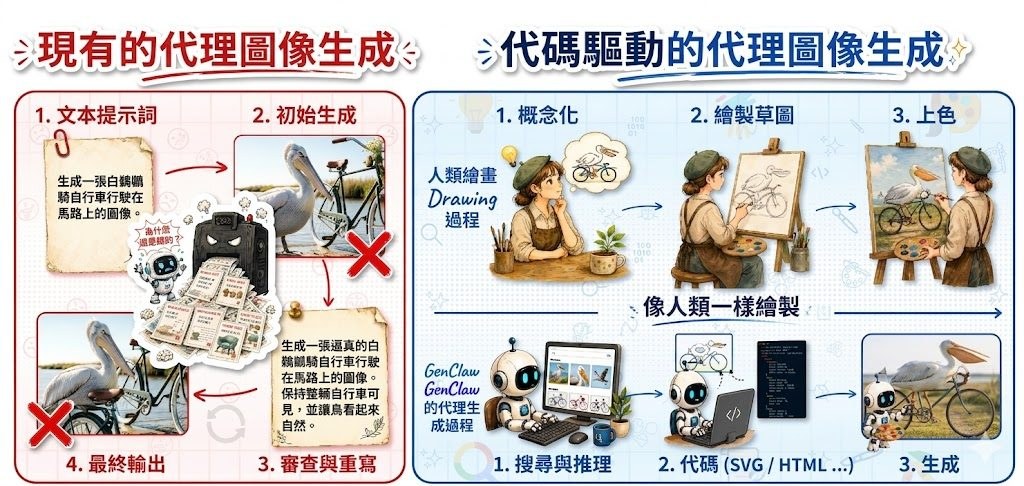
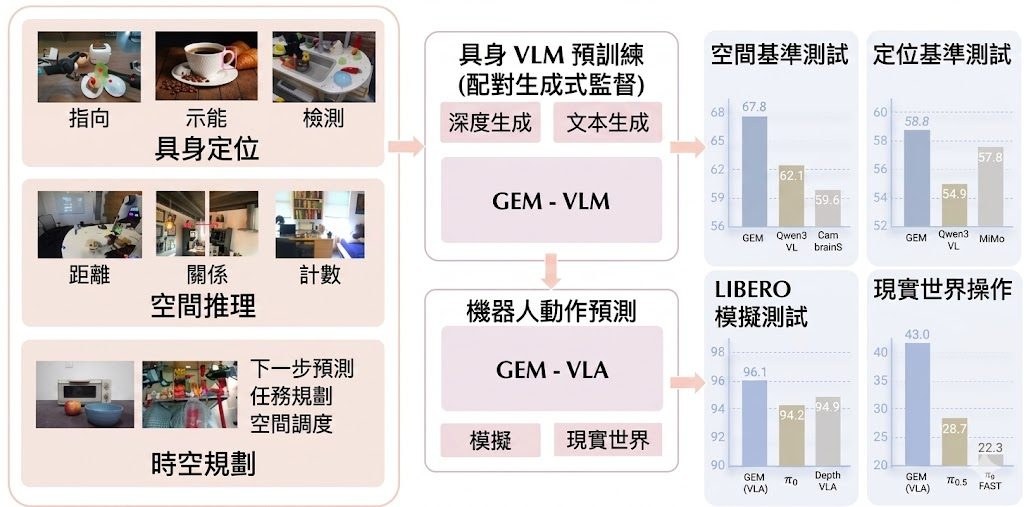
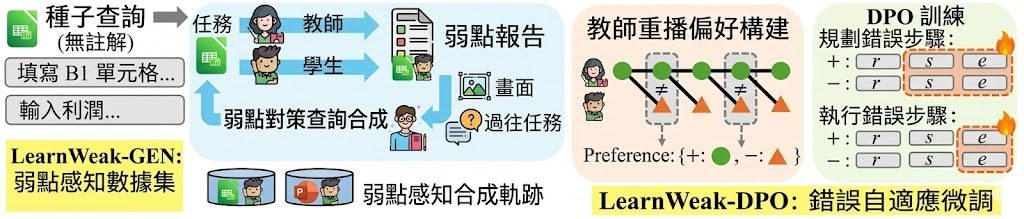
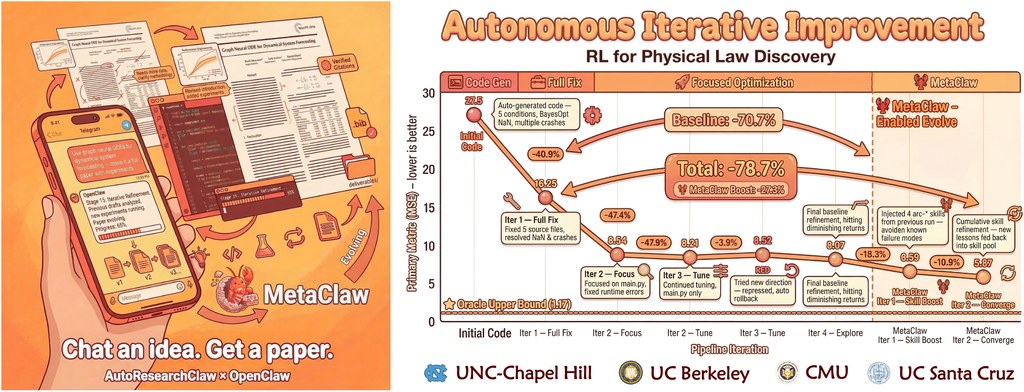
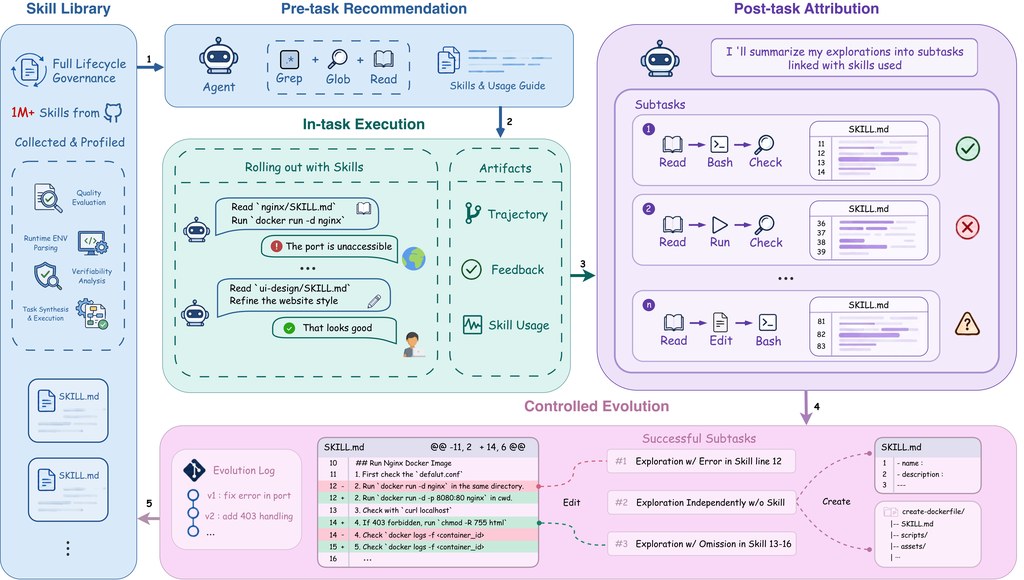
適合的場景包括學術探索、研究提案發想、實驗規劃初稿,以及想觀察 AI 如何拆解研究問題的人。相關比較對象可留意 AI Scientist v2,論文亦直接以 ARC-Bench 作基準比較;若你關心的是代理式研究系統,而不只是聊天機械人,這個項目值得放入觀察名單。不過它產出的內容仍應由研究者覆核,尤其在方法設計、引用與結論判斷上更需要人手把關。
