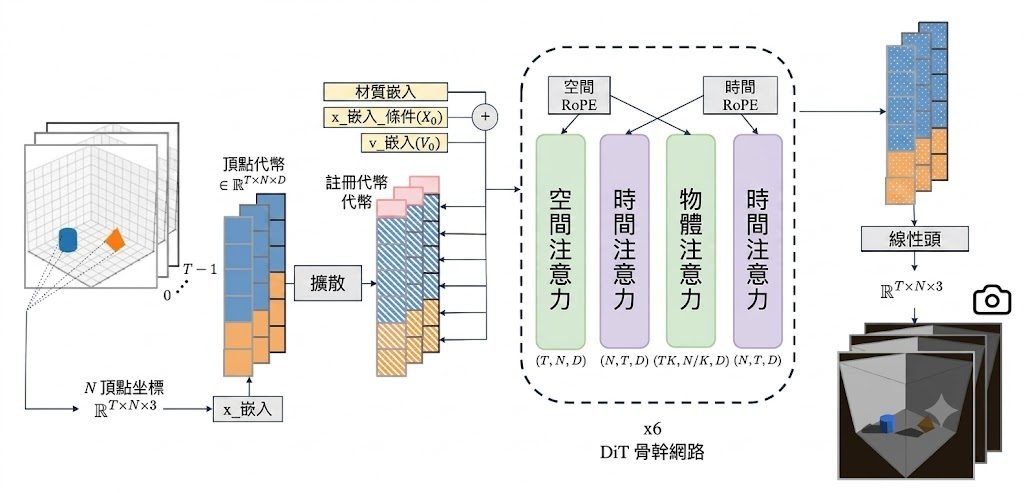
PhysiFormer 是一個 diffusion transformer 模型,用世界座標中的 3D mesh 直接模擬物體運動。它要處理的是在已知初始頂點位置、速度與材質條件下,生成之後一段時間內合理可信的 4D 動態軌跡。
它和常見 video world models 的分別,在於不是在視角相關的像素空間推測畫面變化,而是直接預測 world coordinates 裡的 vertex trajectories。論文指出,這個做法不依賴手動指定的模擬結構、shape latent,亦不需要明確加入 rigid-transform prediction 一類限制,改用單一步驟的去噪擴散過程學習完整時域軌跡。
模型同時支援 rigid 與 elastic 物件,亦能處理 mixed-material dynamics、碰撞,以及靜止與移動中的多個物件。為了提升效率,PhysiFormer 採用在時間、空間與物件三個維度分解的 attention,令多物件推理保留 permutation-invariant 特性,毋須額外手動編碼物件身份。
- 以 3D coordinate diffusion 建模,重點是視角無關而且幾何結構清晰
- 用超過 100k simulated trajectories 訓練,覆蓋多種剛體與彈性體運動
- 可生成多個合理未來,而非只輸出單一路徑,適合存在未觀察不確定性的情境
- 它在 trajectory accuracy、rigidity preservation 與 momentum-based physical consistency 上明顯優於 autoregressive baselines
這類項目較適合 robotics、graphics、physical design,以及需要幾何感知 world modelling 的工作流。現有資料顯示它對未見過的真實幾何形狀、更大的物件數量,以及混合材質場景有一定泛化能力,但內容主要來自模擬資料與論文結果,真實部署表現仍要配合具體場景再驗證。