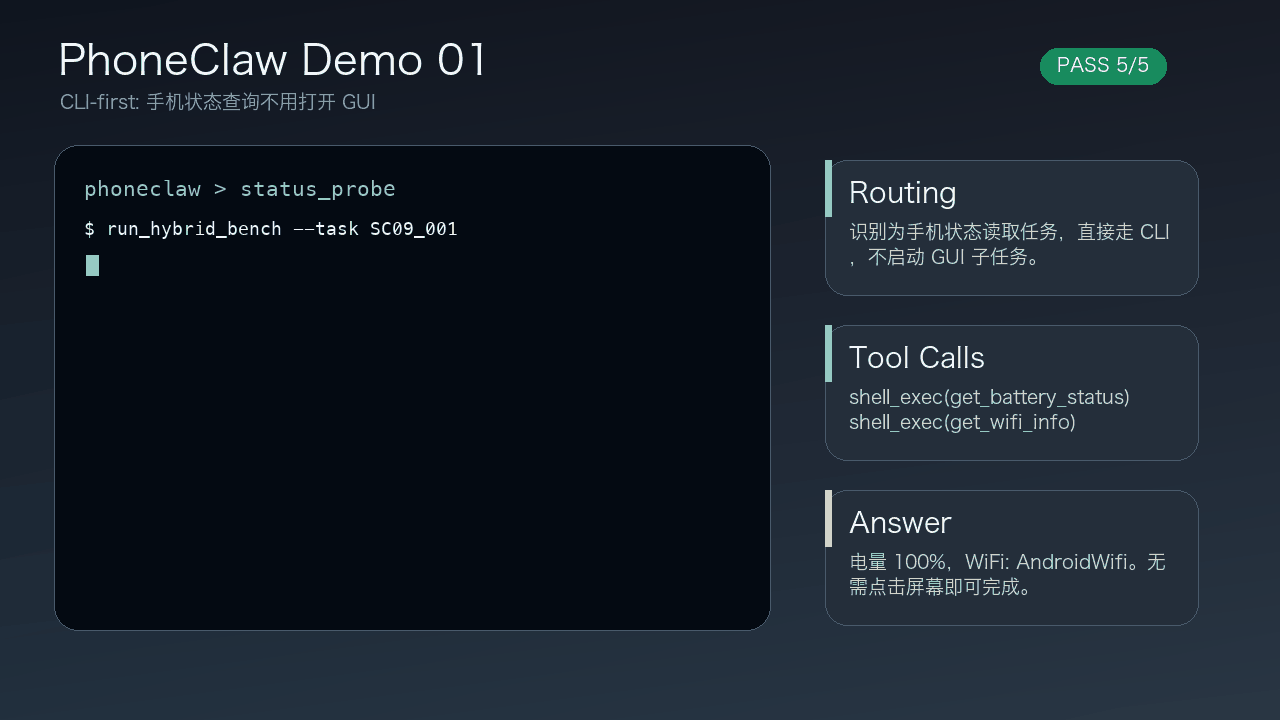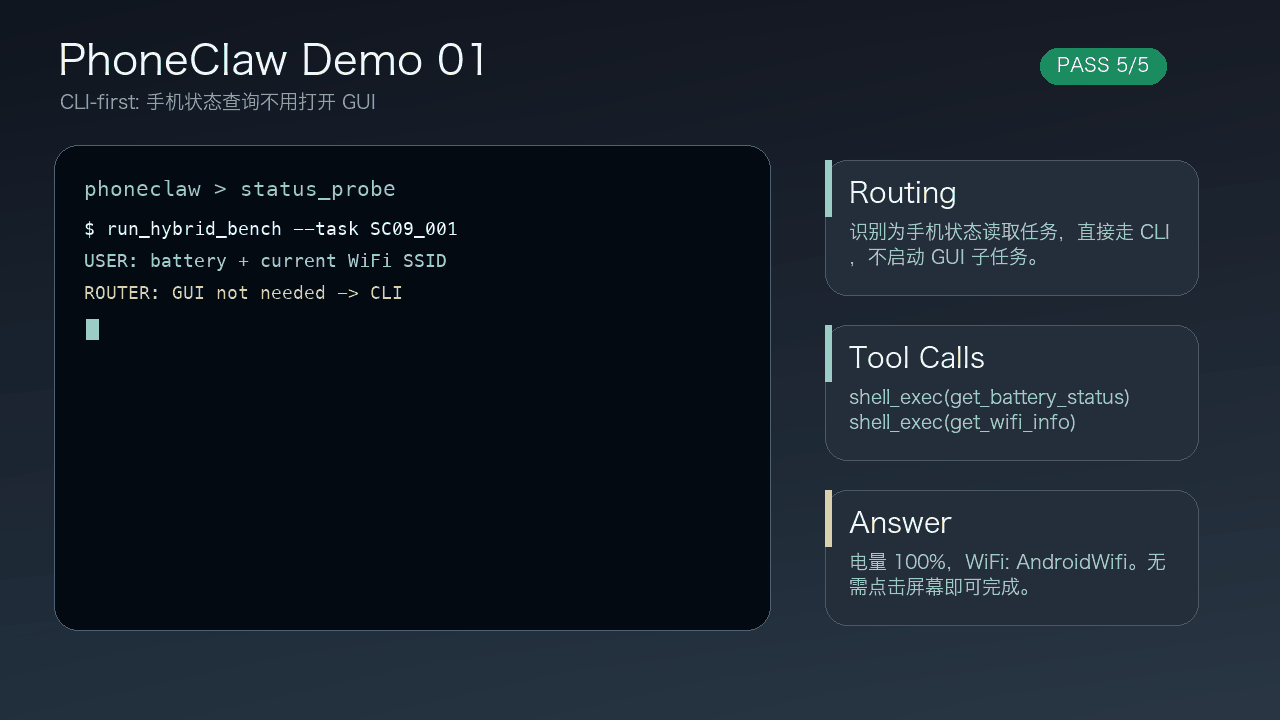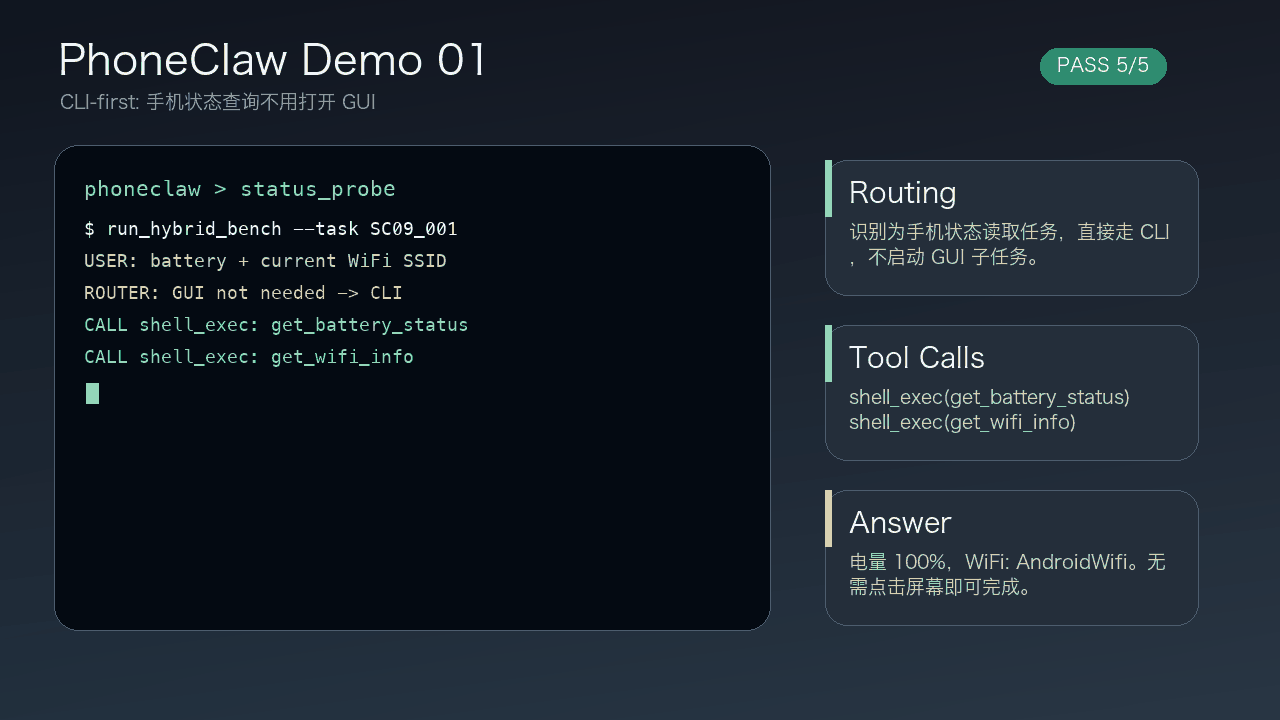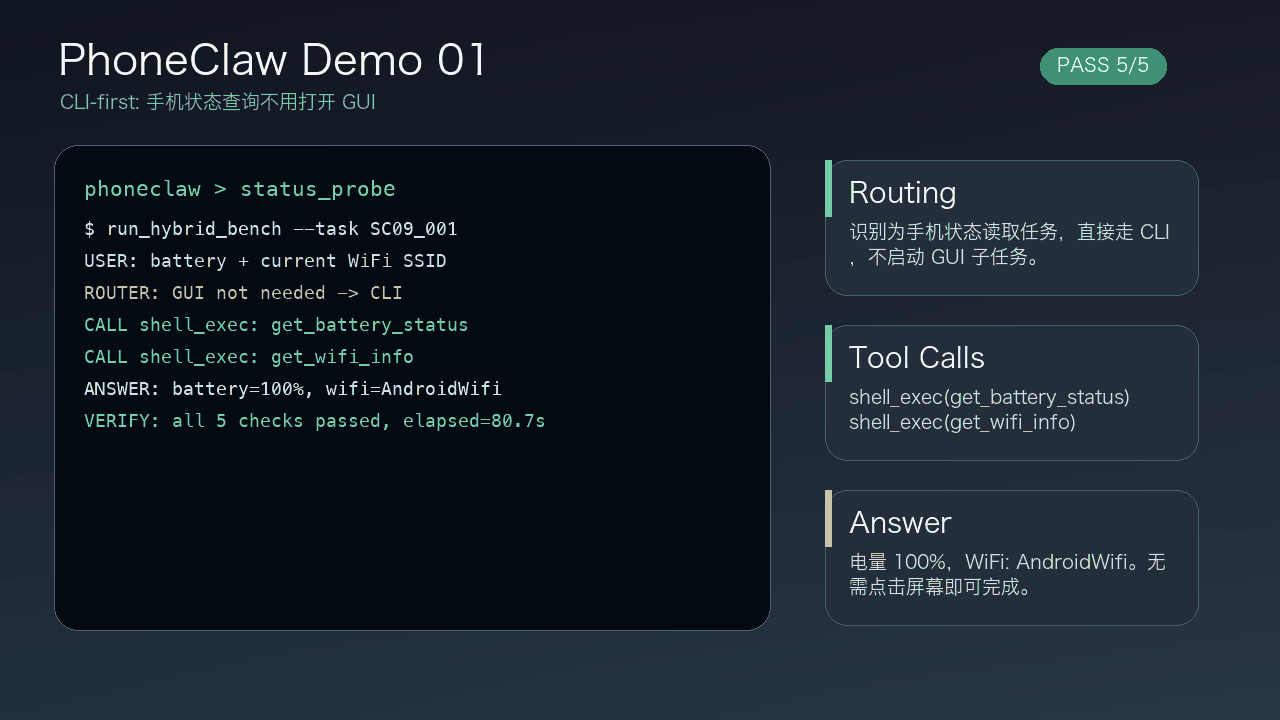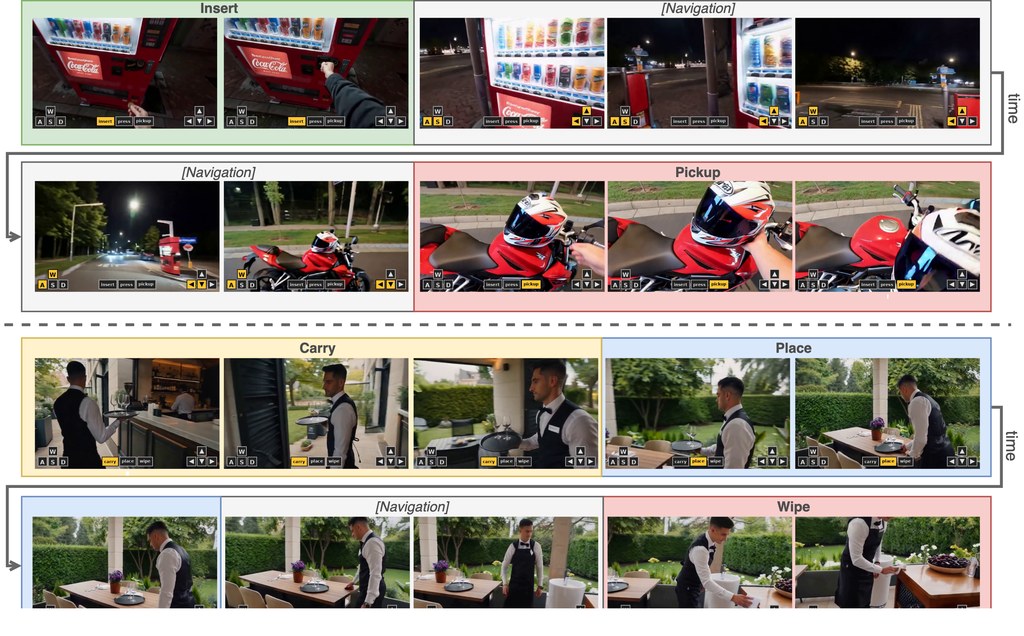
ActWorld 是一個 Interactive World Model,目標是把「可四處觀看的世界」推進到「可以即時操作的世界」。