圖像圖層分解(image layer decomposition)是指把一張圖分成幾層可獨立編輯的 RGBA 影像,再合併回原本的畫面。這個技術是專業修圖與合成工作流的基本工序,但要訓練模型做這件事並不容易:同一張圖往往存在多種合理分層方式,而且品質好壞取決於下游是否好用,例如語意分層是否清晰、alpha 遮罩是否乾淨、是否有冗餘層,以及被遮擋的部分能否被合理填回。
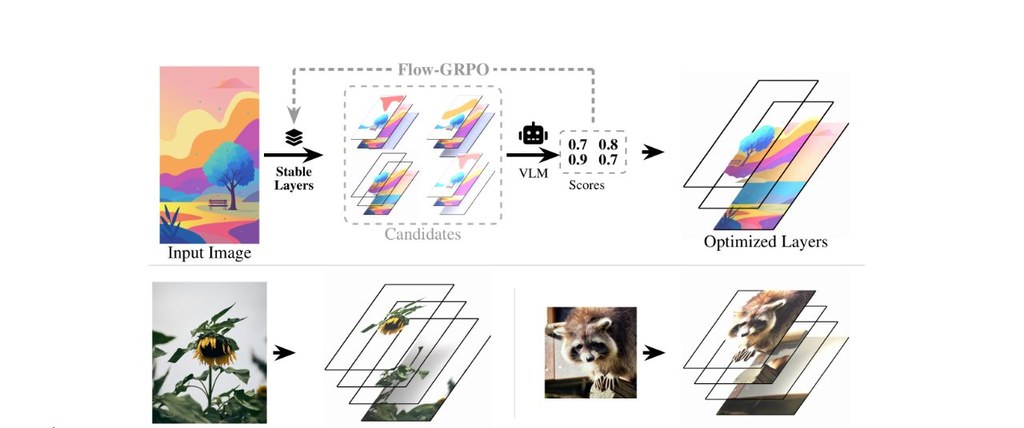
傳統做法會用合成的配對數據集(即同一張圖同時提供「原圖」與「正確分層」)來監督模型學習,但這會帶來先天限制:當多種分層都同樣合理時,強迫模型擬合單一標準答案,等於懲罰了其他可行的解法。Stable-Layers 嘗試繞過這個限制,改用強化學習(reinforcement learning)讓模型直接朝「看起來品質好」的方向優化,監督訊號只來自一個視覺語言模型(vision-language model,VLM)。
具體而言,項目以 Qwen-Image-Layered 為起點,結合 Flow-GRPO 與 LoRA(Low-Rank Adaptation,低秩適應)微調,針對每張圖採樣多個候選分層,再用 VLM 評分,從群組相對優勢(group-relative advantages)來更新策略。當中最大的挑戰是設計可靠的獎勵訊號:VLM 單獨評分時容易把所有樣本擠進一個狹窄的分數區間,導致 GRPO 缺乏組內變化可以學習。為此,Stable-Layers 採用兩階段評估流程——先按五個編輯向標準逐項評分,再把所有候選並排放在標記好的比較網格上重新評分一次,藉此取得更細緻的相對校準。
Stable-Layers 重點摘要:
- 毋須配對數據:在完全沒有標註的圖像上訓練,解決合成數據集帶來的偏誤問題
- VLM 擔任評審:利用視覺語言模型就五個編輯標準打分,提供獎勵訊號
- 兩階段評估:先獨立評分,再以比較網格重新校準,避免分數過度集中
- 強化學習微調:結合 Flow-GRPO 與 LoRA,從 Qwen-Image-Layered 開始改良
- 實測表現:在 Crello 數據集上,圖層分離度更高、空白或帶瑕疵的層更少、每層重建誤差也較低
適用場景與對象:這個項目適合做圖像編輯、合成或設計工具的研究者與工程師,尤其是手上沒有大量配對分層數據、又想提升分層品質的團隊。對強化學習應用於視覺生成感興趣的人,也能從它處理「組內變化不足」的設計中得到啟發。
效能與評估:團隊在 Crello 數據集上測試,結果顯示 Stable-Layers 相比基礎模型,圖層分離更明確、出現空白或帶雜訊的層更少,而且每層的重建誤差也更低。論文獲 NeurIPS 2026 接收(arXiv:2605.30257v1)。
引用的模型:Qwen-Image-Layered(基礎分層模型)、Flow-GRPO(強化學習算法)、LoRA(高效微調方法)、視覺語言模型評審。