現時不少 AI 圖片編輯工具,表面上改得唯肖唯妙,細看卻經常出現「睇落合理、其實犯駁」的情況。來自浙江大學 ReLER Lab 與香港大學的團隊推出 RE-Edit,正是針對這個盲點而設計的基準測試。
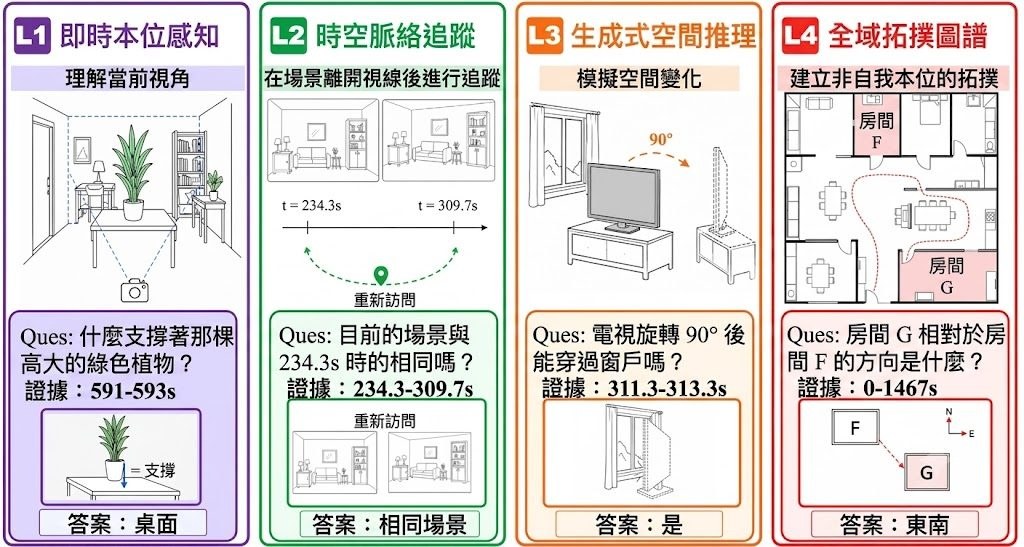
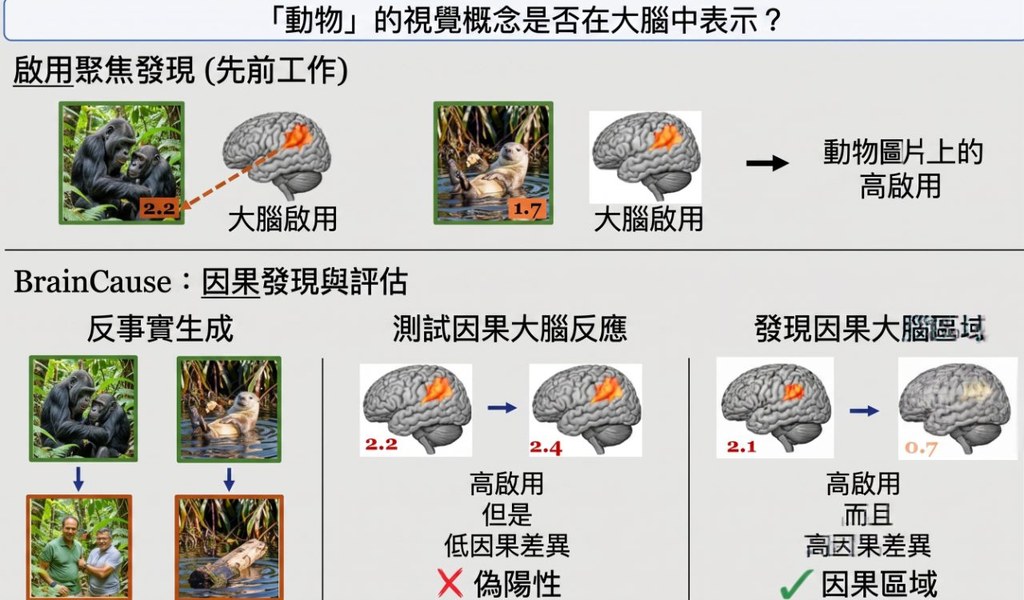
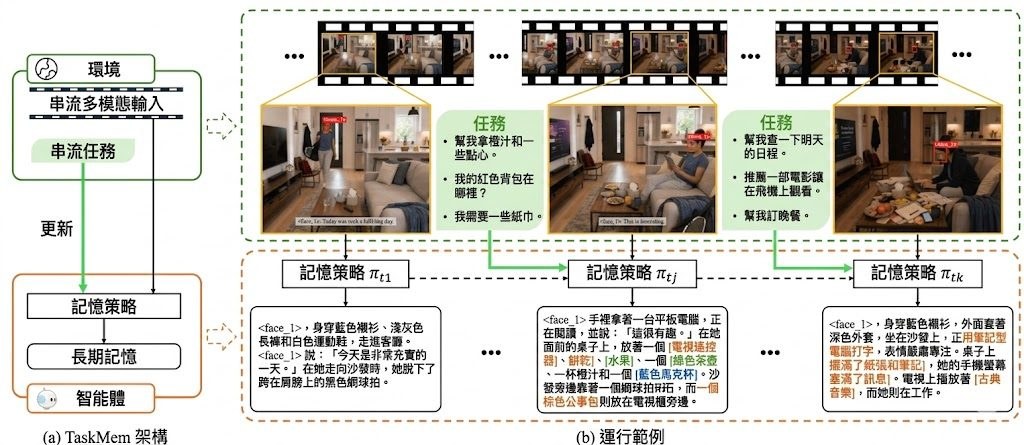
RE-Edit 全名為 REasoning-aware image Editing,包含 1,000 個精選樣本,並劃分成五個推理維度:物理(physical)、環境(environmental)、文化(cultural)、因果(causal)和指涉(referential)。每一條題目都刻意設計成「畫面睇落合理,但忽略了潛在邏輯」的情境,用以測試模型能否理解指令背後的隱含限制。
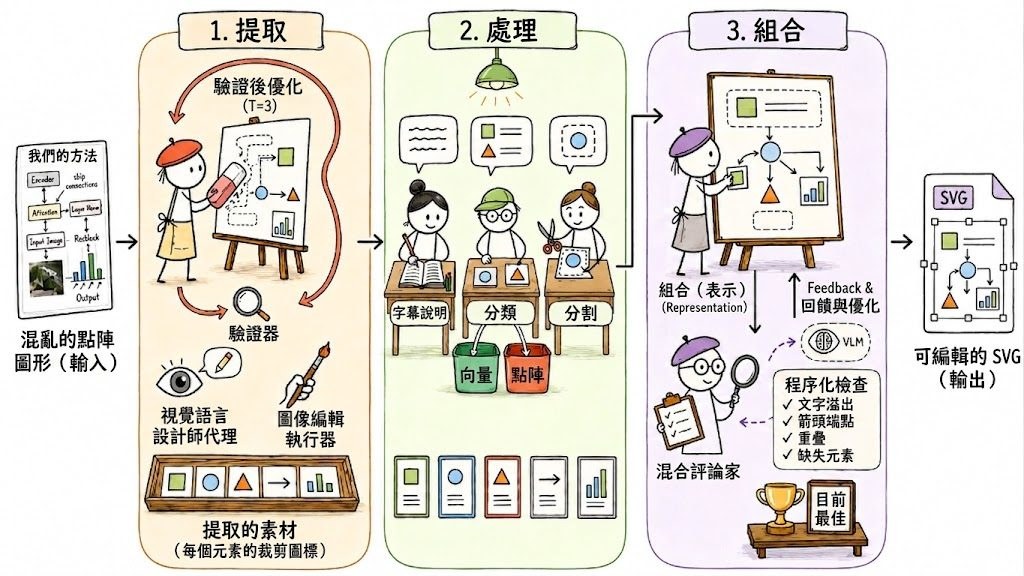
