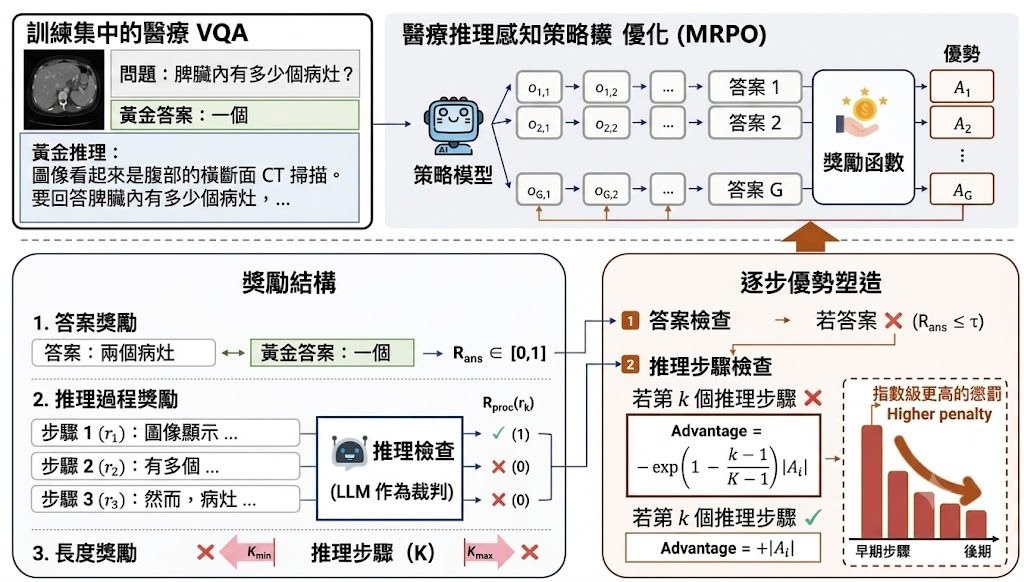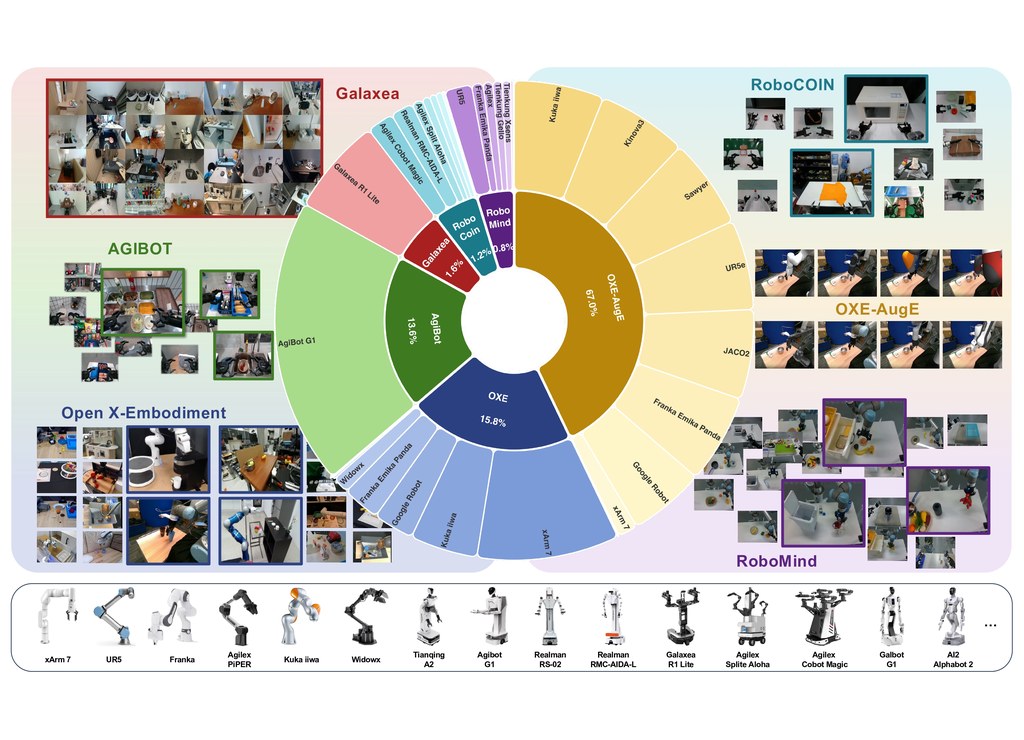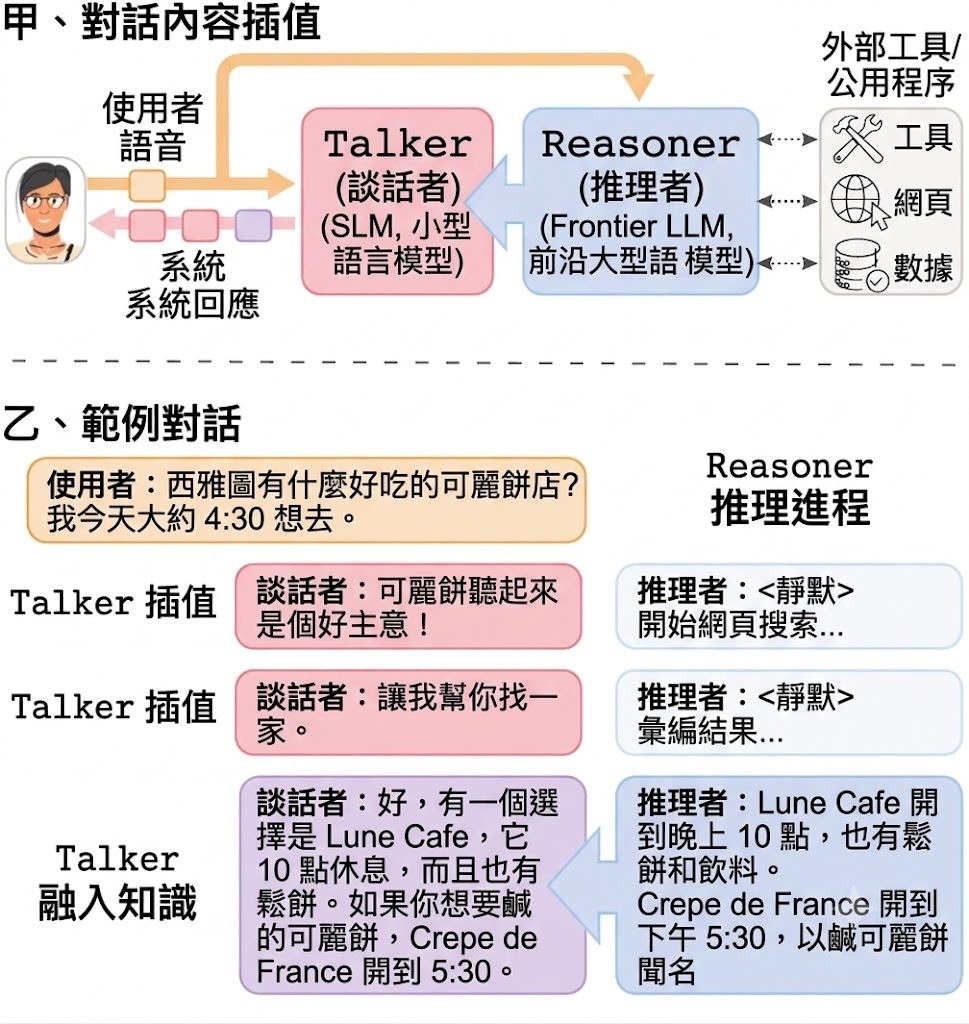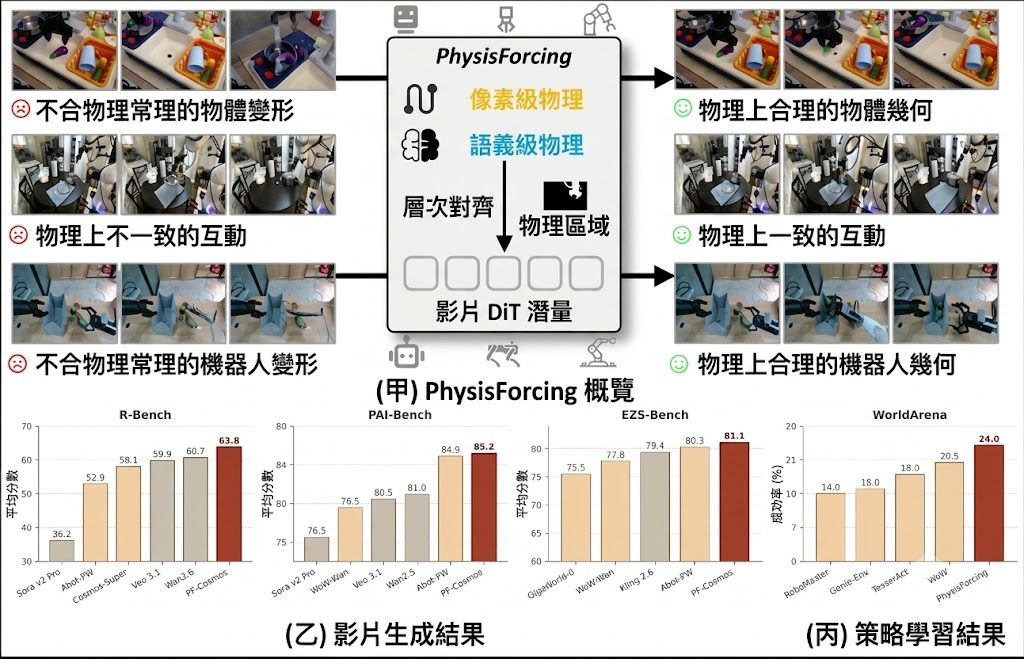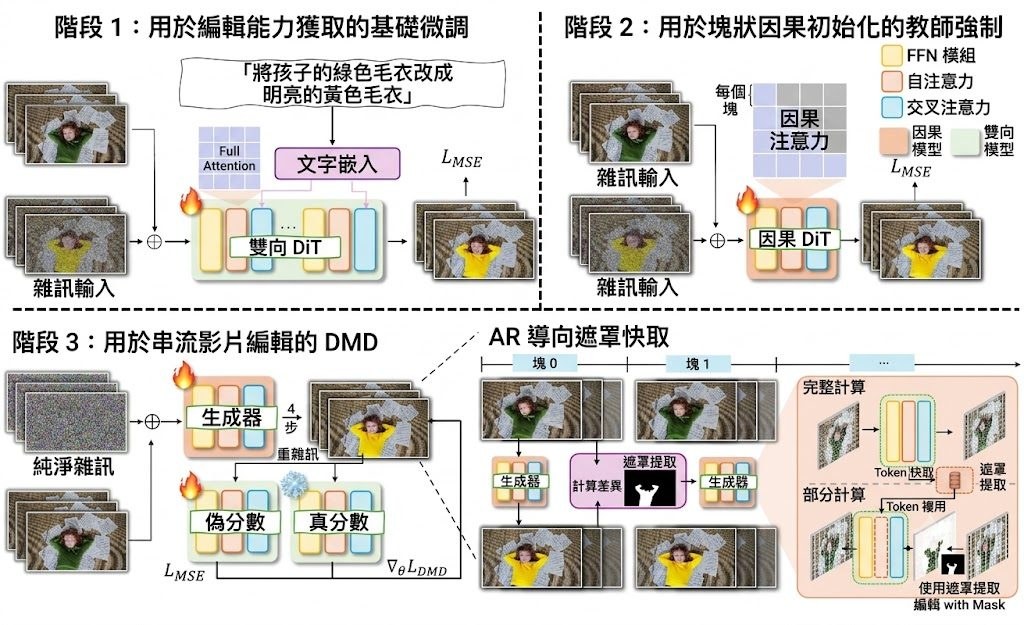
LiveEdit 是一個 diffusion-based streaming video editing 系統,屬於影片編輯模型與方法項目。它的核心任務是根據來源影片加上文字指令,逐段完成 causal chunk-by-chunk editing,並盡量保留背景與沒有修改的區域。
這個項目不是追求離線影片慢慢算到最靚,而是針對接近即時的串流編輯。它建基於 Wan2.1 和 Self-Forcing codebase,並用 three-stage distillation,把雙向編輯 teacher 的能力轉移到串流 student,再配合 AR-oriented Mask Cache 減少重複運算,換來較低延遲。
