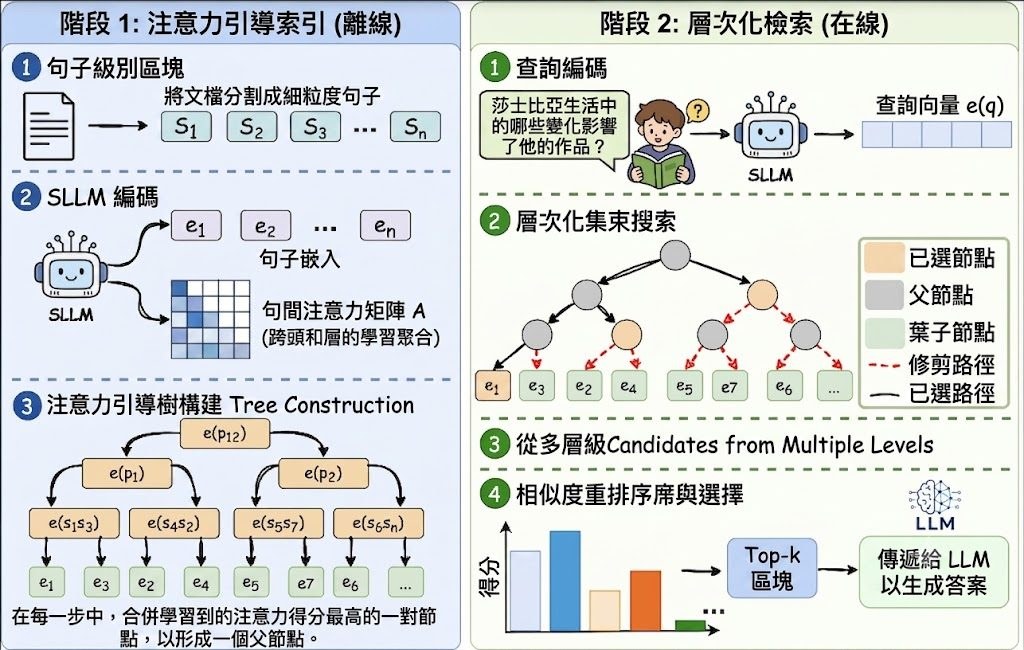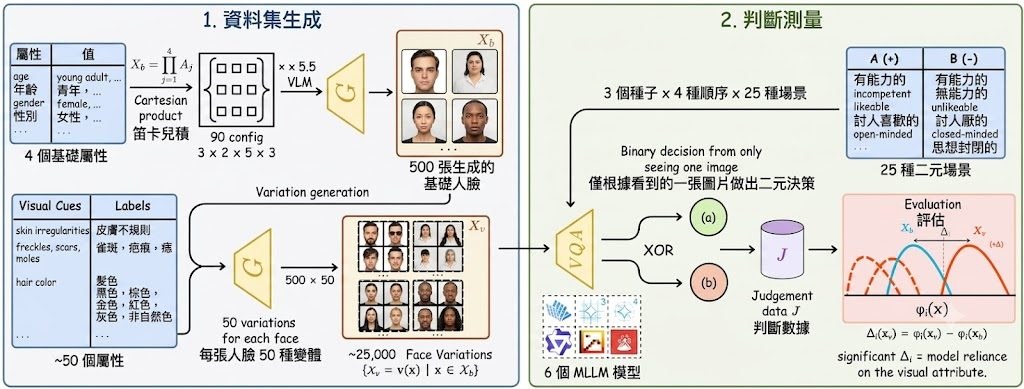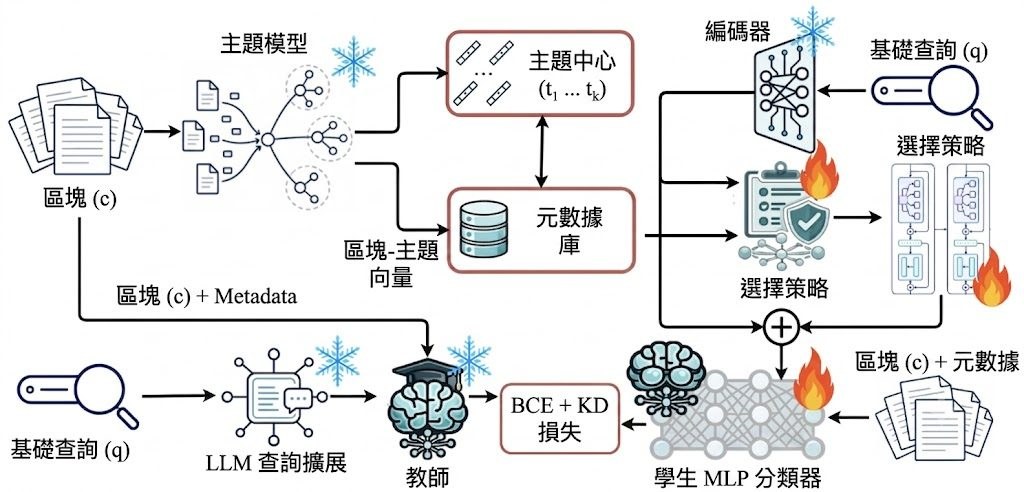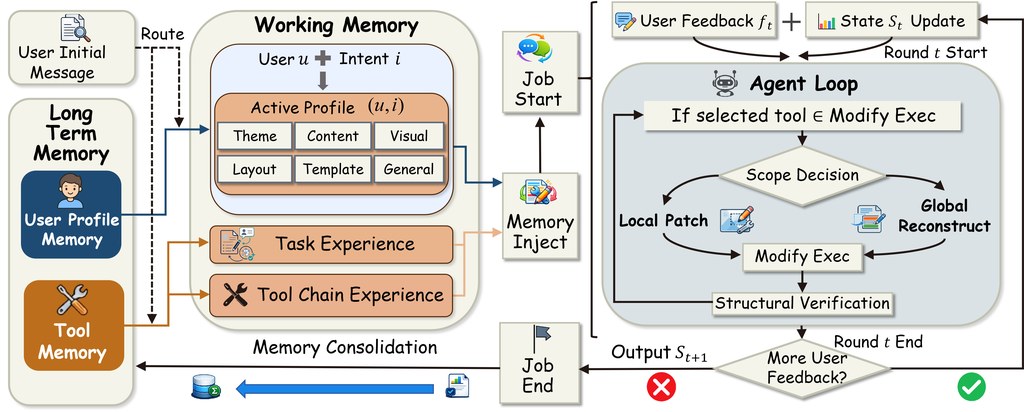
這是一個面向多模態資料整理的研究原型兼框架,核心是用 Agentic Data Tailoring 把原始串流資料重組成有結構、可驗證、可直接用於訓練的 supervision。它要解決的不是「再做一次標註」,而是長影片、GUI traces、embodied trajectories 與 editing sequences 太雜亂、資訊密度不均,令人和模型都難以有效吸收。
現有做法多數依賴 passive annotation paradigms,用 heuristic rules 或 general VLMs 被動加標籤;作者認為這類方式成本高、內容單調,亦抓不到原始資料入面的 procedural logic。DataClaw0 改用「Bottom-up Factual Anchors → Top-down Semantic Synthesis」兩段式流程,先抽取較確定的 factual anchors,再按意圖生成結構化語意,重點在於它不是只描述內容,而是按 downstream objective 重寫資料。
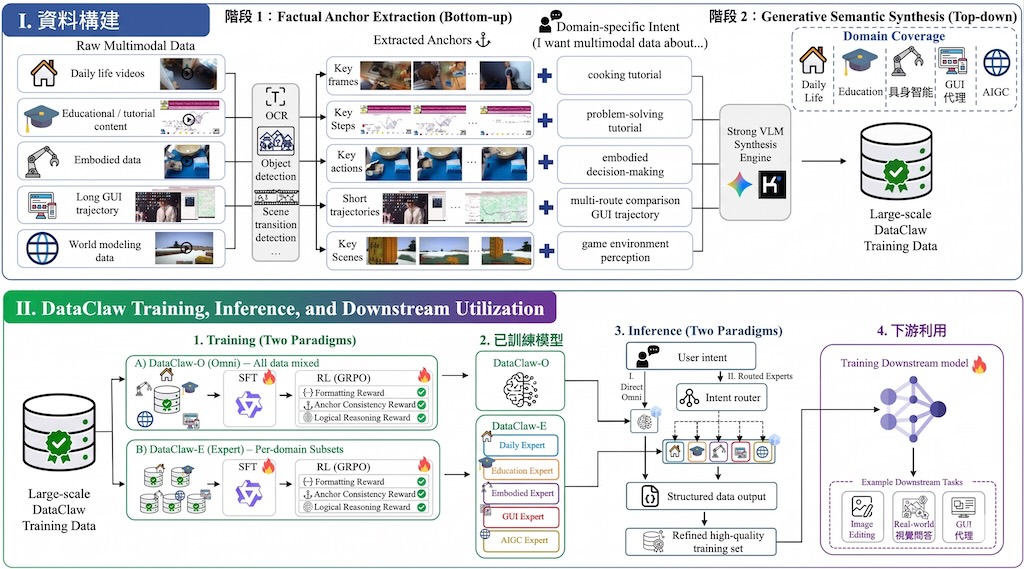
