這是一個面向機械人操作的 Vision-Language-Action(VLA)foundation model,名為 ABot-M0。它主要用來讓機械人根據視覺與指令完成操作任務,並處理資料分散、動作表示不一致,以及控制模型訓練效率偏低的問題。
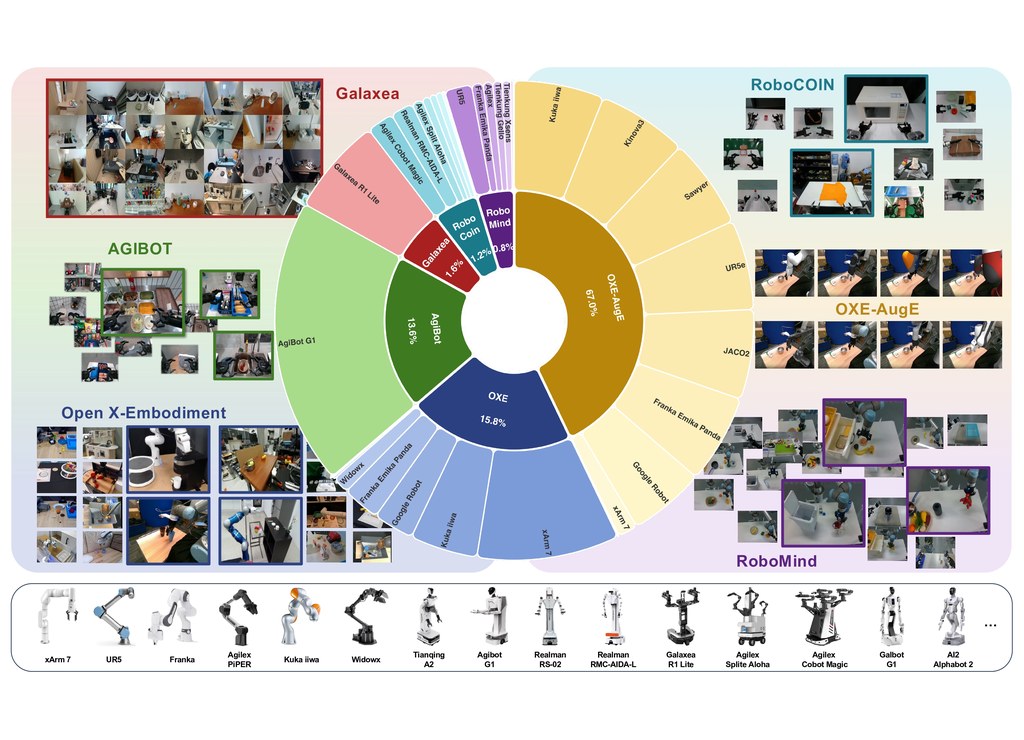
ABot-M0 的基礎來自 UniACT-dataset。這個資料集整合 6 個公開資料來源,包含 OXE、OXE-AugE 與 AgiBot-Beta,合共超過 600 萬條 trajectories、9,500 小時以上互動資料,並覆蓋 20 多種機械人形態;資料亦經過清理、標準化與統一,將動作轉成 end-effector 座標系中的 delta actions,旋轉則採用較穩定的 rotation vector 表示。
它和常見 diffusion 式控制方法的主要差異,在於採用 Action Manifold Learning(AML)。一般 diffusion model 多數學習預測 noise,ABot-M0 則直接做 Direct Action Prediction(a-prediction),輸出乾淨的動作序列;這種做法把學習重點由「擬合噪聲」轉成「投影到可行動作流形」,理論上更有效率,也更有助提升解碼速度與 policy stability。
另一個實用方向是模組化 3D perception。ABot-M0 支援 plug-and-play 模組去加強 3D 空間理解,對涉及精準位置、姿態與複雜操作步驟的任務會更有幫助;同時,它亦用「pad-to-dual」策略統一 single-arm 與 dual-arm 任務,令同一模型可覆蓋更廣的操作場景。
- 整合超過 600 萬條 trajectories,資料規模相當大
- 以 UniACT-dataset 統一不同來源與不同機械人表示方式
- 採用 Action Manifold Learning(AML),直接預測動作而非噪聲
- 支援 plug-and-play 3D perception 模組,提升複雜任務精度
- 適合關注 robotic manipulation、VLA 與通用機械人控制的讀者
現有資料重點放在方法設計與資料規模,具體基準分數與完整比較結果在這份內容中未完全展開。即使如此,ABot-M0 已清楚展示一條很具代表性的路線:先用大規模統一資料打底,再用更貼近可行動作結構的學習方式,提升機械人操作模型的泛化與穩定性。