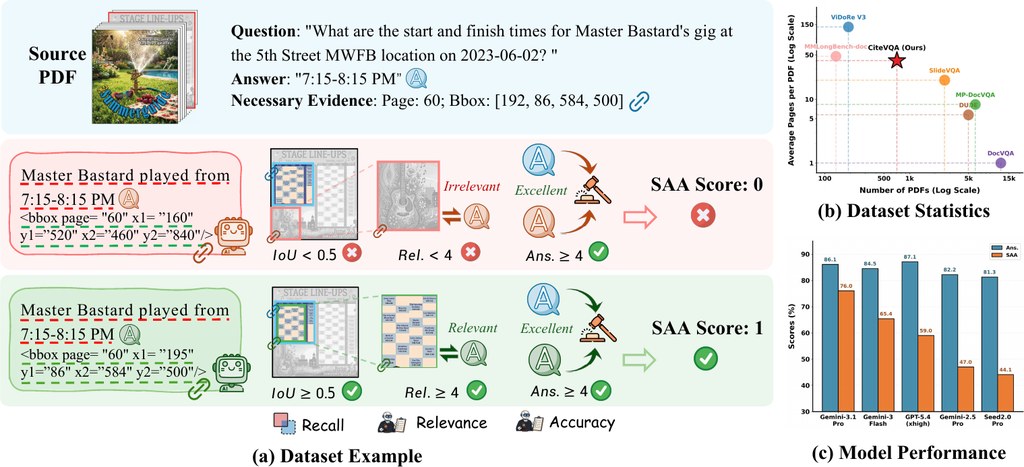
做文件問答評測時,很多工具只睇最後答案啱唔啱,但現實上,尤其是合約、財務報告、醫療文件呢類長篇 PDF,真正重要的是「答案來自邊一頁、邊一段、邊個區塊」。CiteVQA 針對的正正是這個缺口:它不只要求系統回答問題,仲要指出支撐答案的文件位置,而且細到元素層級,例如頁碼同區域框選。對想評估文件 AI 是否可靠的人來講,這比單純比拼答題分數實用得多。
這個專案最值得留意的地方,是它把「答對」與「引對證據」綁埋一齊計分。核心指標 SAA 只有在答案正確,而且引用區域同標準證據對得上時先會得分,能更直接揭示模型有冇出現「講得似乎合理,但引用錯地方」的情況。根據公開結果,即使是表現較強的模型,答案分數與這種嚴格分數之間仍有明顯差距,反映現時不少系統其實未真正做到可追溯。這一點對高風險場景尤其重要,因為用戶要的不只是結論,仲要查得到根據。