loop 多了狀態延續、工具調用與停止條件,因此更適合查資料、操作 API、分步完成工作等情境。
- 核心概念:Agent Loop 可視為模型與工具之間的反覆回合
- 主要流程:模型決定下一步,系統執行工具,再把結果交回模型
- 關鍵價值:把複雜 Agent 拆成可理解、可實作的最小控制單位
- 適用情境:想學 AI Agent、工具調用、任務自動化流程的人最受用
這類內容特別適合剛接觸 Agentic 系統、MCP、工具代理或自動化工作流的讀者,也適合寫程式的人建立正確心智模型。單靠目前提供的資料,未見具體效能數字、基準測試或完整程式實作細節,因此較適合視為概念導讀,而不是完整技術文件。
AgenticDataBench:數據代理基準點樣睇

AgenticDataBench 是一個用來評測 data agents 的 benchmark,而唔係直接幫人做分析的模型或應用。它要解決的是:LLM-based data agents 能否穩定完成 data science workflow,並且用可比較、可重現的方式量度表現。
現有做法多數只用零散任務、單一資料集,或者只看最終答案,較難知道代理究竟卡在哪個步驟。這個項目改用 344 個任務、15 個領域,再配合細緻的 skill labels 同 ground-truth,將問題拆成可重用的 data science skills,例如缺失值處理一類操作模式,令評測唔只得總分,仲可以見到技能層面的強弱。
部署同理解方式都幾直接:資料集可由 HuggingFace 下載後放入 testbed/datasets/,任務、gold 標註同結果目錄已經分開,另外保留咗 98 個 private test tasks 維持 leaderboard 的可信度。README 亦提到需要設定 API keys,反映它主要係一個開放測試台,方便用不同 agent harness 跑同一批任務,而唔係單機即開即用的終端工具。
同類 benchmark 相比,它的取向唔係追求最少題目下的快速排行,而係強調真實性、技能覆蓋率同冗餘控制。項目一方面收錄真實 B2B fintech use cases,另一方面用 skill-aligned hierarchical clustering 同系統化生成流程補足缺少真實任務的領域,這種做法的代價是建置與維護較重,但換來更完整的比較基線。
- 覆蓋 15 個領域,包含真實 B2B fintech 任務
- 提供 tasks、ground-truth、skills 同 results 結構化內容
- 支援比較不同 agent harness,如 Smolagents、DA-Agent、Claude Code、CodeX
- 已列出 Qwen3.5-397B-A17B、Kimi-K2.5、Claude Sonnet 4.6 的初步實驗
這個項目最適合做 data agent 研發、模型選型同內部驗證的團隊,也適合研究人員用來檢查代理在哪類 data skills 失分。性能資訊目前以 leaderboard 結果為主,重點不只是 accuracy,仲包括 skill-level insight;相關模型至少包括 Qwen3.5-397B-A17B、Kimi-K2.5 同 Claude Sonnet 4.6。
Graph-GRPO:教模型先畫知識圖再作答
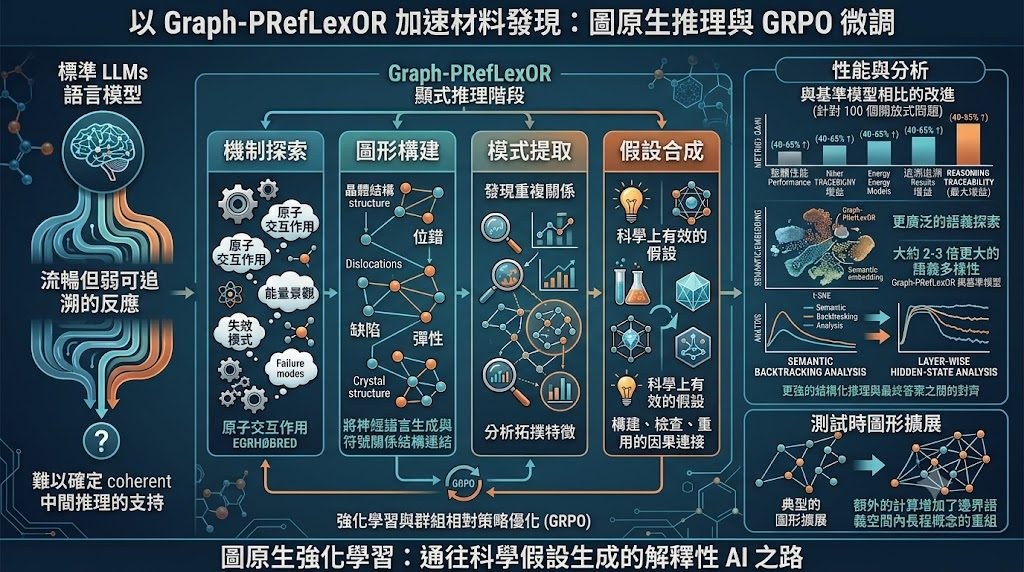
這是一個用來訓練語言模型的推理項目,核心屬於模型訓練流程兼研究原型。它要解決的問題,是模型回答問題時往往只輸出文字結論,推理結構難以檢查;Graph-GRPO 先要求模型把概念、關係與規律整理成 knowledge graph,再整合成答案。
現有做法多數依賴 chain-of-thought 或一般文字式 reasoning,把中間思路寫成自然語言。作者認為這種範式雖然靈活,但節點、因果、約束與抽象規律不易固定表示,因此提出 graph-native 的訓練方式:先用 ORPO(Odds Ratio Preference Optimization)或 SFT(Supervised Fine-Tuning)學格式,再用 Graph-GRPO 做強化學習,直接獎勵正確性、格式完整度與 graph utility。
