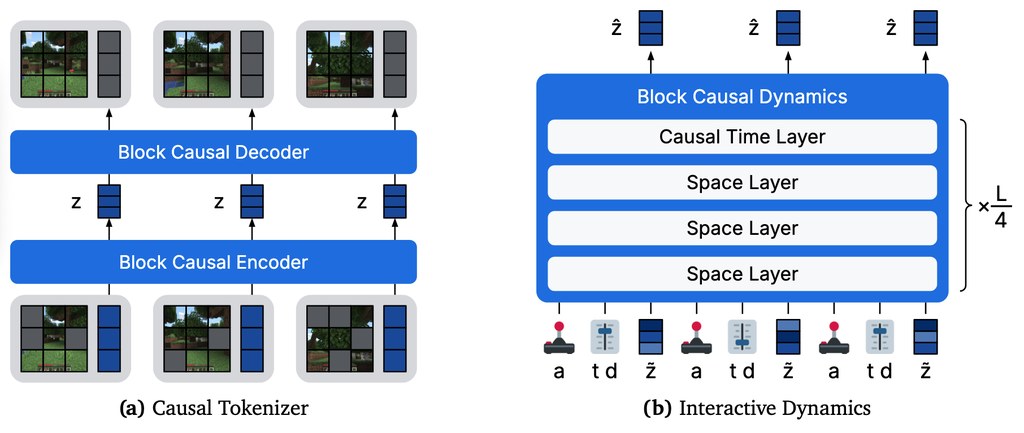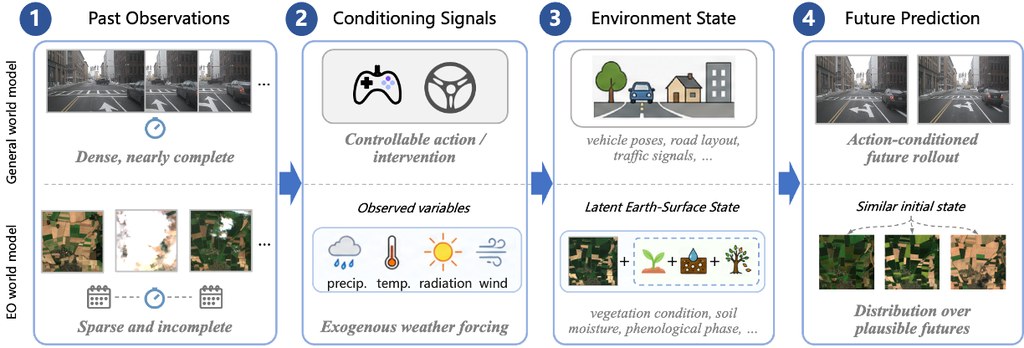
這是一個結合物理知識的影片擴散世界模型(EO-WM),專門用於多光譜衛星影像的概率預測。整體目標是把地球觀測(Earth Observation, EO)預報重新定位為「部分可觀察、天氣驅動的世界建模」任務,在稀疏衛星上下文與未來氣象條件下預測地表動態,並支援災害監測、作物產量預估及植被變化追蹤等下游應用。
過去的 EO 預測方法分為兩類:決定式模型把不確定性壓縮成單一未來影像,擴散式方法則往往把天氣變量當成籠統的條件輸入。這兩種做法都難以正確反映「氣象條件如何改變地表狀態」這個核心問題,而且現有 benchmark 多聚焦於像素重建準確度,未能衡量模型在改變天氣條件時是否會產生方向正確的響應。EO-WM 為了解決這個落差,引入一個 EO 專屬 VAE 把稀疏衛星觀測編碼為潛在影片 token,再用擴散 Transformer(diffusion transformer)經由獨立條件路徑同時處理三種信號:氣候基線(climatological baseline)、天氣異常(weather anomaly)與累積物理壓力(cumulative stress),並持續將空間上下文重新注入影片 token 流。
在評測方面,作者提出兩個以 EarthNet2021 為基礎的診斷式 benchmark:Extreme Summer Benchmark 衡量極端熱浪與乾旱下植被退化的嚴重程度感知能力,引入 TN-MAE 與 Drop Amplitude Error;Seasonal Matched-Pair Benchmark 則衡量當天氣條件改變時預測方向與幅度是否正確,以 Divergence Reproduction Ratio、Directional Hit Rate 與 Paired Divergence Correlation 為指標。報告結果顯示 NDVI 下降幅度的預測誤差相對減少 5.63%,方向命中率相對提升 7.80%,同時在像素級 ENS、P-MAE、N-MAE 等指標上仍具競爭力。
這個項目對遙感研究者、農業監測團隊及氣候風險分析團隊特別有價值,因為它同時提供模型與基準資料,讓外界可在統一的評測框架下比較不同方法的天氣響應能力。從工程角度來看,架構設計強調物理分離條件與空間重注入,而非單純堆疊參數,這種取捨有助於提高極端情境下的可解釋性。需留意的是,目前 GitHub 倉庫主要釋出 benchmark CSV 與 Earthformer 參考評測腳本,模型權重與完整訓練流程屬於配套資源,重現完整結果仍需自行準備 EarthNet2021 的 extreme 與 seasonal 切分資料。
重點摘要:
- 重新定義 EO 預報範式:把衛星影像預測視為天氣驅動的世界建模,而非純粹的影像重建。
- 物理分離條件:天氣信號被拆分為基線、異常與累積壓力三條獨立條件路徑。
- 診斷式 benchmark:Extreme Summer 與 Seasonal Matched-Pair 兩個基準專門檢驗模型在天氣改變下的響應正確性。
- 可量化的天氣敏感度:NDVI 下降誤差降低 5.63%,方向命中率提升 7.80%,標準指標仍具競爭力。
- 目前釋出內容:以 benchmark CSV 與評測腳本為主,完整訓練流程需搭配 EarthNet2021 資料集。