模型層面,項目提出 DataClaw-9B,並以 Supervised Fine-Tuning(SFT)加 rule-driven Group Relative Policy Optimization(GRPO)做對齊;部署上分成 unified Omni model 的 DataClaw-O,以及分領域 Experts 的 DataClaw-E。這種取向的取捨很明顯:Omni 較方便統一處理多域資料,Experts 則較可能在特定場景保留更細緻的領域表達。
現階段先看論文與案例再判斷是否值得追蹤,因為 code、model weights、dataset 和 DataClaw-val benchmark 仍未正式釋出。已公開資訊顯示,它的評測不只看生成是否通順,還會檢查 JSON validity,以及 schema-aware 的 Field、Semantic、Sequence 指標,並再用 video generation、real-world VQA、GUI navigation 的下游 post-training 效果驗證資料整理是否真的有用。
- 項目類型:研究原型/資料整理框架,重點是把原始多模態串流轉成意圖對齊的訓練資料
- 主要差異:不是被動標註,而是主動 refinement,並保留 schema-conformant、verifiable 輸出
- 相關模型:DataClaw-9B、DataClaw-O、DataClaw-E,訓練結合 SFT 與 rule-driven GRPO
- 適合情境:做多模態 post-training、GUI agents、VQA、影片或 embodied 資料整理的團隊
如果你關心的是建立資料引擎,而不只是找一個模型做推理,DataClaw0 比一般 VLM 標註流程更有方向性。限制也很直接:目前公開內容以論文與項目頁案例為主,能否重現效果、部署成本多高、不同領域泛化有多穩,仍要等正式釋出的資料與基準再作判斷。
GitHub: https://github.com/vancyland/DataClaw0