這篇論文介紹 LaRA(Layer-wise Representation Analysis),目的是找出 Reinforcement learning(RL)post-training 階段的資料污染問題。所謂污染,是指評估題目或基準資料混入訓練資料,令 Large Language Models(LLMs)看似表現很好,但其實可能只是記住答案,影響泛化能力與評估可信度。
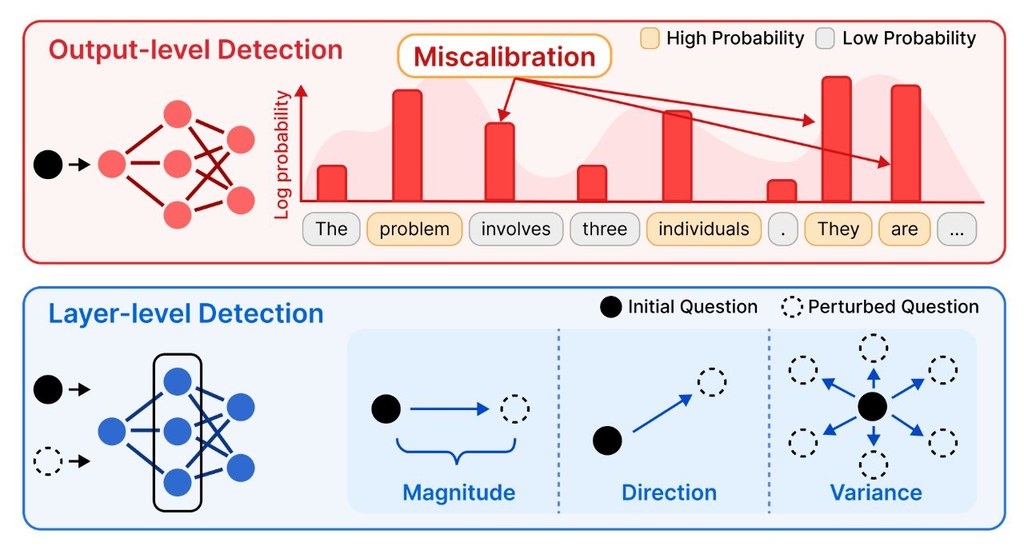
作者指出,現有方法多數只看輸出層面的訊號,例如 likelihood、entropy 或生成行為差異,但這類方法對 RL 訓練後的模型未必穩定。原因是 RL 重點在整條 reasoning trajectory 的 reward,而不是逐個 token 的機率,因此只靠輸出分佈,容易受 miscalibration 影響,未必能準確反映模型是否記住了評測資料。
LaRA 改為分析模型各層的內部表示,觀察受控擾動前後的幾何變化。論文提出三個互補指標:perturbation sensitivity、directional collapse、local representation rigidity,用來量度污染樣本在不同 layer 的異常反應;作者發現,受污染資料會在多層表示中逐步出現更高敏感度、更強方向收縮,以及更高局部剛性。
使用這個項目時,重點不是增加推理速度,而是作為檢測流程,協助研究人員審視 RL 訓練後模型的可信度。文中也提出一套偵測 protocol,把不同 layer 與不同指標的偏差整合起來;在 RL-trained reasoning models 的實驗中,這套方法表現優於現有 output-level baseline。
- 解決 RL post-training 資料污染難以辨識的問題
- 以 representation-level 訊號取代單看輸出機率
- 結合三個指標,從多層 layer 分析污染痕跡
- 適合用於 reasoning 模型評估、訓練審核與研究比較
- 論文摘要未提供 VRAM 需求,較可能受模型大小、抽取 layer 數目與批次分析設定影響
如果你關心 VRAM 的應用,這篇內容沒有列出明確顯示卡記憶體需求,也沒有提供部署規格。不過按方法性質推測,LaRA 需要讀取多個 layer 的 hidden representations,使用時 VRAM 主要會花在模型載入、儲存中間層表示,以及對多個擾動版本做批次分析;模型越大、分析層數越多,VRAM 需求通常越高。