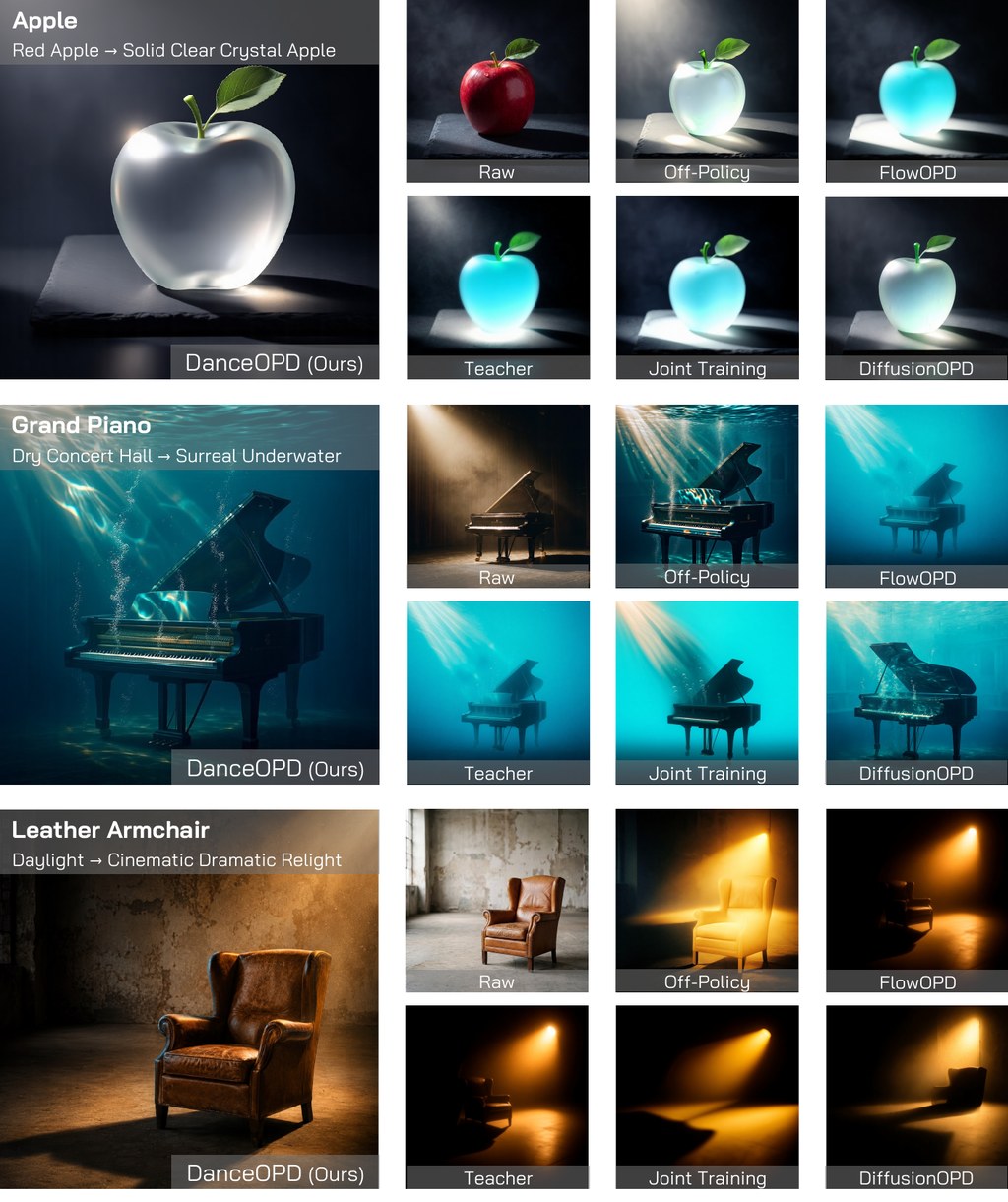
DanceOPD 是一個針對 flow-matching 模型設計的 on-policy 生成場景蒸餾框架,目標是讓單一影像生成模型同時具備文字生成影像(T2I)、局部編輯與全域編輯等多種能力。核心做法是將每個來源能力視為一個速度場(velocity field),然後在學生模型自己產生的 on-policy 狀態上查詢這個場景,再以簡單的速度 MSE 損失進行訓練。
這套方法最值得留意的差異在於 hard-routed 設計:每個樣本只被路由到一個被選中的能力場,並且只查詢一個低噪聲的語義側狀態(semantic query),避免了對多個來源場景做平均而模糊語義身份的問題。同一套框架也能吸收 operator-defined fields,例如 classifier-free guidance,讓引導機制自然融入訓練。
在評估方面,DanceOPD 報告了多項指標,包含 GEditBench-avg 在 T2I + Edit Composition 上達到 5.347、GenEval Overall 達到 0.849 同時保持 T2I 表現,以及 Local + Global Edit Composition 的 5.498、CFG 吸收診斷中 5.833 的最佳值。
這項工作適合關注多能力影像生成整合、蒸餾方法以及 flow-matching 模型研究的開發者與研究者。由於 Code 標示為「Soon」,目前尚未提供源碼或模型下載,因此暫無可對應的安裝或使用步驟可分享。
主要重點:
- 核心定位:flow-matching 模型的 on-policy 生成場景蒸餾框架
- 方法差異:hard routing 單一能力場景加單一低噪聲語義查詢,避免場景平均造成的語義模糊
- 支援能力:T2I、局部編輯、全域編輯,並能吸收 classifier-free guidance 等 operator-defined fields
- 評估數字:GenEval 0.849、GEditBench T2I+Edit 5.347、Local+Global 5.498
- 現有狀態:論文可在 arXiv 瀏覽,原始碼尚未公開