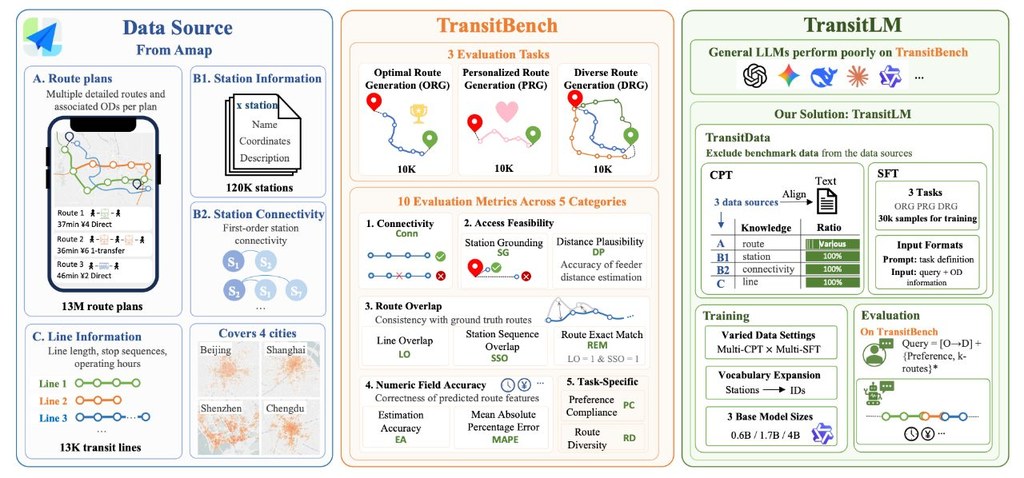
OpenClaw 等個人助理代理的興起凸顯了大型語言模型在支援使用者日常生活和工作方面日益增長的潛力。這些環境中的一個核心挑戰是主動協助,因為使用者通常從未明確說明的請求開始,而未說明重要的需求、限製或偏好。
Pi-Bench 不是一般聊天問答,而是評測檢查個人助手型代理在長流程工作中,能否及早察覺用戶未講出口的需要。這類情境很常見,因為不少人一開始只會講大方向,細節、限制同偏好往往在後續對話才慢慢浮現。
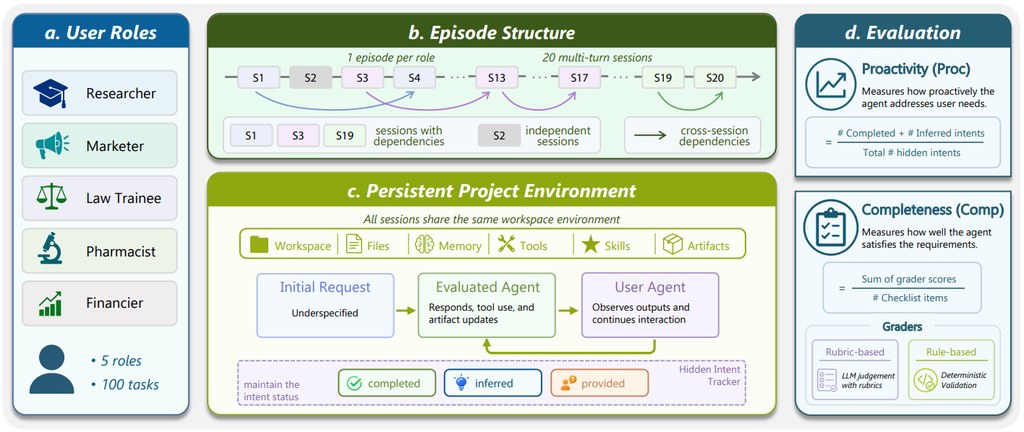
這個項目收錄了 100 個多輪任務,涵蓋 researcher、marketer、pharmacist、law trainee、financier 五類角色,並且把任務放進可持續保存的工作空間,模擬跨時段處理事情的情況。相比只測短回合回答的基準,它更接近「一路做、一路補需求」的助手工作模式。
Pi-Bench 的特別之處,在於它同時看兩件事:助手夠不夠主動,以及最後交付是否完整。前者會看系統能否提早推斷隱藏意圖,或主動追問關鍵資訊;後者則檢查輸出是否符合清單要求。README 提到評分包含隱藏意圖判斷與 checklist 驗證,而且審核分歧低於 4%,顯示評估設計有一定穩定性。
對研究代理系統、評估 LLM 助手,或者想比較 OpenClaw、Nanobot、Claude Code 一類模型/系統表現的人,這個項目幾有參考價值。使用時重點不是「跑出高分」本身,而是觀察模型在哪些回合漏問、忘記前文,或者只懂被動完成指令。
- 針對長流程、多輪互動,不只測單次回答
- 納入隱藏需求、跨任務依賴與跨 session 延續性
- 以主動性與完整度兩條線一齊評估
- 包含 5 種角色、100 個任務,場景較立體
- 適合比較個人助手型代理,而非純文字問答模型
整體來說,Pi-Bench 最有價值的地方,是把「助手是否主動幫到手」拆成可觀察、可比較的評測問題。它未必直接提升模型能力,但很適合作為檢查工具,幫團隊看清楚一個助手究竟只是跟指令做事,還是真正懂得提前補位。