配合基準,團隊亦提出輕量級的後修補方案 EditRefine。做法是先讓多模態大型語言模型(MLLM)診斷初稿失敗之處,再產生帶有思維鏈(chain-of-thought)的重新編輯指令,由原本的擴散模型執行。這個「診斷—重做」流程可以套用在 FLUX.2 Dev、Qwen-Image-Edit 等不同執行器上,毋須重新訓練底層模型。
整套系統以 YAML 設定檔驅動,輸出會保留原圖、初稿、EditRefine 修補稿、chain-of-thought 文本以及重新編輯指令,方便逐個維度比對。對從事 AI 圖像編輯研究、產品測試或內容審核的團隊而言,RE-Edit 提供了一個可量化邏輯錯誤的測試場;對一般讀者來說,它提醒我們「改張相」背後其實牽涉文化、物理因果等多重常識。
重點摘要
- 1,000 個樣本橫跨五個推理維度,專門捕捉「畫面合理但邏輯犯駁」的失敗案例。
- EditRefine 以 model-agnostic 方式插入推理步驟,可搭配 FLUX.2 Dev、Qwen-Image-Edit 等不同模型使用。
- 評審採用 Qwen3-VL-30B 對 IF、SC 等指標作自動化判分。
- 設定檔以 YAML 管理,輸出包含初稿、refined 稿、CoT 文本與重編指令,方便追溯。
- 適合研究 AI 圖像編輯、內容審核及多模態推理的團隊作為統一基準。