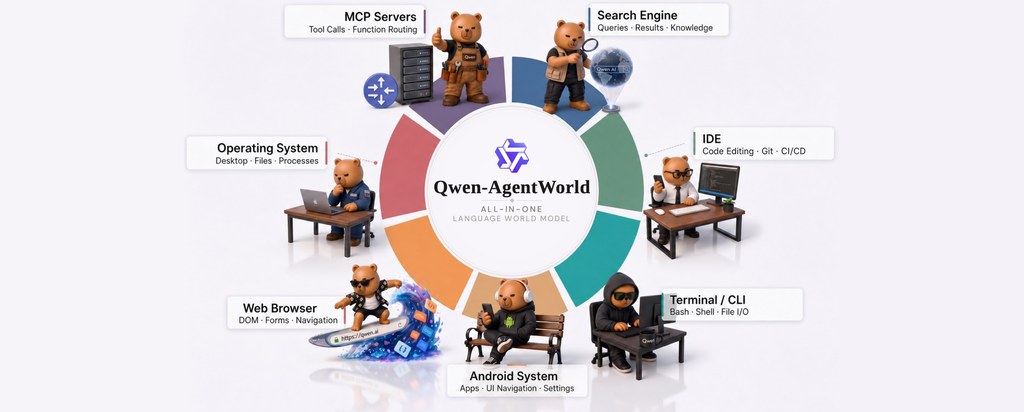
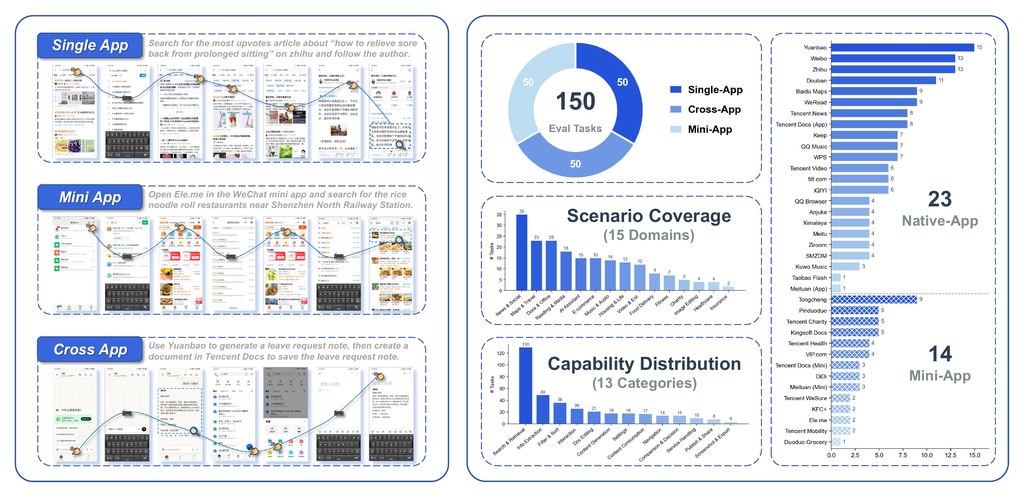
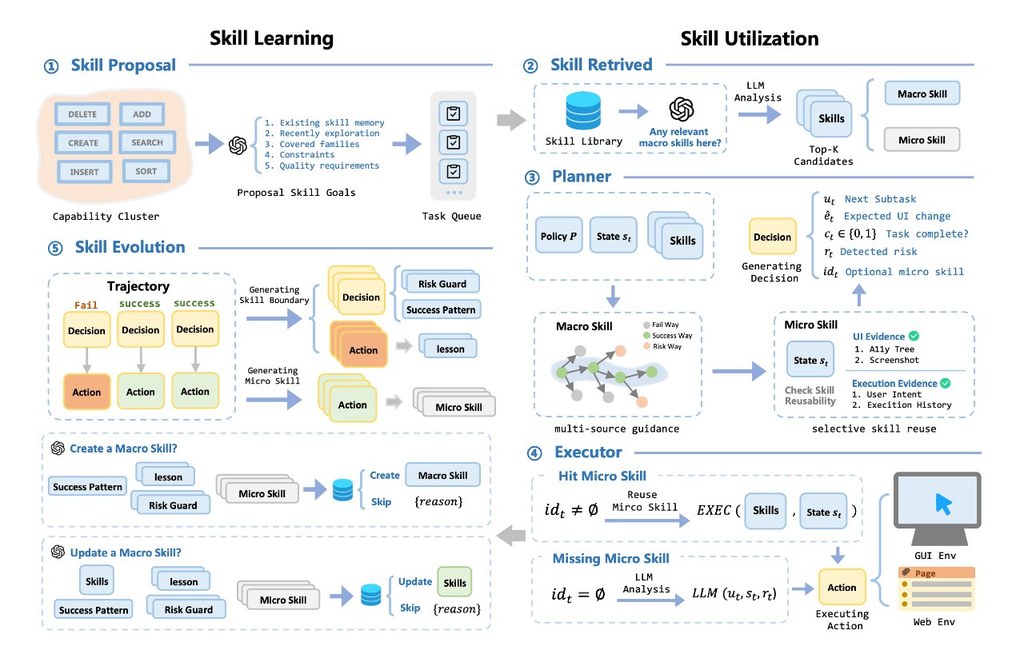
MobileForge 是一個用來調整 mobile GUI agents 的研究型訓練框架。它主要解決手機操作代理往往要靠人工寫任務、示範或獎勵標籤,成本高又難快速轉去新 App 的問題。
常用做法 human-written tasks、demonstrations 或 reward labels 去訓練,作者認為這種固定範式有兩個限制:生成的任務未必貼近目標 App,rollout 只得到稀疏成敗訊號,也很難轉成可重用的步驟級學習訊號。MobileForge 的處理方式是把目標 App 的真實互動交給 MobileGym,先做探索、抽取 executable curricula,再用 HiFPO 把 hints、hierarchical trajectory feedback 和 step-level GRPO training 串成一個不用任務標註的調整流程。
這個取向不是單靠更大模型硬推成績,而是重新整理資料來源與訓練單位:任務來自 target-app interaction,回饋不只看最後成功與否,還會拆成 outcome labels、process feedback 和 corrective hints。代價也很明顯,整個流程依賴真實 Android app 互動環境,部署與測試較像研究實驗管線,而不是裝好即用的消費級工具。
