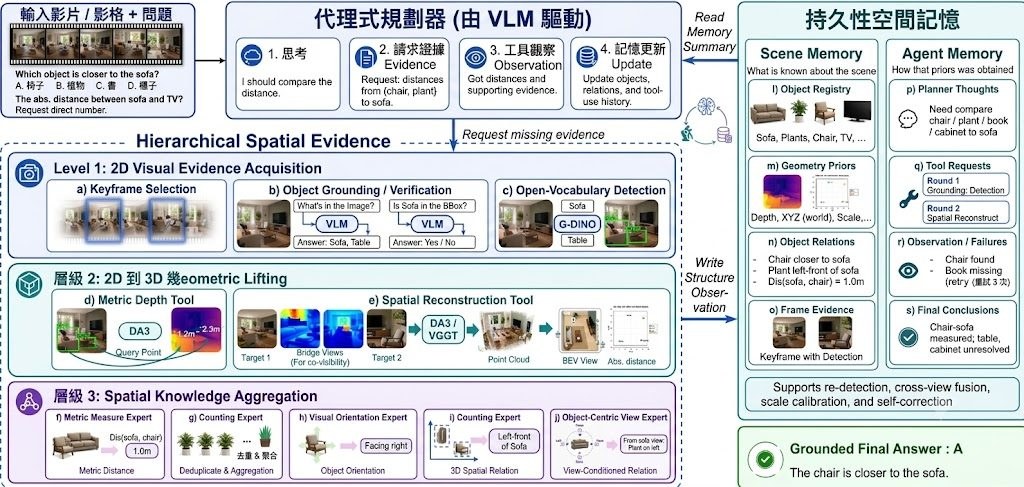
現時不少 Vision-Language Model 都偏向用單張圖片、單步回答去做空間判斷;就算加入 agent,也常見為 stateless inference,缺少持續記錄場景變化的能力。S-Agent 提出的做法,是把空間推理改寫成 spatio-temporal evidence accumulation:不是即時猜答案,而是逐步收集 2D、3D 和時間序列證據。
這是一個偏向 Agentic 視覺推理框架 的研究項目,目標是解決多視角圖片與影片中的 3D 空間理解問題。它把 Vision-Language Model 當成 semantic planner,再配合 hierarchical spatial tools、Scene Memory 與 Agent Memory,處理 counting、measurement、orientation、relative position 這類單幀方法較易出錯的任務。
同類做法多數停留在 frame-level prediction,S-Agent 的取向明顯不同:先 grounding 物件,再做 2D-to-3D lifting,之後把幾何線索整合成可推理的 scene-centric understanding。這種設計的代價,是系統比單次問答複雜,亦更依賴工具鏈、記憶狀態與多步推理流程,不算是輕量型項目。

目前 GitHub 提供的是論文與示範資訊,code、data、checkpoint 仍標示 coming soon,所以現階段較適合當成研究方向來理解,而不是即裝即跑的工具。若要測試它的價值,較合理的方法是留意之後公開的 inference / evaluation code,並對照 MMSI-Bench 一類 multi-view 與 video spatial reasoning benchmark 的表現。
- 核心主張是用 spatio-temporal evidence accumulation 取代 isolated frame-level prediction
- 系統結構包含 VLM semantic planner、hierarchy of spatial tools、Scene Memory、Agent Memory
- 論文指在 zero-shot 設定下可提升 Gemini-3-Pro,SFT 後的 S-Agent-8B 亦能接近高階 closed-source models
- 適合研究 spatial intelligence、multi-view reasoning、video understanding 的團隊留意
相關模型方面,文中明確提到 Gemini-3-Pro、Qwen-VL-8B,以及蒸餾後的 S-Agent-8B。若你關心 Computer-use agents、CUAs 以外,AI 如何真正理解連續 3D 世界,這個項目比一般圖片問答更有研究價值。