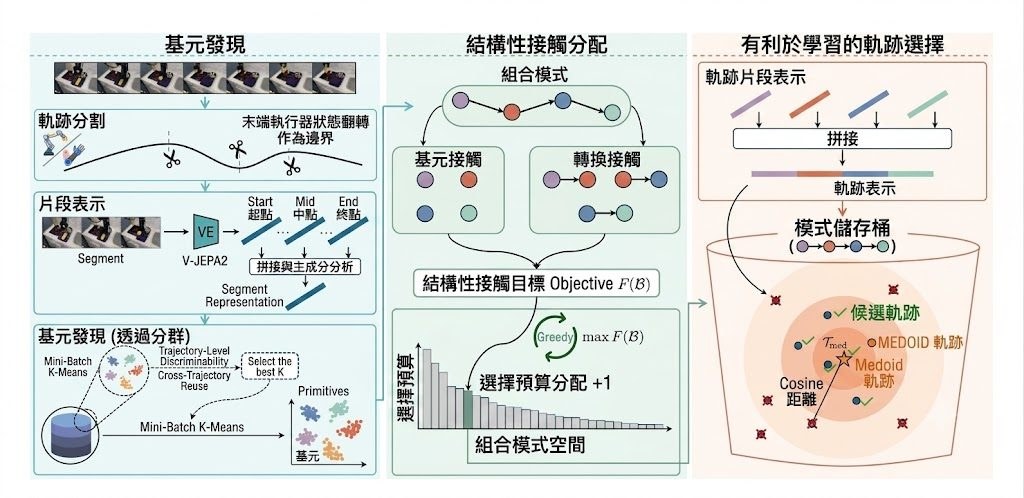
機械人示範資料最常見的問題,不是數量不夠,而是重複、嘈雜,甚至長段任務其實只是不斷重演相似動作。SIEVE 屬於一個面向 imitation learning 的資料篩選工具,同時帶有研究方法性質,重點不是逐條 trajectory 粗略評分,也不是只看 state-action,而是把長任務拆成可重用的 visuo-motor primitives 與 transition interfaces,再決定哪些 episode 更值得留下來訓練 VLA 模型。
它批評的舊範式相當明確:現有 data selection 方法多數只在 trajectory level 或 state-action level 做判斷,因而忽略長時序行為內部可重用的結構。SIEVE 的做法是先用 end-effector pose 與控制訊號做 segmentation,再抽取 V-JEPA 特徵、用 PCA 壓到預設 256 維、以 MiniBatchKMeans 找出 primitive pattern,之後按 cluster-sequence pattern 做兩階段 episode selection,最後可以匯出回 LeRobot 格式,方便直接接回原本訓練流程。
這種取向的好處,在於它不是單純挑「最好」或「最乾淨」的示範,而是優先保留結構覆蓋度與可重用性。論文提供的訊息亦相當直接:SIEVE 在多個 datasets、benchmarks 與 VLA models 上,都比競爭性的 baseline 更穩定,甚至在只用 50% demonstrations 和 50% training steps 的情況下,表現可以超過 full-data training。當然,這也代表它較適合已有一定規模示範資料、並且願意先跑一輪離線整理流程的團隊,而不是追求即插即用的小型腳本。
- 以 LeRobot v2 資料根目錄作輸入,支援單一或多個 dataset
- 流程由 segmentation、feature extraction、dimensionality reduction、clustering、selection 組成
- 特徵抽取依賴 V-JEPA,輸出中間結果到 Zarr,再匯出選中的 LeRobot episodes
- 核心差異是按 reusable structure 揀數據,不是只按整條 trajectory 或逐步 state-action 打分
部署理解上,這個項目更像一條可重複執行的離線資料處理 pipeline,而不是一個直接提供推理服務的套件。適合用來整理大型 robot demonstration corpus、為 VLA imitation learning 減少冗餘訓練樣本;相關模型與技術脈絡包括 Vision-Language-Action (VLA) models、V-JEPA,以及輸出端相容的 LeRobot。