根據項目較合理的理解方式是:先取用作者釋出的 codebase、HuggingFace models、datasets 與 benchmark results,再在 Android 任務環境重跑 exploration、rollout、training、evaluation 幾個部分。它較適合做 mobile agent 研究、行動自動化、GUI policy optimization 的團隊,也適合想比較 annotation-free adaptation 與傳統人工標註流程差異的人。
- 類型定位:研究型框架,核心是 annotation-free adaptation
- 方法骨幹:MobileGym 負責探索與任務生成,HiFPO 負責回饋轉訓練訊號
- 已公開模型:GUI-Owl-1.5-8B、Qwen3-VL-8B 的 MobileForge 版本
- 結果重點:GUI-Owl-1.5-8B 在 AndroidWorld 達到 67.24% Pass@1、77.59% Pass@3;MobileWorld 為 41.03% SR
- 取捨:減少人工標註依賴,但需要較完整的互動環境與實驗流程支持
MobileForge 同時展示 in-domain AndroidWorld adaptation 與 out-of-domain MobileWorld GUI-only generalization,表示它不只是在單一資料分佈內調參。對想建立可遷移手機代理能力的團隊來說,這個項目提供的價值不只是模型 checkpoint,還包括一套如何把真實 App 操作痕跡轉成訓練循環的具體方法。
GitHub: https://github.com/kwai/MobileForge
項目主頁: https://mobile-forge.github.io/
Model: https://huggingface.co/collections/lgy0404/mobileforge-models