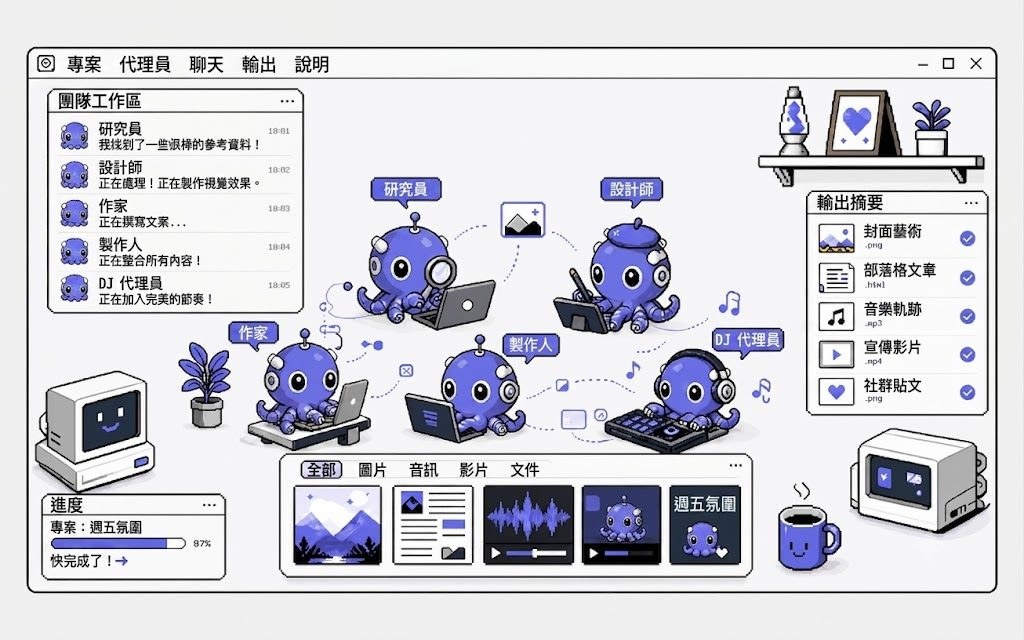
MiniMax 把原有 Agent 升級並命名為 Mavis,重點是加入 Agent Teams,讓多個 Agent 在桌面版同時運行,並以不同角色分工合作。這個方向主要處理單一 Agent 面對長任務時容易同時做執行者與裁判、資料整理與事實核對混在一起的問題。
過去把一個複雜要求直接交給單一 AI assistant,回覆速度可以很快,但當內容需要最新資料、來源整理、格式輸出與結果驗證時,流程便容易失焦。Agent Team 的做法是把任務拆成前台與後台、有驗收、有記憶的工作流;用戶仍然只需輸入一個要求,系統再判斷是否拆解、哪些角色可並行、哪些結果需要覆核。
對一般用戶而言,這項目最易理解的用法,是把它視為一個可分工的 AI 工作團隊。若你要處理長篇內容整理、跨格式輸出,或需要連續跟進的知識工作,Mavis 會比單一 Agent 更合適;如果只是一次性的小任務,官方亦暗示未必需要動用 Agent Team。
- 支援多個 Agent 並行,適合長時間與複雜任務
- 可建立不同角色分工,提升整理、驗證與交付流程
- 用戶只需提供一次指令,系統會自行判斷是否拆解任務
- 整合 TokenPlan 與 Agent Plan,CLI、API、Agent 共用訂閱與 credits
另一個更新是把 TokenPlan 與 Agent Plan 合併成單一訂閱,涵蓋 CLI、API、Agent,以及 M2.7、music、video、voice 等能力,credits 亦可共享。對已同時訂閱兩個計劃的用戶,官方表示會補送一個月會籍。這次內容未見具體跑分或量化基準,重點更偏向產品工作流與使用體驗的重整。
項目: https://www.minimax.io/blog/minimax-agent-team-long-running-1779893953