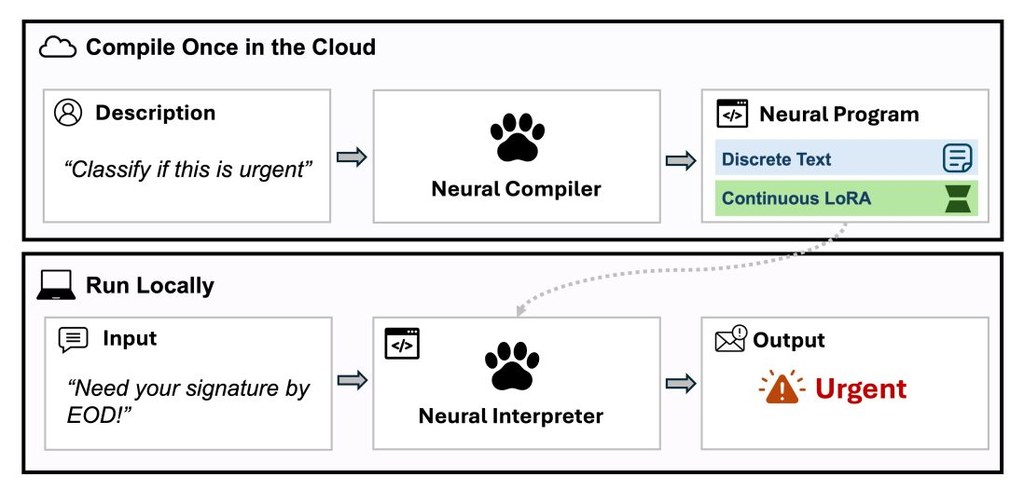
TAP(Task-Agnostic-Pretrain) 是一個 Vision-Language-Action(VLA)模型訓練框架,屬於研究原型兼訓練方法。它要處理的核心問題,是 VLA 長期依賴大量 expert demonstrations,導致機械操作能力難以用較低成本擴展。
現有做法多數直接把「how to move」與「what to do」一齊學,通常需要 observation、instruction、action 這類完整示範資料;作者認為這種固定範式混淆了 physical competence 與 semantic alignment 兩個目標,結果是語言標註被過度用喺本來可以自我監督學習的動作能力上。Task-Agnostic Pretraining(TAP)因此改成兩階段:先用無標註互動資料透過 self-supervised Inverse Dynamics 學 transferable motor priors,再用少量 expert demonstrations 做 task-specific alignment。
這種取向同標準 behavior cloning、以大量網路或專家軌跡堆出來的 VLA 路線唔同。TAP 的取捨很明確:它未必追求一次過把語義和動作全學齊,而是先把可遷移的「點樣郁」拆出來,換來更低標註成本,同時提高對背景、視角變化的穩定度;代價是整個方法仍然要靠第二階段示範去把語言指令對齊到具體任務。
項目已經交代了測試方式:這不是即裝即用應用程式,而是要跟住論文設定,載入 HuggingFace 提供的模型,重現兩階段訓練,再用 SIMPLER benchmark 與真實 WidowX-250s 場景驗證。數字上,TAP-20k 在 SIMPLER 的 Avg-All 為 33.32%,高過 Standard BC 的 23.15%;真實環境中只用 200 個 expert demos,面對 background texture shift 仍有 45% success,viewpoint variation 亦有 20%,而部分 baseline 會跌到 0%。
- 用 self-supervised Inverse Dynamics 先學動作先驗,減少對語言標註依賴
- 以約 30 小時 autonomous play 加少量 expert demonstrations,對比 1M+ expert trajectories 路線更慳資料
- 在 SIMPLER benchmark 勝過 Standard BC,接近或超過部分現有 VLA 模型
- 對 visual distractors、background texture shift、viewpoint variation 的抗干擾能力較強
- 相關模型包括 RT-1-X、OpenVLA、Nora、Octo,以及 README 提到的 TAP-20k
項目較適合做 Embodied AI、robot learning、VLA 訓練流程研究的團隊參考,尤其係想用學術規模算力驗證新訓練路線的人。它現階段更像一套值得跟進的方法論,而唔係面向一般用戶的完成品工具。
![iRDM post-trains four-step FLUX.2 [klein] into a one-step generator at matched quality; GenEval and PickScore climb past](https://infernews.com/blog/wp-content/uploads/2026/07/teaser.jpg)