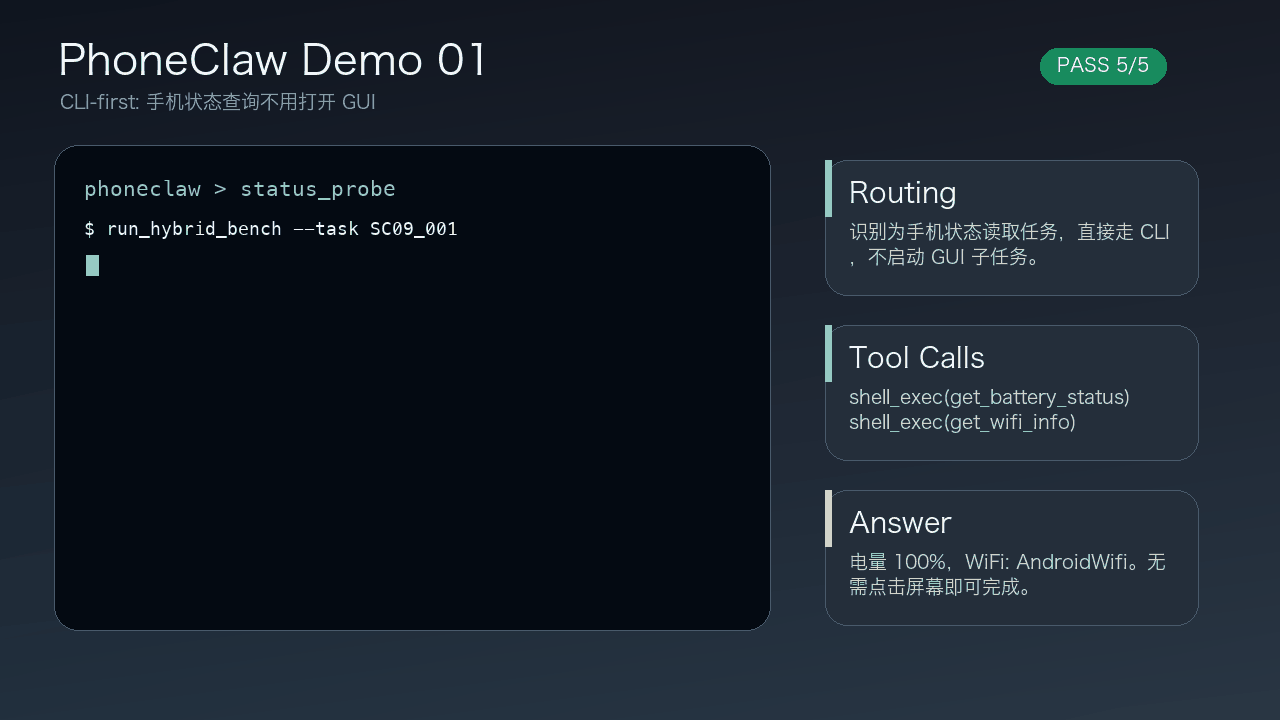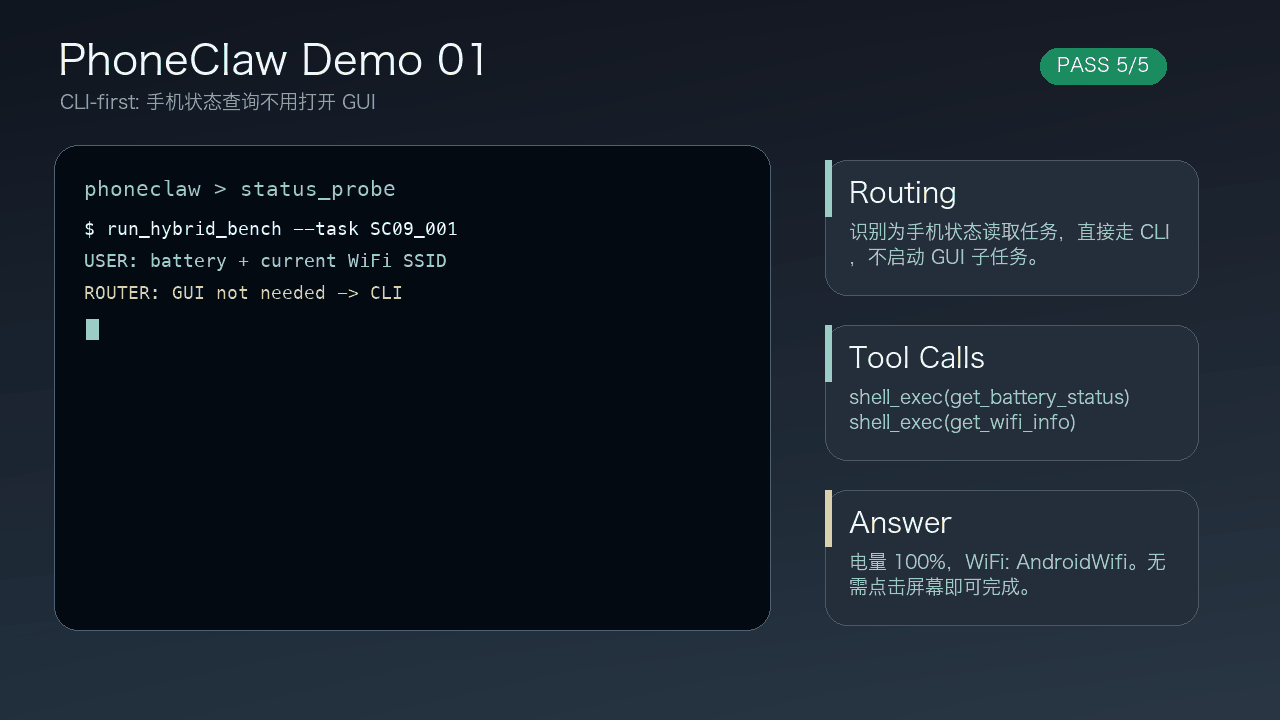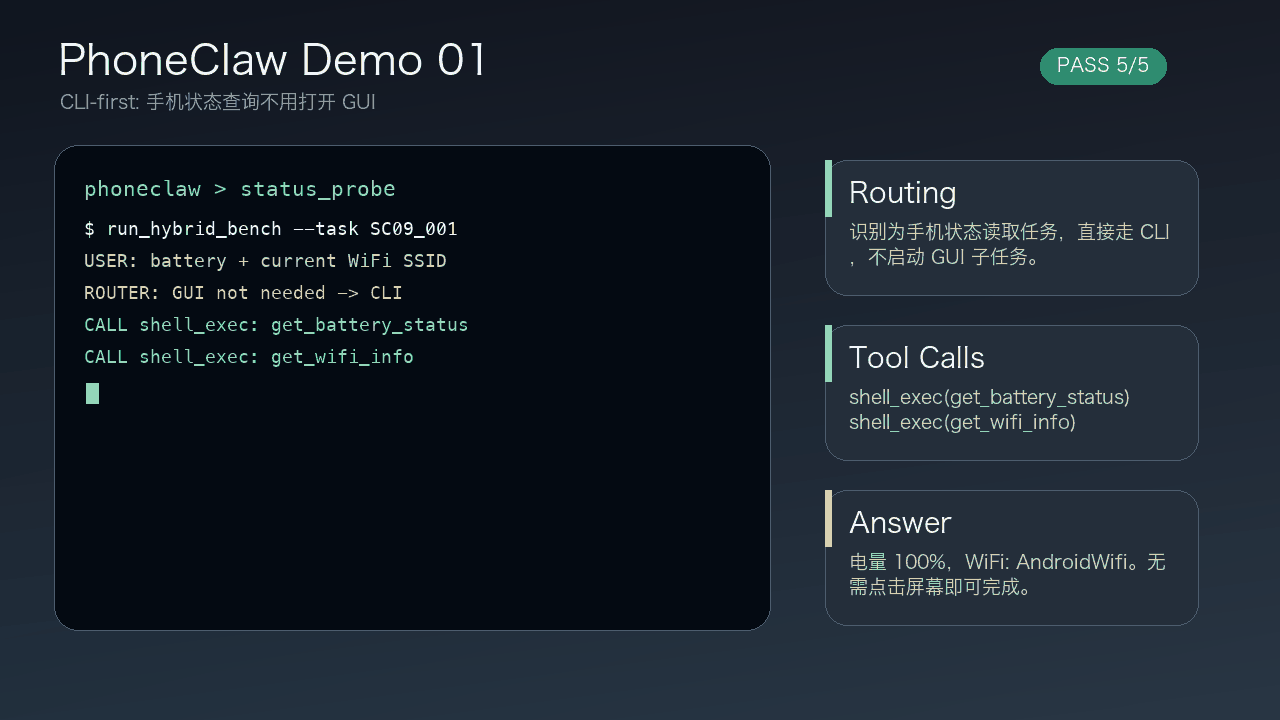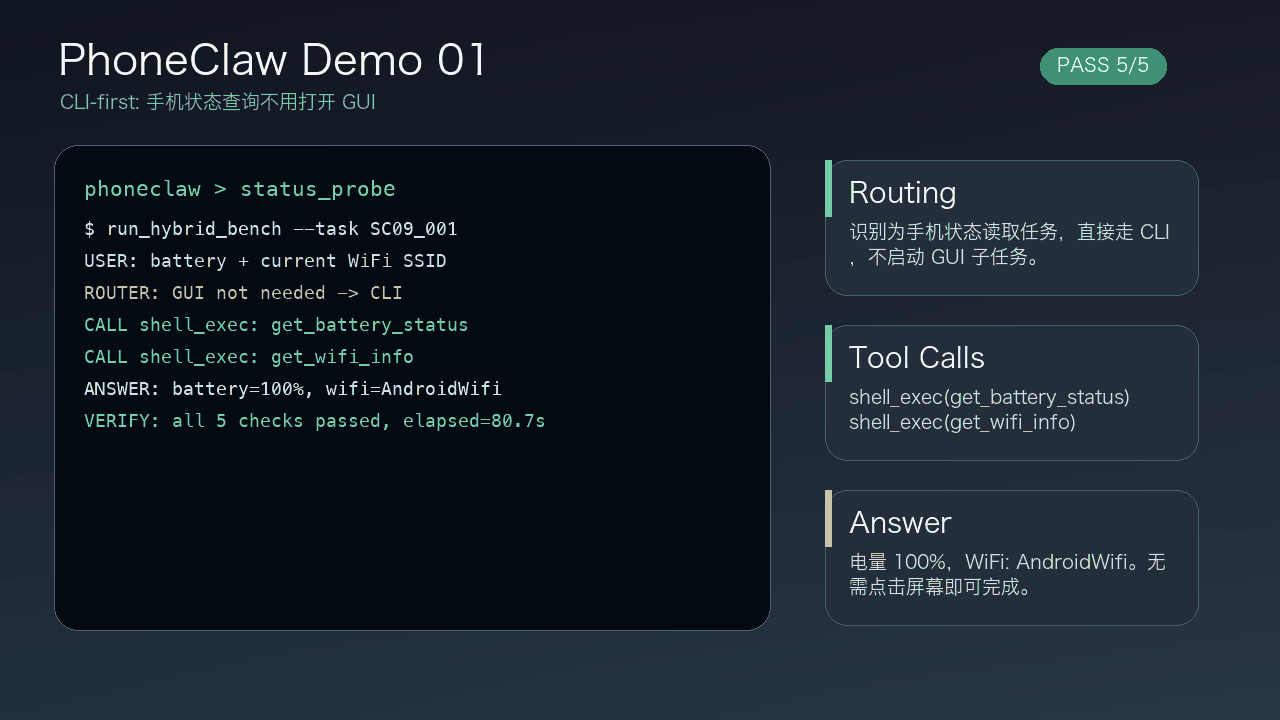
TVEdit 是一個圖像編輯項目,目標是解決「只靠文字講意思,或者只靠拖點講位置」都不夠準的問題。以往文字指令較易表達語意,但難控制空間;點拖軌跡可以指位置,卻容易令語意變得含糊,所以作者把兩者合併成 Text-Vision Co-Instructed Image Editing。
這項目的做法是用一個文本與視覺指令配對資料集來訓練,資料超過 23K 筆,來源與動態影片有關。再配合 TV-Edit 框架,把拖曳或點選等視覺指令轉成更有語意的控制表示,然後接到預訓練編輯骨幹上,例如 Qwen-Image-Edit。
它能同時處理「想改成什麼」與「要改到哪裡」,而不是只偏重其中一邊。作者另外建立了 TV-Edit-Bench,專門看語意忠實度、空間對齊同畫面一致性,這比一般只看最終效果的做法更能反映模型有沒有真正聽懂指令。
先載入 Qwen-Image-Edit,再配 TV-Edit 權重,之後在 Gradio 介面上上傳圖片、畫出軌跡、輸入文字指令,再調 CFG 同步數生成結果。若有加速 LoRA,步數可以大幅減少,適合想快速試驗互動式編輯的人。
- 結合文字語意與點拖軌跡,令空間控制更細
- 用 23K+ 配對資料補足跨模態指令訓練
- TV-Edit-Bench 同時看語意、位置、畫面一致性
- 目前已提供推理程式、模型權重同網頁示範
- 適合做互動式圖片編輯、研究評測或模型整合