以往不少世界模型主要支援移動、轉向、環視等導航動作,對場景中的物件互動支援有限;這個項目則加入中途操作物件的能力,例如拾取、搬運、放置,令同一次 rollout 不只是在場景中行走。
這個項目想處理兩個核心問題:一是缺少高質素的人與物件互動數據,二是模型容易忘記早前發生、但會影響之後物件狀態的關鍵畫面。為此,團隊建立了 100K interaction video dataset,並以 chain-of-thought reasoning 產生 per-chunk captions;同時提出 hierarchical action-aware memory 和 persistent memory bank,讓模型按互動重要性保留歷史資訊,減少 action-forgetting。
使用時,讀者可先從項目頁面的 Paper、Code、Video 和 Comparisons 了解能力範圍。從內容描述判斷,ActWorld 適合研究 Interactive World Model、Computer-use agents(CUAs)相關模擬環境、機械人互動、或需要長時序場景生成與控制的團隊參考。
- 在單一模型內同時處理 long-horizon navigation 與 object interaction
- 透過 100K interaction video dataset 補足互動數據不足
- 用 hierarchical action-aware memory 保留較重要的互動歷史
- 以 persistent memory bank 追蹤事件更新與物件身份
按頁面說明,實驗結果顯示它在不犧牲 viewpoint control 的情況下,interaction fidelity 明顯優於只做導航的 baseline。現階段公開資訊以研究展示為主,若想深入理解效果,最應留意 Comparisons 及論文中的評測設定與限制。