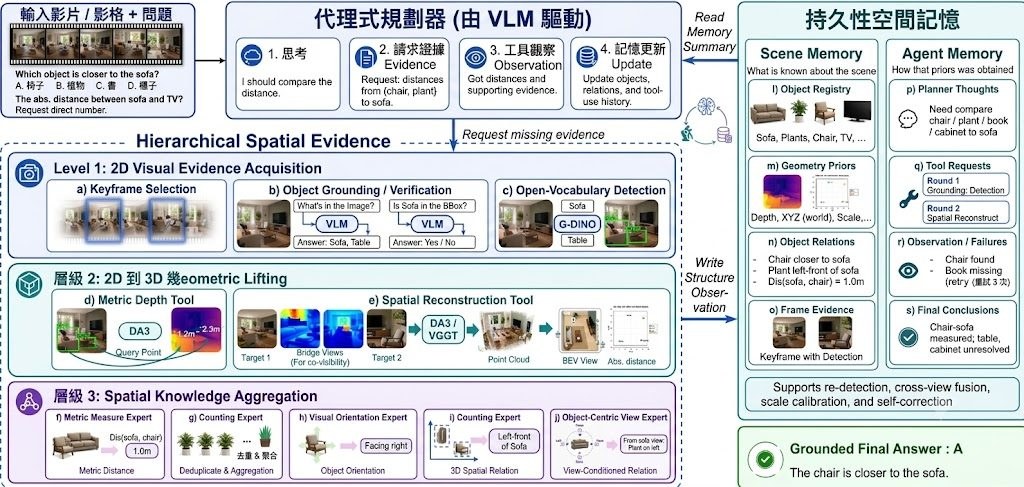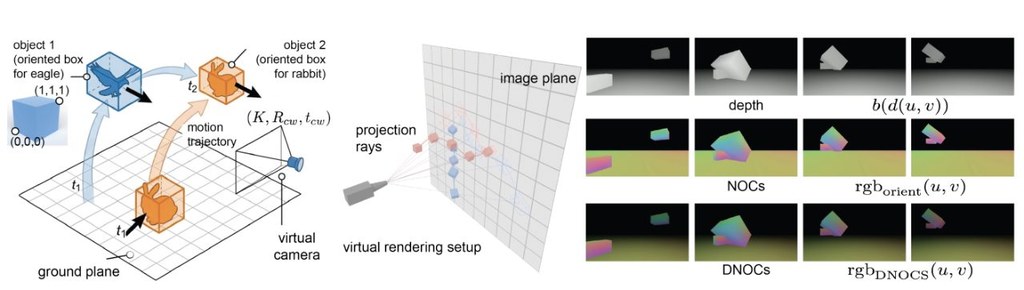
LooseControlVideo(LCV)是一個針對影片生成與編輯的框架,核心做法是用稀疏、帶方向的 3D boxes 來安排物件移動、旋轉、遮擋關係,以及鏡頭運動。它想解決的,是多物件場景中「位置安排」與「時間變化」經常纏在一起,令文字轉影片很難精準控制。
常見控制方法多數依賴 dense depth maps、optical flow 或 3D point tracks,雖然細緻,但要逐格準備條件,製作成本高。LCV 改用人手較易繪製的 3D boxes,讓使用者先定出高層次 blocking,再交由生成模型補足自然的動態、互動與遮擋,控制感和自由度之間取得較好平衡。
技術上,項目以 Wan 2.2 backbone 為基礎微調,並配合 DNOCS 這種編碼方式,表示 3D 尺寸、方向及按深度排序的遮擋資訊。頁面亦提到它支援局部修訂,例如只調整跳躍軌跡,或加入新的互動,而不必大幅破壞整體場景。
重點可先看這幾項:
– 可控制軌跡、旋轉、遮擋、鏡頭運動與局部編輯
– 輸入形式是稀疏 oriented 3D boxes,較易手動建立
– 適合多物件場景與需要導演式安排動作的影片生成
– 在 nuScenes、HO-3D、BEHAVE 上,優於 2D-box 與 flow-based baselines
– 指標上約有 1.2 至 3 倍 Trajectory Error 改善、2 倍 Rigid Motion Consistency 改善,以及 1.5 至 2 倍 Occlusion Accuracy 提升
這類方法特別適合想精準安排角色走位、物件互動,或需要補拍式修改片段的人。現有資料主要展示項目頁與結果示例,若讀者想接觸這個項目,較可行的做法是先觀察它如何用少量 3D boxes 改動單一動作,再比較與傳統 layout-conditioned models 在遮擋與旋轉控制上的差別。