項目的設計相當明確:節點類型限制為 entity、attribute、process、event、outcome、law、claim,關係亦只保留 12 種 verbs,並用 Pydantic 做結構化解析與 schema validation。這種取向的好處是輸出較易驗證,甚至能自動修補無效 graph;代價是表達自由度較低,未必適合非常開放、需要細膩語氣或鬆散聯想的回應。
部署與理解方式也算清楚,整個流程分成資料生成、run_orpo_graph 或 SFT 訓練,再進入 run_grpo_graph 強化階段,並以 LoRA 疊加在基礎模型上。README 亦提到可透過 OpenAI-compatible endpoint 驅動 ideation engine,把多輪生成的 graph_json 累積成可擴展知識圖,用於創意探索、問題延伸與比較不同前沿模型的表現。
- 適合想研究可追蹤推理、結構化回答與可驗證中間步驟的團隊
- 已釋出相關模型,基礎模型包括 Qwen-8B 與 Llama-3.2-3B-Instruct
- 獎勵設計公開列出 correctness、format、graph utility 三部分權重
- 亮點不在單純答得快,而在於把 reasoning 過程轉成可檢查的 graph object
在目前提供的內容中的性能不算完整,較明確的是訓練路徑、輸出結構與後續 ideation 用途,而 supporting context 另提到這條路線也延伸到 scientific hypothesis generation。整體來看,這個項目較適合研究型開發者、做 Agentic workflow 的團隊,以及想把 LLM 回答過程由黑盒文字轉成結構化證據鏈的人使用。
Hermes MoA 協作提升答案質素

這是 Hermes MoA(Mixture of Agents,混合代理)架構。它的主要用途是讓多個 Large Language Models 同時回答同一條問題,再由一個聚合者整合各自較強的部分,輸出單一答案。
MoA 的重點不在於訓練一個新模型,而是把多個現有模型疊成一個協作流程。文件指出它依靠多樣性、互補性與聚合三個機制運作:不同模型會走出不同推理路徑,彼此可以補足盲點,最後再由較強的模型統整結果。這種做法和只用單一模型相比,目標是提升複雜任務的回答質素。
在 Hermes Agent 內,這個項目提供三種落地方式:shell 腳本、delegate_task 與 Kanban。Shell 版本最直接,做法是先把多個 proposer 的回覆收集起來,再交給 aggregator 讀取並重寫成最終答案,較適合快速驗證流程;另外兩種方式則較適合需要更穩定管理的工作流。
文件亦清楚交代取捨。MoA 的成本大約是 N+1 倍,延遲通常接近最慢 proposer 再加 aggregator 的時間,所以不適合簡單問答;但對需要比較、整合、推理的任務會更有價值。頁面同時提到在 AlpacaEval 2.0 可帶來約 65% lift,而 proposer 數量以 3 至 5 個作為較理想的平衡點。
- 核心流程是平行提議者 + 單一聚合者
- 主要價值在於結合不同模型的長處
- Hermes Agent 支援 shell、delegate_task、Kanban 三種實作
- 成本與延遲明顯上升,較適合複雜任務
- 示例有 anthropic/claude-sonnet-4、openai/gpt-4o、google/gemini-2.5-pro、deepseek/deepseek-chat
適合想在現有 LLM 工作流上疊加協作機制的人閱讀,尤其是需要提升答案穩定性、綜合能力或多角度分析的場景。它不是單一模型的介紹,而是一種可直接套用在 Hermes Agent 的編排方法。
Headroom:幫 AI agent 壓縮上下文

