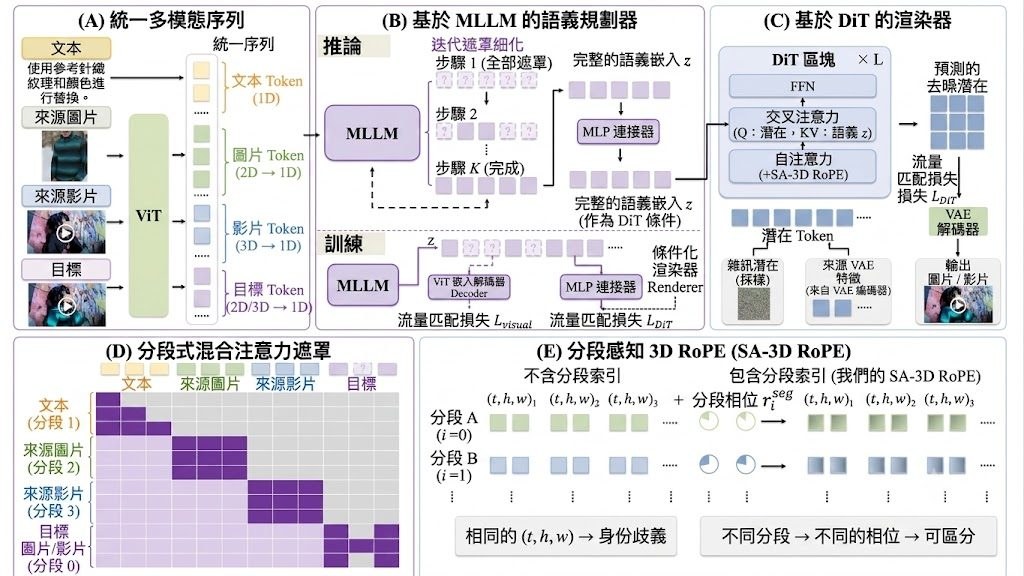
現有的城市場景逆向渲染方法長期面臨兩難:基於物理的渲染(physically-based rendering)雖然能嚴格遵守光學物理,但在重建與渲染階段容易產生雜訊與破圖;生成式模型(generative models,例如 DiffusionRenderer)能產出逼真影像,卻難以精準控制光源,例如車燈這類局部照明往往被忽略。BRDFusion 正是針對這個 trade-off 而設計的混合框架。
這個項目屬於研究型框架,目標是把多視角城市影片分解為幾何(法線、深度)、材質(albedo、roughness、metallic)與 HDR 環境光源,並支援新視角重照明、夜景模擬與動態物件插入等下游應用。具體做法上,它先用物理模型取得明確且一致的場景屬性,再借助生成式先驗(generative priors)緩解優化過程中的歧義;前向渲染時,物理模型負責可控渲染,生成模型則負責去噪與修補瑕疵。
測試方面,作者提供預處理資料集與預訓練權重,研究人員可直接下載並透過 tools/run_pipeline.py 跑推理與評估;硬體需求偏高,建議使用 NVIDIA RTX A6000,RTX 4090 在記憶體允許下可執行部分階段,但 Gen. Render 階段可能突破 24 GB 限制。資料集與評估影片亦同步發佈於 Hugging Face,方便重現結果。
這個項目的創新之處在於把「物理一致性」與「生成式品質」放在同一條管線中互補,而非二選一。對從事自動駕駛模擬、遊戲或影視場景重建的研究團隊而言,這是一個值得關注的方向。
重點摘要
- 混合範式:物理渲染負責可控性,生成模型負責修補瑕疵,突破單一方法的極限。
- 完整分解:輸出幾何、材質與 HDR 光源,支援新視角、夜景與物件插入。
- 高硬體需求:建議 RTX A6000,4090 僅能跑部分階段。
- 完整開源資源:程式碼、預訓練權重、資料集與評估影片均已公開。
- 適用場景:自動駕駛模擬、城市數位孿生、影視級場景編輯。