部署與測試資訊算是完整,提供 inference scripts、training code、checkpoint instructions,也講明建議在 Linux 配合 NVIDIA GPUs 執行;單 GPU 可做 inference,多 GPU torchrun 主要用於訓練。輸入方式是準備一個 JSON,填入 source video 路徑和 instruction,然後配合已釋出的權重與 Wan2.1 base model 進行推理。
有一個相當關鍵的參考值:項目頁列出 12.66 FPS,並表示透過 4-step distilled diffusion generation 達成 real-time streaming inference。這個成績對互動式影片編輯很重要,不過公開資訊未見更完整的硬件條件、顯存需求或不同解析度下的比較,因此判斷效能時仍要保留一點。
- 重點不是一般文字生片,而是保留原片內容的串流影片編輯
- 主要技術包括 three-stage distillation、Causal DiT、AR-oriented Mask Cache
- 已公開 inference 與 training 程式碼,也提供 Hugging Face checkpoint 指引
- 已知較適合 Linux、NVIDIA GPU 環境,研究團隊或影像生成工程師較易受益
- 相關模型與基礎包括 Wan2.1-T2V-1.3B、bidirectional editing teacher、streaming student
整體來看,LiveEdit 的價值在於把 streaming video editing 做得更接近可互動系統,而不只是展示級效果。它較適合研究即時影片編輯、互動內容製作、直播視覺處理或需要低延遲生成的團隊;一般用家若想直接在圖形介面一鍵開用,現有資料未提供管理後台整合、免手動設定流程,仍然比較像面向研究與開發者的項目。