Headroom 是一個給 AI agents 與 LLM 應用使用的庫兼代理工具,核心角色是把送進模型前的上下文做壓縮。它主要解決長對話、工具輸出、日誌、RAG 片段與檔案內容太長,令 token 成本、延遲與上下文容量很快爆滿的問題。
這個項目不只提供 Python 與 TypeScript 內嵌式 compress(messages) 用法,亦提供 proxy 模式與 MCP server,代表它可以直接插入現有流程,未必需要大改程式。README 提到 zero code changes 的代理方式,對已有多語言系統的團隊尤其實用;另外它走 local-first 與 reversible 路線,取向明顯是先保留可控性,再追求節省 token。
和一般只縮短輸入文字的做法相比,Headroom 的差異在於它同時處理模型輸出,會減少重複客套、重述程式碼,以及在例行步驟略過過深的「thinking」。這種取捨有助壓低來回 token,但也代表較依賴它對內容重要性的判斷;對需要完整推理痕跡或逐字保留輸出的流程,部署前應先做回歸測試。
結果列出的數字是 60–95% fewer tokens,示例亦有 10,144 壓到 1,260 tokens,同時保留相同問題結論;不過這些結果較適合視為官方展示,具體效果仍會受任務類型影響。較容易受益的情境包括多步驟 agent、跨工具調用、RAG 對話系統,以及 Claude、Codex、Gemini 之間需要共享記憶的團隊協作流程。
- 支援 Library、Proxy、MCP server 三種接入方式
- 可壓縮對話、工具輸出、logs、RAG chunks 與檔案內容
- 提供 cross-agent memory,支援 Claude、Codex、Gemini 共用與去重
headroom learn會整理失敗 session,寫入 CLAUDE.local.md、CLAUDE.md、AGENTS.md 或 GEMINI.md- 相關模型包括 Kompress-v2-base,而整體定位較接近 agent 基礎設施,不是單一聊天模型
整體來看,Headroom 最有價值的地方不在於再做一個包裝 LLM 的介面,而是把「上下文壓縮」獨立成基礎層。對經常被 token 成本、上下文長度與 agent 記憶雜訊拖慢的項目,它屬於值得優先測試的一類工具。
OpenMontage:AI 代理拍片流程
OpenMontage 是一個開源、Agentic 的影片製作工具型項目。它的核心任務是把研究、寫稿、素材生成、片段檢索、剪輯到輸出成片串成同一條流程,讓 AI coding assistant 代為協調整個製作過程。
這個項目最值得留意的地方,在於它不把「幾張靜態圖加動畫」當成影片的唯一做法。它亦會從免費 stock footage 與公開影像檔案建立 corpus,抽取真正的 motion clips,再放入時間線完成合成,取向上比純 txt2img 或 image-to-video 工具更接近剪輯工作流。
部署理解上,現有資料顯示它依賴 FFmpeg,以及 Claude Code、Cursor、Copilot、Windsurf、Codex 這類 AI coding assistant。換句話說,它不像一般單一網頁服務,更像一套由代理驅動的製片管線;測試時較合理的方式,是先用簡單 prompt 驗證腳本規劃、素材來源、成本預估,再觀察最後能否穩定輸出可看的 timeline 與成片。
- 定位清晰:多個生成與剪輯步驟接駁起來的工作流工具。
- 差異明顯:支援真實影片片段檢索與編排,不只依賴靜態圖轉影片。
- 適合情境:內容創作者、小型 marketing 團隊、需要快速做樣片的創意項目會較受惠。
- 取捨存在:自由度高,但效果會受可用模型、素材來源與代理穩定性影響。
它可保留參考影片的節奏、hook style、結構與 tone,同時改動主題、畫面處理、切入角度與旁白方式,亦會在素材生成前估算目標片長成本。性能數字與正式 benchmark 暫未見完整公開,因此現階段較適合視為早期但方向鮮明的製片自動化項目;相關模型與服務例子包括 Veo,以及配合 AI coding assistant 與 Remotion、FFmpeg 一類組件完成輸出。