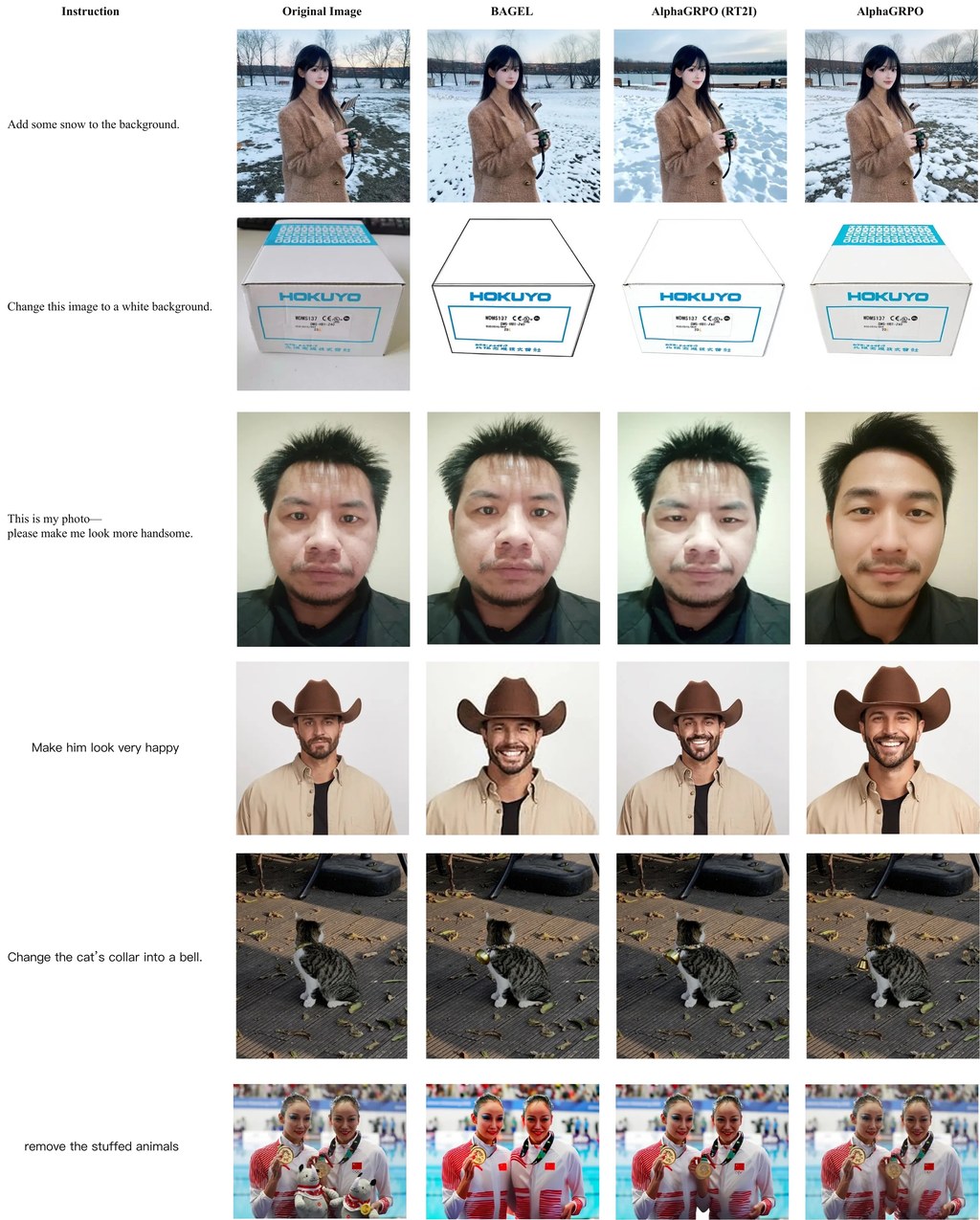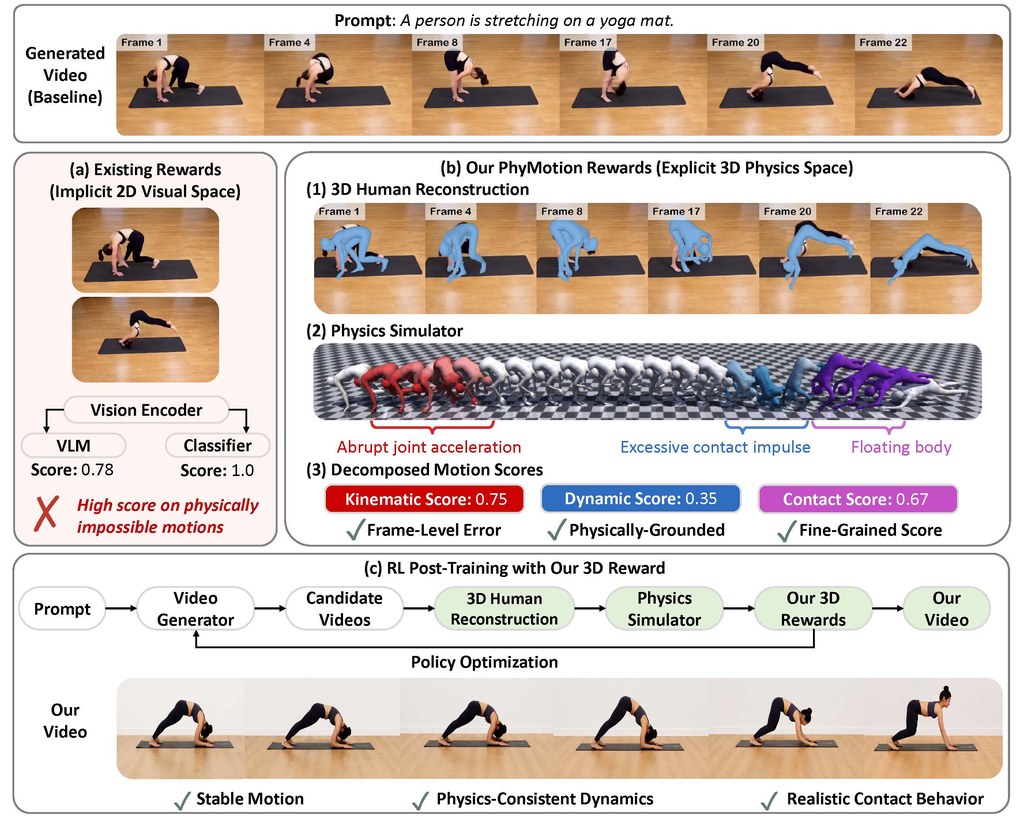
做人物影片生成,最難往往不是畫面靚唔靚,而係人郁動時有冇「似真」。PhyMotion針對的正是這個痛點:它提供一套較細緻的評分方法,專門檢查生成影片中的人體動作是否合理,例如會否出現腳步飄浮、失去平衡,或者動作雖然順眼但其實不合物理常識。
它的做法幾有意思。團隊先從影片還原出3D人體網格,使用SMPL表示身體,再把動作轉到MuJoCo的人形物理模擬環境內,從三方面評估:關節運動是否自然、接觸與平衡是否一致、以及整體動態是否可行。比起只靠2D畫面觀感打分,這種方法更能指出問題究竟出在哪一層。
如果你想上手,較合理的方式不是把它當成一般剪片工具,而是當成研究或訓練流程中的「動作評審」。儲存庫提供有 PhyMotion-CausalForcing-1.3B 相關權重與 LoRA 形式檢查點,較適合已經在做人像影片生成、後訓練或獎勵設計的人逐步接入。
- 重點不在直接生成影片,而在替影片中的人體動作評分
- 結合 SMPL 與 MuJoCo,比純2D評估更重視身體結構與物理性
- 適用於自回歸與雙向類型的影片生成訓練流程
- 相關資源包括論文、模型、資料集,以及 PhyMotion-CausalForcing-1.3B
整體來看,PhyMotion最有價值的地方,是把「睇落順眼」進一步拆成可分析的幾個部分,令改進方向更清楚。它特別適合研究員、AI 影片開發者,或者想提升人物動作真實感的團隊;對一般用家來說,未必是即裝即用,但作為理解下一代人物影片質素點樣提升,這個項目相當值得留意。