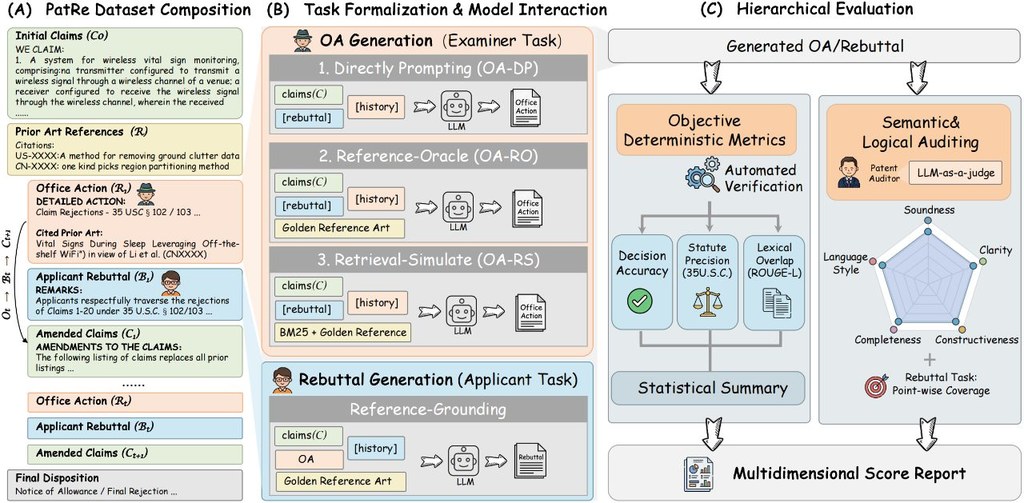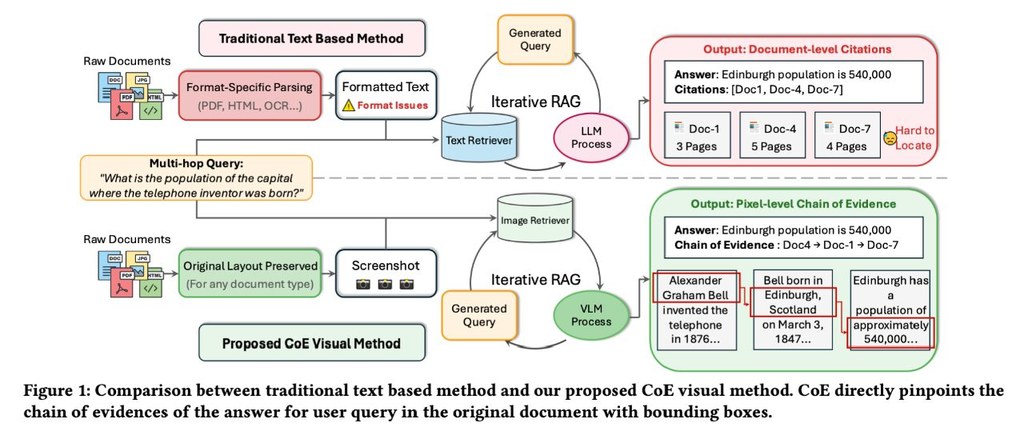
CoE 是一個面向迭代式 RAG 的視覺歸因框架,重點不是只回答問題,而是把「答案怎麼來」具體標在文件截圖上。它接受問題與前 5 筆候選文件,接著排序出證據鏈、框出支撐區域,最後產生答案,讓多跳推理不再只停留在文件層級引用。
實際使用上,這個專案比較像研究型工具鏈:可先準備 Wiki-CoE 或 SlideVQA 資料,再依兩階段流程訓練,最後用評估與視覺化模組檢查框選結果。若只想快速體驗,儲存庫也提供已訓練檢查點;需特定模型時,專案明確是以 Qwen3-VL-8B-Instruct 為核心封裝。
它最有價值的地方,在於直接對文件畫面推理,而非先把 PDF、網頁或投影片硬轉成線性文字。這種做法能保留版面、表格、資訊圖與視覺關係,對投影片、複雜網頁或含圖表文件尤其重要,也回應了傳統文字式 RAG 難以精準驗證來源的位置問題。
重點摘要:
– 支援多跳證據排序,不只找單一片段
– 以邊界框標示像素級證據區域
– 採兩階段課程式訓練,先定位再推理
– 提供 Wiki-CoE 資料集與 8B 檢查點
– 評估涵蓋答案正確率與定位、證據鏈表現
若你的需求是法務、金融、研究助理或企業知識庫這類必須追溯依據的問答系統,CoE 的方向很有參考價值。相較一般只附引用來源的 RAG,它更像把驗證流程前移;不過目前整體形態仍偏研究與實驗環境,較適合拿來做方法評估、原型驗證與高可解釋性場景測試。