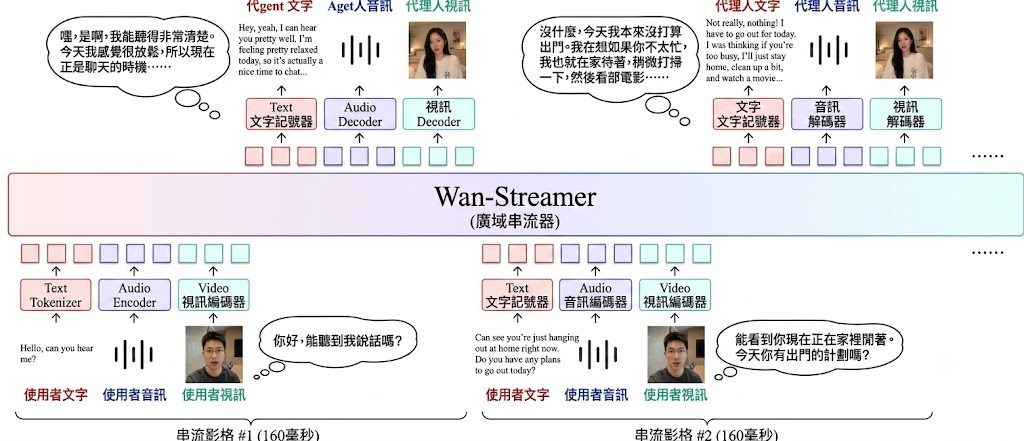
Semantic Browsing 是一篇發表於 ECCV 2026 的學術項目,由 Tel Aviv University 的 Sara Dorfman、Maya Vishnevsky、Omer Dahary、Or Patashnik 與 Daniel Cohen-Or 共同開發。它針對文字生成圖像模型在重複取樣時容易「語意塌縮」、產出過於雷同的問題,提出一套可控多樣性的工作流程。
Gemini Interactions API 是實驗性 API,可讓開發人員使用 Gemini 模型建構生成式 AI 應用程式。Gemini 是 Google 最強大的模型,打從設計之初就具有多模態的特質。可歸納內容,完美解讀、操作及結合語言、圖片、音訊、影片和程式碼等不同類型的資訊。您可以使用 Gemini API 處理各種用途,例如:跨文字和圖片進行推論、生成內容、對話式代理程式、摘要和分類系統等。
這是一個供開發者使用的 API,屬於 Google AI Studio 的 Interactions API。它的主要用途,是用一個統一介面去操作 Gemini models 與 agents,方便把模型回應、工具呼叫和代理人流程放在同一套工作流內處理。
和一般逐步拼接多個端點的做法相比,較值得留意的是它主打「統一」:同時面向模型和 agents,減少來回切換不同介面的負擔。這對要做多步驟互動、工具協調、或需要把 AI 行為包成穩定流程的團隊會更實用。
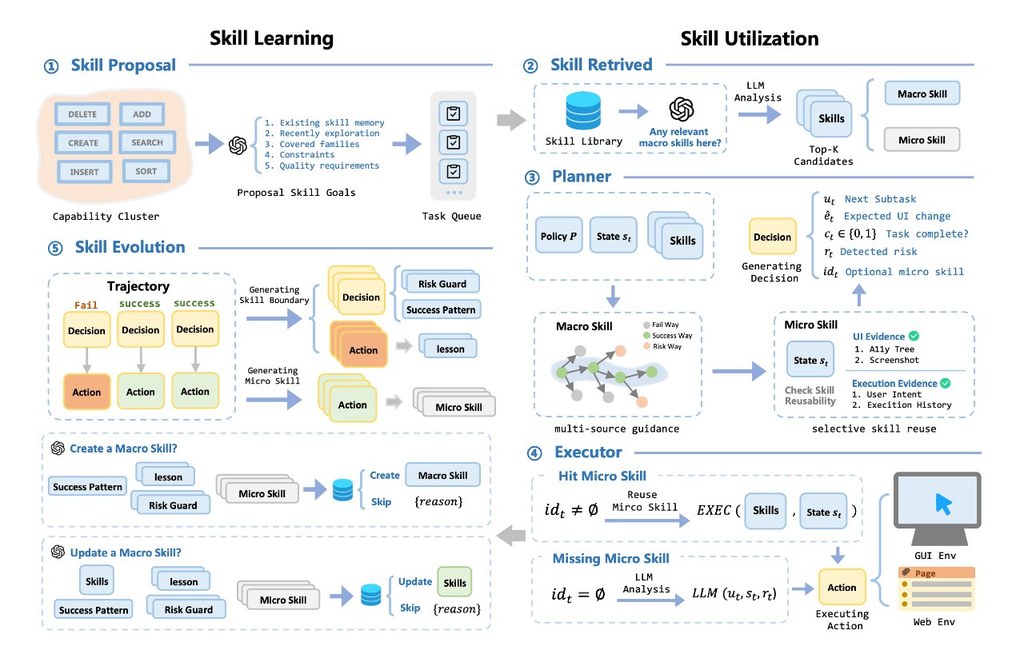
現有做法多數沿用「從成功軌跡抽取可重用技能」這個範式,常見表達形式包括函式或 API,但作者認為這類方法預設環境是 static and safe。SkillHarness 改用 safety-constrained interaction process 去看待技能的學習與使用,核心不是多學幾個技能,而是先判斷哪些技能在當下情境仍然安全。