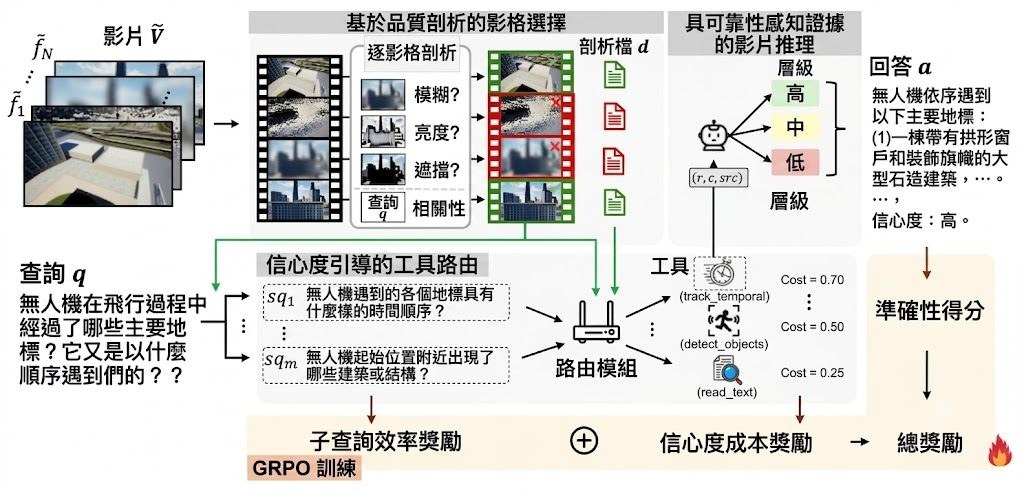
Robust-TO 是一個面向影片理解的 agentic framework 研究原型。它主要解決 Video-LLMs 在模糊、過暗、遮擋等干擾下,仍然盲目相信每一格畫面,導致答案與自信程度脫節的 Blind Trust Problem。
現有做法常把所有影格近乎同等對待,再交由單一模型或固定流程推理;作者認為這種範式忽略了畫面可靠度,所以提出 Confidence-Aware Tool Orchestration。它先用不需額外參數的 profiler 為每格評估 blur、brightness、occlusion,只保留較可靠片段,再把問題拆成子查詢,交由 track_temporal、detect_objects、read_text 等工具處理,最後用 High / Mid / Low 三層證據整合答案。
這個項目最值得留意的,不是單靠更大模型硬推結果,而是把 (result, confidence, source) 當成統一介面,連工具成本與可靠度一併納入。取捨也很明顯:流程比直接問一個 Video-LLM 更複雜,但換來對受污染影片更穩定的表現,而且官方指出在乾淨輸入上延遲開銷低於 5%。
- 平均準確率比最強開源基線高 +10.6
- clean-to-corrupted accuracy drop 最小,重點在抗干擾而非只看乾淨數據
- 使用 GRPO 訓練 policy,獎勵同時考慮正確性、證據可靠度與計算成本
- 相關組件與模型角色包括 profiler、Router,以及工具如 track_temporal、detect_objects、read_text
目前較適合把它理解為方法框架與研究結果,而不是立即可部署的成品。較受用的會是做 Video-LLMs、Computer-use agents、CUAs 式多工具協作、影片問答或魯棒性評測的研究團隊,特別是想把「模型知道自己何時不可靠」納入系統設計的人。