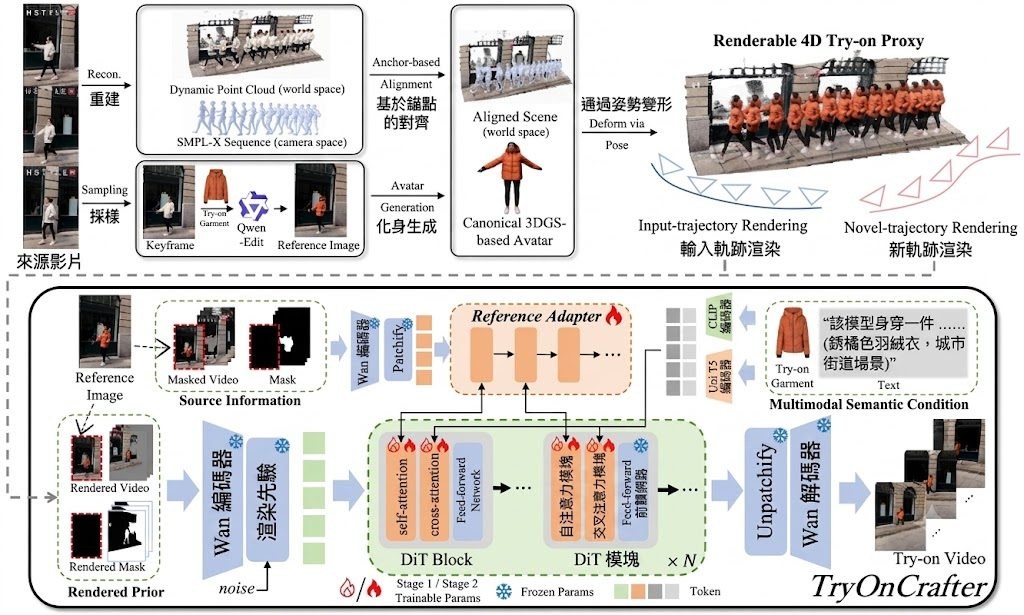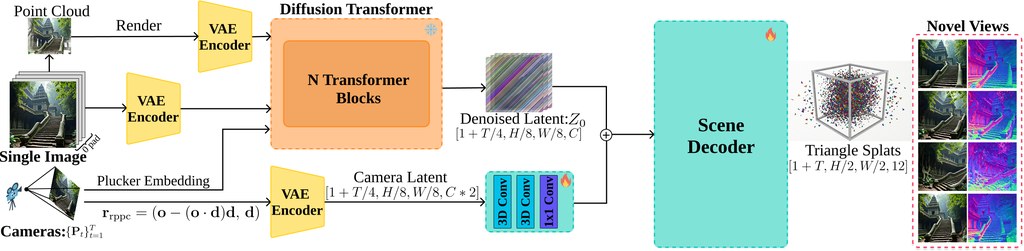
UnityShots 是一個研究性質的多鏡頭影音生成框架,核心任務是解決現有方法在長序列多鏡頭影片中難以維持人物、場景與聲音一致性的問題。它基於已有的單鏡頭影音擴散模型 LTX-2.3(22B 參數)建構,從一段結構化提示詞直接生成 3 至 9 個鏡頭的連續 .mp4 影片,確保角色容貌、場景光影與配音語音在各鏡頭間保持連貫。
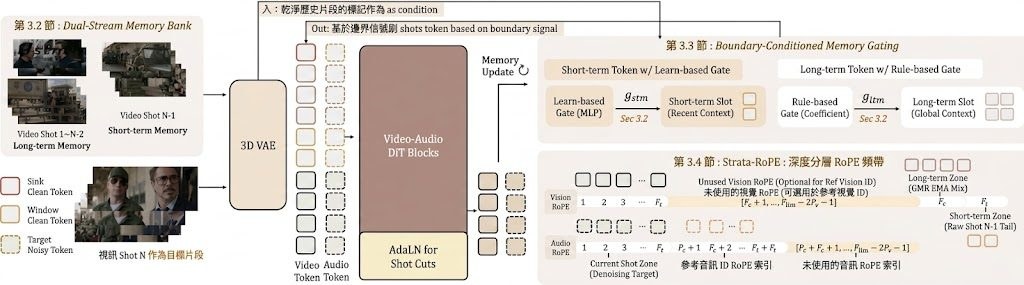
現有做法通常依賴三種路線:端到端訓練固定長度序列但難以擴展、以記憶庫逐鏡頭生成但容量隨鏡頭數線性膨脹,或用大型語言模型規劃器調度預訓練生成器而缺乏多鏡頭感知骨幹。UnityShots 的切入點是引入邊界感知門控(Boundary-Aware Gating)與雙槽記憶機制:影片流維持兩個固定大小記憶槽,長期記憶(LTM)錨定開場鏡頭,短期記憶(STM)保留前一鏡頭尾部,兩者在每次剪接時由門控網路更新;音訊流則在每個鏡頭注入參考說話者 token,避免滑動音訊庫的負擔。另一個辨識度高的設計是透過 AdaLN 學習離散剪接類型先驗(cut-type prior),讓使用者可在推論階段調整轉場強度。
以下為重點摘要:
- 類型:多鏡頭影音生成研究框架,附帶資料集與基準測試。
- 核心差異:用固定大小雙記憶槽取代線性增長的記憶庫,並加入參考語者 token 維持聲音一致性。
- 控制能力:剪接類型先驗成為推論時可調旋鈕,使用者可指定轉場強弱。
- 相關模型:以 LTX-2.3 22B 為基座,整合 AdaLN 門控機制。
- 資料集:釋出 UnityShotsBench,涵蓋六大文化區域、13 種語言的 200 段多鏡頭序列。
現有評估涵蓋 I2V、T2V、R2V 三種條件模式,UnityShots 在跨鏡頭一致性與音畫品質上與開源及閉源基準相當。對從事多鏡頭敘事、短影音自動化或數位人內容生成的團隊而言,這套框架提供了較完整的記憶與控制設計思路。原始資料庫明確指出,檢查點、訓練程式碼與代理系統尚未釋出,因此目前無法從儲存庫直接取得安裝指令或模型權重;讀者若有興趣部署,需等待官方後續發布。資料集本身可從 Hugging Face 的 KlingTeam/UnityShotsBench 下載,供研究者評測自家模型。授權為 CC BY-NC 4.0,僅限非商業學術用途。
GitHub: https://github.com/JIA-Lab-research/UnityShots